背景
我们在使用PostgreSQL的时候,可能会碰到表膨胀的问题(关于表膨胀可以参考之前的月报),即表的数据量并不大,但是占用的磁盘空间比较大,查询比较慢。为什么PostgreSQL有可能发生表膨胀呢?这是因为PostgreSQL引入了MVCC机制来保证事务的隔离性,实现数据库的隔离级别。
在数据库中,并发的数据库操作会面临脏读(Dirty Read)、不可重复读(Nonrepeatable Read)、幻读(Phantom Read)和串行化异常等问题,为了解决这些问题,在标准的SQL规范中对应定义了四种事务隔离级别:
- RU(Read uncommitted):读未提交
- RC(Read committed):读已提交
- RR(Repeatable read):重复读
- SERIALIZABLE(Serializable):串行化
当前PostgreSQL已经支持了这四种标准的事务隔离级别(可以使用SET TRANSACTION语句来设置,详见文档),下表是PostgreSQL官方文档上列举的四种事务隔离级别和对应数据库问题的关系:
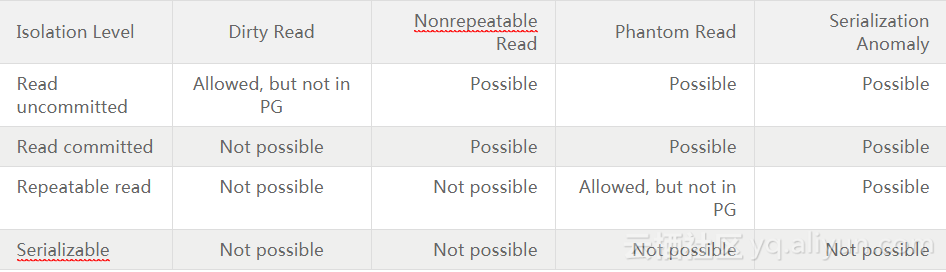
需要注意的是,在PostgreSQL中:
- RU隔离级别不允许脏读,实际上和Read committed一样
- RR隔离级别不允许幻读
在PostgreSQL中,为了保证事务的隔离性,实现数据库的隔离级别,引入了MVCC(Multi-Version Concurrency Control)多版本并发控制。
MVCC常用实现方法
一般MVCC有2种实现方法:
- 写新数据时,把旧数据转移到一个单独的地方,如回滚段中,其他人读数据时,从回滚段中把旧的数据读出来,如Oracle数据库和MySQL中的innodb引擎。
- 写新数据时,旧数据不删除,而是把新数据插入。PostgreSQL就是使用的这种实现方法。
两种方法各有利弊,相对于第一种来说,PostgreSQL的MVCC实现方式优缺点如下:
- 优点
- 无论事务进行了多少操作,事务回滚可以立即完成
- 数据可以进行很多更新,不必像Oracle和MySQL的Innodb引擎那样需要经常保证回滚段不会被用完,也不会像oracle数据库那样经常遇到“ORA-1555”错误的困扰
- 缺点
- 旧版本的数据需要清理。当然,PostgreSQL 9.x版本中已经增加了自动清理的辅助进程来定期清理
- 旧版本的数据可能会导致查询需要扫描的数据块增多,从而导致查询变慢
PostgreSQL中MVCC的具体实现
为了实现MVCC机制,必须要:
- 定义多版本的数据。在PostgreSQL中,使用元组头部信息的字段来标示元组的版本号
- 定义数据的有效性、可见性、可更新性。在PostgreSQL中,通过当前的事务快照和对应元组的版本号来判断该元组的有效性、可见性、可更新性
- 实现不同的数据库隔离级别
接下来,我们会按照上面的顺序,首先介绍多版本元组的存储结构,再介绍事务快照、数据可见性的判断以及数据库隔离级别的实现。
多版本元组存储结构
为了定义MVCC 中不同版本的数据,PostgreSQL在每个元组的头部信息HeapTupleHeaderData中引入了一些字段如下:
struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; /* current TID of this or newer tuple (or a
* speculative insertion token) */ /* Fields below here must match MinimalTupleData! */
uint16 t_infomask2; /* number of attributes + various flags */
uint16 t_infomask; /* various flag bits, see below */
uint8 t_hoff; /* sizeof header incl. bitmap, padding */ /* ^ - 23 bytes - ^ */
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* bitmap of NULLs */ /* MORE DATA FOLLOWS AT END OF STRUCT */
};
其中:
- t_heap存储该元组的一些描述信息,下面会具体去分析其字段
- t_ctid存储用来记录当前元组或新元组的物理位置
- 由块号和块内偏移组成
- 如果这个元组被更新,则该字段指向更新后的新元组
- 这个字段指向自己,且后面t_heap中的xmax字段为空,就说明该元组为最新版本
- t_infomask存储元组的xmin和xmax事务状态,以下是t_infomask每位分别代表的含义:
#define HEAP_HASNULL 0x0001 /* has null attribute(s) */ #define HEAP_HASVARWIDTH 0x0002 /* has variable-width attribute(s) 有可变参数 */ #define HEAP_HASEXTERNAL 0x0004 /* has external stored attribute(s) */ #define HEAP_HASOID 0x0008 /* has an object-id field */ #define HEAP_XMAX_KEYSHR_LOCK 0x0010 /* xmax is a key-shared locker */ #define HEAP_COMBOCID 0x0020 /* t_cid is a combo cid */ #define HEAP_XMAX_EXCL_LOCK 0x0040 /* xmax is exclusive locker */ #define HEAP_XMAX_LOCK_ONLY 0x0080 /* xmax, if valid, is only a locker */ /* xmax is a shared locker */ #define HEAP_XMAX_SHR_LOCK (HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK) #define HEAP_LOCK_MASK (HEAP_XMAX_SHR_LOCK | HEAP_XMAX_EXCL_LOCK | \
HEAP_XMAX_KEYSHR_LOCK) #define HEAP_XMIN_COMMITTED 0x0100 /* t_xmin committed 即xmin已经提交*/ #define HEAP_XMIN_INVALID 0x0200 /* t_xmin invalid/aborted */ #define HEAP_XMIN_FROZEN (HEAP_XMIN_COMMITTED|HEAP_XMIN_INVALID) #define HEAP_XMAX_COMMITTED 0x0400 /* t_xmax committed即xmax已经提交*/ #define HEAP_XMAX_INVALID 0x0800 /* t_xmax invalid/aborted */ #define HEAP_XMAX_IS_MULTI 0x1000 /* t_xmax is a MultiXactId */ #define HEAP_UPDATED 0x2000 /* this is UPDATEd version of row */ #define HEAP_MOVED_OFF 0x4000 /* moved to another place by pre-9.0 * VACUUM FULL; kept for binary * upgrade support */ #define HEAP_MOVED_IN 0x8000 /* moved from another place by pre-9.0 * VACUUM FULL; kept for binary * upgrade support */ #define HEAP_MOVED (HEAP_MOVED_OFF | HEAP_MOVED_IN) #define HEAP_XACT_MASK 0xFFF0 /* visibility-related bits */ 上文HeapTupleHeaderData中的t_heap存储着元组的一些描述信息,结构如下:
typedef struct HeapTupleFields
{
TransactionId t_xmin; /* inserting xact ID */
TransactionId t_xmax; /* deleting or locking xact ID */ union
{
CommandId t_cid; /* inserting or deleting command ID, or both */
TransactionId t_xvac; /* VACUUM FULL xact ID */
} t_field3;
} HeapTupleFields;
其中:
- t_xmin 存储的是产生这个元组的事务ID,可能是insert或者update语句
- t_xmax 存储的是删除或者锁定这个元组的事务ID
- t_cid 包含cmin和cmax两个字段,分别存储创建这个元组的Command ID和删除这个元组的Command ID
- t_xvac 存储的是VACUUM FULL 命令的事务ID
这里需要简单介绍下PostgreSQL中的事务ID:
- 由32位组成,这就有可能造成事务ID回卷的问题,具体参考文档
- 顺序产生,依次递增
- 没有数据变更,如INSERT、UPDATE、DELETE等操作,在当前会话中,事务ID不会改变
PostgreSQL主要就是通过t_xmin,t_xmax,cmin和cmax,ctid,t_infomask来唯一定义一个元组(t_xmin,t_xmax,cmin和cmax,ctid实际上也是一个表的隐藏的标记字段),下面以一个例子来表示元组更新前后各个字段的变化。
- 创建表test,插入数据,并查询t_xmin,t_xmax,cmin和cmax,ctid属性
postgres=# create table test(id int); CREATE TABLE
postgres=# insert into test values(1); INSERT 0 1
postgres=# select ctid, xmin, xmax, cmin, cmax,id from test;
ctid | xmin | xmax | cmin | cmax | id
-------+------+------+------+------+----
(0,1) | 1834 | 0 | 0 | 0 | 1
(1 row)
- 更新test,并查询t_xmin,t_xmax,cmin和cmax,ctid属性
postgres=# update test set id=2; UPDATE 1
postgres=# select ctid, xmin, xmax, cmin, cmax,id from test;
ctid | xmin | xmax | cmin | cmax | id
-------+------+------+------+------+----
(0,2) | 1835 | 0 | 0 | 0 | 2
(1 row)
- 使用heap_page_items 方法查看test表对应page header中的内容
postgres=# select * from heap_page_items(get_raw_page('test',0));
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------
1 | 8160 | 1 | 28 | 1834 | 1835 | 0 | (0,2) | 16385 | 1280 | 24 | |
2 | 8128 | 1 | 28 | 1835 | 0 | 0 | (0,2) | 32769 | 10496 | 24 | |
从上面可知,实际上数据库存储了更新前后的两个元组,这个过程中的数据块中的变化大体如下:

Tuple1更新后会插入一个新的Tuple2,而Tuple1中的ctid指向了新的版本,同时Tuple1的xmax从0变为1835,这里可以被认为被标记为过期(只有xmax为0的元组才没过期),等待PostgreSQL的自动清理辅助进程回收掉。
也就是说,PostgreSQL通过HeapTupleHeaderData 的几个特殊的字段,给元组设置了不同的版本号,元组的每次更新操作都会产生一条新版本的元组,版本之间从旧到新形成了一条版本链(旧的ctid指向新的元组)。
不过这里需要注意的是,更新操作可能会使表的每个索引也产生新版本的索引记录,即对一条元组的每个版本都有对应版本的索引记录。这样带来的问题就是浪费了存储空间,旧版本占用的空间只有在进行VACCUM时才能被回收,增加了数据库的负担。
为了减缓更新索引带来的影响,8.3之后开始使用HOT机制。定义符合下面条件的为HOT元组:
- 索引属性没有被修改
- 更新的元组新旧版本在同一个page中,其中新的被称为HOT元组
更新一条HOT元组不需要引入新版本的索引,当通过索引获取元组时首先会找到最旧的元组,然后通过元组的版本链找到HOT元组。这样HOT机制让拥有相同索引键值的不同版本元组共用一个索引记录,减少了索引的不必要更新。
事务快照的实现
为了实现元组对事务的可见性判断,PostgreSQL引入了事务快照SnapshotData,其具体数据结构如下:
typedef struct SnapshotData
{
SnapshotSatisfiesFunc satisfies; /* tuple test function */
TransactionId xmin; /* all XID < xmin are visible to me */
TransactionId xmax; /* all XID >= xmax are invisible to me */
TransactionId *xip; //所有正在运行的事务的id列表
uint32 xcnt; /* # of xact ids in xip[],正在运行的事务的计数 */
TransactionId *subxip; //进程中子事务的ID列表
int32 subxcnt; /* # of xact ids in subxip[],进程中子事务的计数 */ bool suboverflowed; /* has the subxip array overflowed? */ bool takenDuringRecovery; /* recovery-shaped snapshot? */ bool copied; /* false if it's a static snapshot */
CommandId curcid; /* in my xact, CID < curcid are visible */
uint32 speculativeToken;
uint32 active_count; /* refcount on ActiveSnapshot stack,在活动快照链表里的
*引用计数 */
uint32 regd_count; /* refcount on RegisteredSnapshots,在已注册的快照链表
*里的引用计数 */
pairingheap_node ph_node; /* link in the RegisteredSnapshots heap */
TimestampTz whenTaken; /* timestamp when snapshot was taken */
XLogRecPtr lsn; /* position in the WAL stream when taken */
} SnapshotData;
这里注意区分SnapshotData的xmin,xmax和HeapTupleFields的t_xmin,t_xmax
事务快照是用来存储数据库的事务运行情况。一个事务快照的创建过程可以概括为:
- 查看当前所有的未提交并活跃的事务,存储在数组中
- 选取未提交并活跃的事务中最小的XID,记录在快照的xmin中
- 选取所有已提交事务中最大的XID,加1后记录在xmax中
- 根据不同的情况,赋值不同的satisfies,创建不同的事务快照
其中根据xmin和xmax的定义,事务和快照的可见性可以概括为:
- 当事务ID小于xmin的事务表示已经被提交,其涉及的修改对当前快照可见
- 事务ID大于或等于xmax的事务表示正在执行,其所做的修改对当前快照不可见
- 事务ID处在 [xmin, xmax)区间的事务, 需要结合活跃事务列表与事务提交日志CLOG,判断其所作的修改对当前快照是否可见,即SnapshotData中的satisfies。
satisfies是PostgreSQL提供的对于事务可见性判断的统一操作接口。目前在PostgreSQL 10.0中具体实现了以下几个函数:
- HeapTupleSatisfiesMVCC:判断元组对某一快照版本是否有效
- HeapTupleSatisfiesUpdate:判断元组是否可更新
- HeapTupleSatisfiesDirty:判断当前元组是否已脏
- HeapTupleSatisfiesSelf:判断tuple对自身信息是否有效
- HeapTupleSatisfiesToast:用于TOAST表(参考文档)的判断
- HeapTupleSatisfiesVacuum:用在VACUUM,判断某个元组是否对任何正在运行的事务可见,如果是,则该元组不能被VACUUM删除
- HeapTupleSatisfiesAny:所有元组都可见
- HeapTupleSatisfiesHistoricMVCC:用于CATALOG 表
上述几个函数的参数都是 (HeapTuple htup, Snapshot snapshot, Buffer buffer),其具体逻辑和判断条件,本文不展开具体讨论,有兴趣的可以参考《PostgreSQL数据库内核分析》的7.10.2 MVCC相关操作。
此外,为了对可用性判断的过程进行加速,PostgreSQL还引入了Visibility Map机制(详见文档)。Visibility Map标记了哪些page中是没有dead tuple的。这有两个好处:
- 当vacuum时,可以直接跳过这些page
- 进行index-only scan时,可以先检查下Visibility Map。这样减少fetch tuple时的可见性判断,从而减少IO操作,提高性能
另外visibility map相对整个relation,还是小很多,可以cache到内存中。
隔离级别的实现
PostgreSQL中根据获取快照时机的不同实现了不同的数据库隔离级别(对应代码中函数GetTransactionSnapshot):
- 读未提交/读已提交:每个query都会获取最新的快照CurrentSnapshotData
- 重复读:所有的query 获取相同的快照都为第1个query获取的快照FirstXactSnapshot
- 串行化:使用锁系统来实现
总结
为了保证事务的原子性和隔离性,实现不同的隔离级别,PostgreSQL引入了MVCC多版本机制,概括起就是:
- 通过元组的头部信息中的xmin,xmax以及t_infomask等信息来定义元组的版本
- 通过事务提交日志来判断当前数据库各个事务的运行状态
- 通过事务快照来记录当前数据库的事务总体状态
- 根据用户设置的隔离级别来判断获取事务快照的时间
如上文所讲,PostgreSQL的MVCC实现方法有利有弊。其中最直接的问题就是表膨胀,为了解决这个问题引入了AutoVacuum自动清理辅助进程,将MVCC带来的垃圾数据定期清理,这部分内容我们将在下期月报进行分析,敬请期待。
