

一 简介
在使用Python 开发MySQL自动化相关的运维工具的时候,遇到一些有意思的问题,本文介绍Python的 subprocess 模块以及如何和MySQL交互具体操作,如启动 ,关闭 ,备份数据库。
二 基础知识
Python2.4引入 subprocess模块来管理子进程,可以像Linux 系统中执行shell命令那样fork一个子进程执行外部的命令,并且可以连接子进程的output/input/error管道,获取命令执行的输出,错误信息,和执行成功与否的结果。
Subprocess 提供了三个函数以不同的方式创建子进程。他们分别是
subprocess.call()
父进程等待子进程完成,并且返回子进程执行的结果 0/1
其实现方式
例子
subprocess.check_call()
父进程等待子进程完成,正常情况下返回0,当检查退出信息,如果returncode不为0,则触发异常
subprocess.CalledProcessError,该对象包含有returncode属性,应用程序中可用try...except...来检查命令是否执行成功。
其实现方式
例子
subprocess.check_output()
和 subprocess.check_call() 类似,但是其返回的结果是执行命令的输出,而非返回0/1
其实现方式
例子
通过上面三个例子,我们可以看出前面两个函数不容易控制输出内容,在使用subprocess包中的函数创建子进程执行命令的时候,需要考虑
1) 在创建子进程之后,父进程是否暂停,并等待子进程运行。
2) 如何处理函数返回的信息(命令执行的结果或者错误信息)
3) 当子进程执行的失败也即returncode不为0时,父进程如何处理后续流程?
三 subprocess的核心类 Popen()
认真的读者朋友可以看出上面三个函数都是基于Popen实现的,为啥呢?因为 subprocess 仅仅提供了一个类,call(),check_call(),check_outpu()都是基于Popen封装而成。当我们需要更加自主的应用subprocess来实现应用程序的功能时,
我们要自己动手直接使用Popen()生成的对象完成任务。接下来我们研究Popen()的常见用法 ,详细的用法请参考 官方文档
Popen(args, bufsize=0, executable=None, stdin=None, stdout=None, stderr=None, preexec_fn=None, close_fds=False, shell=False, cwd=None, env=None, universal_newlines=False, startupinfo=None, creationflags=0)
这里我们只要掌握常用的参数即可
args 字符串或者列表,比如 "ls -a" / ["ls","-a"]
stdin/stdout/stderr 为None时表示没有任何重定向,继承父进程,还可以设置为PIPE 创建管道/文件对象/文件描述符(整数)/stderr 还可以设置为 STDOUT 后面会给出常见的用法
shell 是否使用shell来执行程序。当shell=True, 它将args看作是一个字符串,而不是一个序列。在Unix系统,且 shell=True时,shell默认使用 /bin/sh.
如果 args是一个字符串,则它声明了通过shell执行的命令。这意味着,字符串必须要使用正确的格式。
如果 args是一个序列,则第一个元素就是命令字符串,而其它的元素都作为参数使用。可以这样说,Popen等价于:
Popen(['/bin/sh', '-c', args[0], args[1], ...])
与上面第二部分介绍的三个函数不同,subprocess.Popen() fork子进程之后主进程不会等待子进程结束,而是直接执行后续的命令。当我们需要等待子进程结束必须使用wait()或者communicate()函数。举个例子,
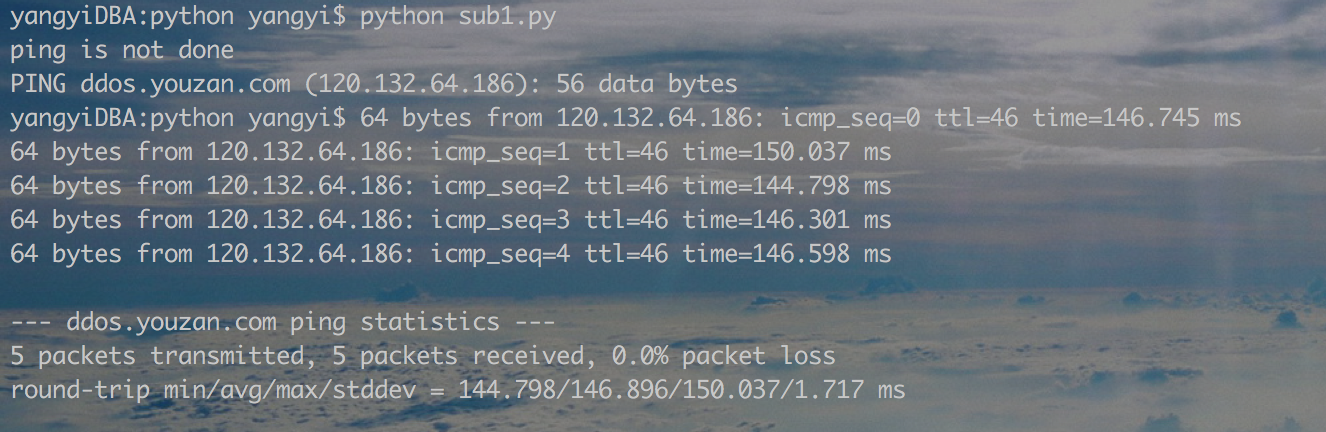
从执行结果上看,子进程 ping命令并未执行完毕,subprocess.Popen()后面的命令就开始执行了。
Popen常见的函数
Popen.poll() 用于检查子进程是否已经结束,设置并返回returncode属性。
Popen.wait() 等待子进程结束,设置并返回returncode属性。
Popen.communicate(input=None) 与子进程进行交互。向stdin发送数据,或从stdout和stderr中读取数据。可选参数input指定发送到子进程的参数。 Communicate()返回一个元组:(stdoutdata, stderrdata)。注意:如果希望通过进程的stdin向其发送数据,在创建Popen对象的时候,参数stdin必须被设置为PIPE。同样,如果希望从stdout和stderr获取数据,必须将stdout和stderr设置为PIPE。需要注意的是 communicate()是Popen对象的一个方法,该方法会阻塞父进程,直到子进程完成。
Popen.send_signal(signal) 向子进程发送信号。
Popen.terminate() 终止子进程。
Popen.kill() 杀死子进程。
Popen.pid 获取子进程的进程ID。
Popen.returncode 获取进程的返回值, 成功时,返回0/失败时,返回 1。如果进程还没有结束,返回None。
这里需要多做说明的是
对于 wait() 官方提示
即当stdout/stdin设置为PIPE时,使用wait()可能会导致死锁。因而建议使用communicate
而对于communicate,文档又给出:
communicate会把数据读入内存缓存下来,所以当数据很大或者是无限的数据时不要使用。
那么坑爹的问题来了:当你要使用Python的subprocess.Popen实现命令行之间的管道传输,同时数据源又非常大(比如读取上GB的文本或者无尽的网络流)时,官方文档不建议用wait,同时communicate还可能把内存撑爆,我们该怎么操作?
四 Subprocess 和MySQL 的交互
纸上来得终觉浅,绝知此事要躬行。自动化运维需求中会有重启/关闭/备份/恢复 MySQL的需求。怎么使用Python的subprocess来解决呢?启动MySQL的命令如下
实际上使用child=subprocess.Popen(startMySQL,shell=True,stdout=stdout=subprocess.PIPE),子进程mysql_safe是无任何返回输出的,使用,child.communicate()或者读取stdout 则会持续等待。
需要使用 child.wait()或者child.poll()检查子进程是否执行完成。
五 参考资料
[1] 官方文档
[2] Python中的subprocess与Pipe
[3] python类库31[进程subprocess]
在使用Python 开发MySQL自动化相关的运维工具的时候,遇到一些有意思的问题,本文介绍Python的 subprocess 模块以及如何和MySQL交互具体操作,如启动 ,关闭 ,备份数据库。
二 基础知识
Python2.4引入 subprocess模块来管理子进程,可以像Linux 系统中执行shell命令那样fork一个子进程执行外部的命令,并且可以连接子进程的output/input/error管道,获取命令执行的输出,错误信息,和执行成功与否的结果。
Subprocess 提供了三个函数以不同的方式创建子进程。他们分别是
subprocess.call()
父进程等待子进程完成,并且返回子进程执行的结果 0/1
其实现方式
- def call(*popenargs, **kwargs):
- return Popen(*popenargs, **kwargs).wait()
- >>> out=subprocess.call(["ls", "-l"])
- total 88
- drwxr-xr-x 5 yangyi staff 170 1 25 22:37 HelloWorld
- drwxr-xr-x 11 yangyi staff 374 12 18 2015 app
- -rw-r--r-- 1 yangyi staff 3895 4 19 11:29 check_int.py
- ..... 省略一部分
- >>> print out
- 0
- >>> out=subprocess.call(["ls", "-I"])
- ls: illegal option -- I
- usage: ls [-ABCFGHLOPRSTUWabcdefghiklmnopqrstuwx1] [file ...]
- >>> print out
- 1
父进程等待子进程完成,正常情况下返回0,当检查退出信息,如果returncode不为0,则触发异常
subprocess.CalledProcessError,该对象包含有returncode属性,应用程序中可用try...except...来检查命令是否执行成功。
其实现方式
- def check_call(*popenargs, **kwargs):
- retcode = call(*popenargs, **kwargs)
- if retcode:
- cmd = kwargs.get("args")
- raise CalledProcessError(retcode, cmd)
- return 0
- >>> out=subprocess.check_call(["ls"])
- HelloWorld check_int.py enumerate.py hello.py
- >>> print out
- 0
- >>> out=subprocess.check_call(["ls",'-I']) #执行命令失败的时候回抛出CalledProcessError异常,并且返回结果1
- ls: illegal option -- I
- usage: ls [-ABCFGHLOPRSTUWabcdefghiklmnopqrstuwx1] [file ...]
- Traceback (most recent call last):
- File "", line 1, in <module>
- File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/subprocess.py", line 540, in check_call
- raise CalledProcessError(retcode, cmd)
- subprocess.CalledProcessError: Command '['ls', '-I']' returned non-zero exit status 1
和 subprocess.check_call() 类似,但是其返回的结果是执行命令的输出,而非返回0/1
其实现方式
- def check_output(*popenargs, **kwargs):
- process = Popen(*popenargs, stdout=PIPE, **kwargs)
- output, unused_err = process.communicate()
- retcode = process.poll()
- if retcode:
- cmd = kwargs.get("args")
- raise CalledProcessError(retcode, cmd, output=output)
- return output
- >>> out=subprocess.check_output(["ls"]) #成功执行命令
- >>> print out
- HelloWorld
- check_int.py
- enumerate.py
- flasky
- hello.py
- >>> out=subprocess.check_output(["ls","-I"])#执行命令出现异常直接打印出异常信息。
- ls: illegal option -- I
- usage: ls [-ABCFGHLOPRSTUWabcdefghiklmnopqrstuwx1] [file ...]
- Traceback (most recent call last):
- File "", line 1, in <module>
- File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/subprocess.py", line 573, in check_output
- raise CalledProcessError(retcode, cmd, output=output)
- subprocess.CalledProcessError: Command '['ls', '-I']' returned non-zero exit status 1
- >>>
1) 在创建子进程之后,父进程是否暂停,并等待子进程运行。
2) 如何处理函数返回的信息(命令执行的结果或者错误信息)
3) 当子进程执行的失败也即returncode不为0时,父进程如何处理后续流程?
三 subprocess的核心类 Popen()
认真的读者朋友可以看出上面三个函数都是基于Popen实现的,为啥呢?因为 subprocess 仅仅提供了一个类,call(),check_call(),check_outpu()都是基于Popen封装而成。当我们需要更加自主的应用subprocess来实现应用程序的功能时,
我们要自己动手直接使用Popen()生成的对象完成任务。接下来我们研究Popen()的常见用法 ,详细的用法请参考 官方文档
Popen(args, bufsize=0, executable=None, stdin=None, stdout=None, stderr=None, preexec_fn=None, close_fds=False, shell=False, cwd=None, env=None, universal_newlines=False, startupinfo=None, creationflags=0)
这里我们只要掌握常用的参数即可
args 字符串或者列表,比如 "ls -a" / ["ls","-a"]
stdin/stdout/stderr 为None时表示没有任何重定向,继承父进程,还可以设置为PIPE 创建管道/文件对象/文件描述符(整数)/stderr 还可以设置为 STDOUT 后面会给出常见的用法
shell 是否使用shell来执行程序。当shell=True, 它将args看作是一个字符串,而不是一个序列。在Unix系统,且 shell=True时,shell默认使用 /bin/sh.
如果 args是一个字符串,则它声明了通过shell执行的命令。这意味着,字符串必须要使用正确的格式。
如果 args是一个序列,则第一个元素就是命令字符串,而其它的元素都作为参数使用。可以这样说,Popen等价于:
Popen(['/bin/sh', '-c', args[0], args[1], ...])
与上面第二部分介绍的三个函数不同,subprocess.Popen() fork子进程之后主进程不会等待子进程结束,而是直接执行后续的命令。当我们需要等待子进程结束必须使用wait()或者communicate()函数。举个例子,
- import subprocess
- sbp=subprocess.Popen(["ping","-c","5","www.youzan.com"])
- print "ping is not done"
从执行结果上看,子进程 ping命令并未执行完毕,subprocess.Popen()后面的命令就开始执行了。
Popen常见的函数
Popen.poll() 用于检查子进程是否已经结束,设置并返回returncode属性。
Popen.wait() 等待子进程结束,设置并返回returncode属性。
Popen.communicate(input=None) 与子进程进行交互。向stdin发送数据,或从stdout和stderr中读取数据。可选参数input指定发送到子进程的参数。 Communicate()返回一个元组:(stdoutdata, stderrdata)。注意:如果希望通过进程的stdin向其发送数据,在创建Popen对象的时候,参数stdin必须被设置为PIPE。同样,如果希望从stdout和stderr获取数据,必须将stdout和stderr设置为PIPE。需要注意的是 communicate()是Popen对象的一个方法,该方法会阻塞父进程,直到子进程完成。
Popen.send_signal(signal) 向子进程发送信号。
Popen.terminate() 终止子进程。
Popen.kill() 杀死子进程。
Popen.pid 获取子进程的进程ID。
Popen.returncode 获取进程的返回值, 成功时,返回0/失败时,返回 1。如果进程还没有结束,返回None。
这里需要多做说明的是
对于 wait() 官方提示
- Warning This will deadlock when using stdout=PIPE and/or stderr=PIPE and the child process generates enough output to a pipe such that it blocks waiting for the OS pipe buffer to accept more data. Use communicate() to avoid that.
而对于communicate,文档又给出:
- Interact with process: Send data to stdin. Read data from stdout and stderr, until end-of-file is reached. Wait for process to terminate. The optionalinput argument should be a string to be sent to the child process, orNone, if no data should be sent to the child.communicate() returns a tuple (stdoutdata, stderrdata).
- Note that if you want to send data to the process’s stdin, you need to create the Popen object with stdin=PIPE. Similarly, to get anything other thanNone in the result tuple, you need to give stdout=PIPE and/orstderr=PIPE too.
- Note
- The data read is buffered in memory, so do not use this method if the data size is large or unlimited.
那么坑爹的问题来了:当你要使用Python的subprocess.Popen实现命令行之间的管道传输,同时数据源又非常大(比如读取上GB的文本或者无尽的网络流)时,官方文档不建议用wait,同时communicate还可能把内存撑爆,我们该怎么操作?
四 Subprocess 和MySQL 的交互
纸上来得终觉浅,绝知此事要躬行。自动化运维需求中会有重启/关闭/备份/恢复 MySQL的需求。怎么使用Python的subprocess来解决呢?启动MySQL的命令如下
- startMySQL="/usr/bin/mysqld_safe --defaults-file=/srv/my{0}/my.cnf --read_only=1 & ".format(port)
需要使用 child.wait()或者child.poll()检查子进程是否执行完成。
- import subprocess,time
- def startMySQL(port):
- startMySQL="/usr/bin/mysqld_safe --defaults-file=/srv/my{0}/my.cnf --read_only=1 & ".format(port)
- child=subprocess.Popen(startMySQL, shell=True,stdout=subprocess.PIPE)
- child.poll()
- time.sleep(3) #有些MySQL实例启动可能需要一定的时间
- if child.returncode:
- print "instance {0} startup failed ...".format(port)
- else:
- print "instance {0} startup successed ...".format(port)
- return
- root@rac3:~/python# >python 1.py
- instance 3308 startup successed ...
[1] 官方文档
[2] Python中的subprocess与Pipe
[3] python类库31[进程subprocess]




