Bloom filter 简介
Bloom filter用于判断一个元素是不是在一个集合里,当一个元素被加入集合时,通过k个散列函数将这个元素映射成一个位数组中的k个点,把它们置为1。检索时如果这些点有任何一个为0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。 优点:布隆过滤器存储空间和插入/查询时间都是常数O(k)。 缺点:有一定的误算率,同时标准的Bloom Filter不支持删除操作。 Bloom Filter通过极少的错误换取了存储空间的极大节省。

设集合元素个数为n,数组大小为m, 散列函数个数为k
有一个规律是当 k=m/n*ln2 时,误算率最低。参考Bloom_filter wiki
rocksdb与bloom filter
rocksdb中memtable和SST file都属于集合类数据且不需要删除数据,比较适合于Bloom filter.
rocksdb memtable和SST file都支持bloom filter, memtable 的bloom filter数组就存储在内存中,而SST file的bloom filter持久化在bloom filter中.
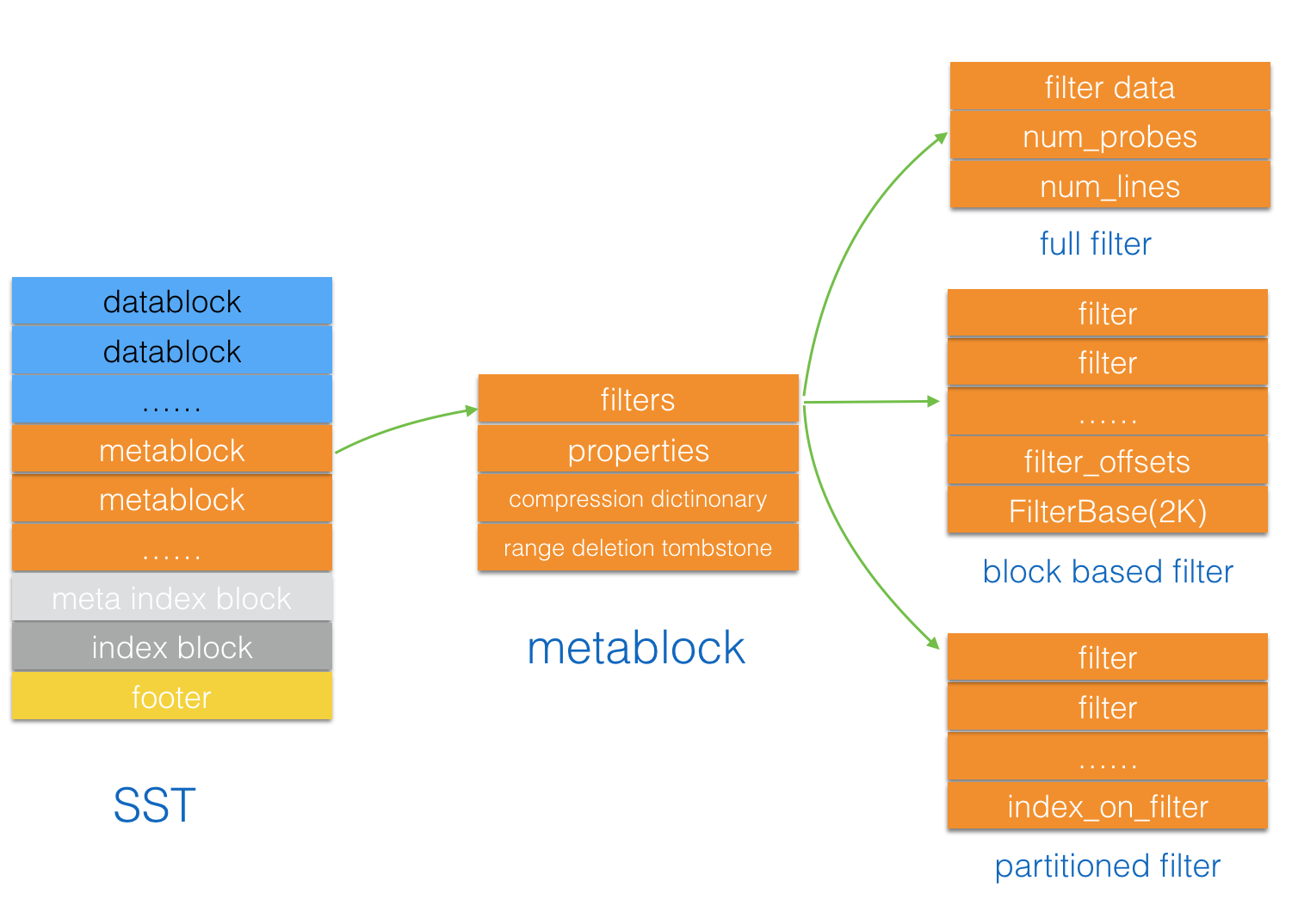
- SST Bloom filter
- 将prefix_extrator指定的key前缀加入到HASH表hash_entries_中
- 将hash_entries_所有映射到Bloom filter的数组中
SST Bloom filter相关参数有
filter_policy=bloomfilter:10:false; whole_key_filtering=0 prefix_extractor=capped:24 partition_filters=false 其中prefix_extractor=capped:24, 表示最多取前缀24个字节,另外还有fixed:n方式表示只取前缀n个字节,忽略小于n个字节的key. 具体可参考CappedPrefixTransform,FixedPrefixTransform
filter_policy=bloomfilter:10:false;其中bits_per_key_=10, bits_per_key_实际就是前面公式k=m/n*ln2 中的m/n. 从而如下计算k即num_probes_的方式
void initialize() {
// We intentionally round down to reduce probing cost a little bit
num_probes_ = static_cast<size_t>(bits_per_key_ * 0.69); // 0.69 =~ ln(2) if (num_probes_ < 1) num_probes_ = 1;
if (num_probes_ > 30) num_probes_ = 30;
}use_block_based_builder_表示是使用block base filter还是full filter partition_filters 表示时否使用partitioned filter,SST数据有序排列,按block_size进行分区后再产生filter,index_on_filter block存储分区范围. 开启partition_filters 需配置index_type =kTwoLevelIndexSearch
filter 参数优先级如下 block base > partitioned > full. 比如说同时指定use_block_based_builder_=true和partition_filters=true实际使用的block based filter
whole_key_filtering,取值true, 表示增加全key的filter. 它和前缀filter并不冲突可以共存。
rocksdb 内部 bloom filter实现方式有三种
block based filter,SST file每2kb作为一个block构建bloom filter信息。full filter. 整个SST file构建一个bloom filter信息。
partitioned filter, 将SST filter按block_size将进行分区, 每个分区构建bloom filter信息。分区是有序的,有最大值和最小值,从而在分区之上构建索引存储在SST block中。
- memtable Bloom filter
- memtable 在每次Add数据时都会更新Bloom filter.
- Bloom filter提供参数memtable_prefix_bloom_size_ratio,其值不超过0.25, Bloom filter数组大小为write_buffer_size* memtable_prefix_bloom_size_ratio.
- memtable Bloom filter 中的num_probes_取值硬编码为6
另外参数cache_index_and_filter_blocks可以让filter信息缓存在block cache中。
MyRocks和bloom filter
在myrocks中,Bloom filter是全局的,设置了Bloom filter后,所有表都有Bloom filter。Bloom filter和索引是绑定在一起的。也就是说,表在查询过程中,如果可以用到某个索引,且设置了Bloom filter,那么就有可能会用到索引的Bloom filter.
MyRocks可以使用Bloom filter的条件如下,详见函数can_use_bloom_filter
- 必须是索引前缀或索引全列的等值查询
- 等值前缀的长度应该符合prefix_extrator的约定
我们可以通过以下两个status变量来观察Bloom filter使用情况 rocksdb_bloom_filter_prefix_checked:是否使用了Bloom filter rocksdb_bloom_filter_prefix_useful:使用Bloom filter判断出不存在 rocksdb_bloom_filter_useful:BlockBasedTable::Get接口使用Bloom filter判断出不存在
设置参数rocksdb_skip_bloom_filter_on_read可以让查询不使用Bloom filter。
示例
最后给个示例 参数设置如下,使用partitioned filter
rocksdb_default_cf_options=write_buffer_size=64k;
block_based_table_factory={filter_policy=bloomfilter:10:false;whole_key_filtering=0;
partition_filters=true;index_type=kTwoLevelIndexSearch};prefix_extractor=capped:24 SQL
CREATE TABLE t1 (id1 INT, id2 VARCHAR(100), id3 BIGINT, value INT, PRIMARY KEY (id1, id2, id3)) ENGINE=rocksdb collate latin1_bin;
let $i = 1;
while ($i <= 10000) {
let $insert = INSERT INTO t1 VALUES($i, $i, $i, $i);
inc $i;
eval $insert;
}
## case 1: 等值条件prefix长度 < 24, 用不Bbloom filter select variable_value
into @c from information_schema.global_status where variable_name='rocksdb_bloom_filter_prefix_checked';
select variable_value into @u from information_schema.global_status where variable_name='rocksdb_bloom_filter_prefix_useful';
select count(*) from t1 WHERE id1=100 and id2 ='10';
count(*)
0 select (variable_value-@c) > 0 from information_schema.global_status where variable_name='rocksdb_bloom_filter_prefix_checked';
(variable_value-@c) > 0 0 select (variable_value-@u) > 0 from information_schema.global_status
where variable_name='rocksdb_bloom_filter_prefix_useful';
(variable_value-@u) > 0 0 # case 2: 符合使用Bbloom filter的条件,且成功判断出不存在
select variable_value into @c from information_schema.global_status where variable_name='rocksdb_bloom_filter_prefix_checked';
select variable_value into @u from information_schema.global_status where variable_name='rocksdb_bloom_filter_prefix_useful';
select count(*) from t1 WHERE id1=100 and id2 ='00000000000000000000';
count(*)
0 select (variable_value-@c) > 0 from information_schema.global_status where variable_name='rocksdb_bloom_filter_prefix_checked';
(variable_value-@c) > 0 1 select (variable_value-@u) > 0 from information_schema.global_status where variable_name='rocksdb_bloom_filter_prefix_useful';
(variable_value-@u) > 0 1



