写入流程
myrocks的写入流程可以简单的分为以下几步来完成
- 将解析后的记录(kTypeValue/kTypeDeletion)写入到WriteBatch中
- 将WAL日志写入log文件
- 将WriteBatch中的内容写到memtable中,事务完成
其中第2,3步在提交时完成
WriteBatch与Myrocks事务处理密切相关,事务中的记录提交前都以字符串的形式存储在WriteBatch->rep_中,要么都提交,要么都回滚。 回滚的逻辑比较简单,只需要清理WriteBatch->rep_即可。详见TransactionImpl::Rollback
一个简单的insert 写入WriteBatch堆栈如下
#0 rocksdb::WriteBatchInternal::Put
#1 rocksdb::WriteBatch::Put
#2 myrocks::ha_rocksdb::update_pk
#3 myrocks::ha_rocksdb::update_indexes
#4 myrocks::ha_rocksdb::update_write_row
#5 myrocks::ha_rocksdb::write_row
#6 handler::ha_write_row
#7 write_record
#8 mysql_insert
#9 mysql_execute_command
#10 mysql_parse
#11 dispatch_command
#12 do_command
#13 do_handle_one_connection一个简单的insert commit堆栈如下
#0 rocksdb::InlineSkipList<rocksdb::MemTableRep::KeyComparator const&>::Insert
#1 rocksdb::(anonymous namespace)::SkipListRep::Insert
#2 rocksdb::MemTable::Add
#3 rocksdb::MemTableInserter::PutCF
#4 rocksdb::WriteBatch::Iterate
#5 rocksdb::WriteBatch::Iterate
#6 rocksdb::WriteBatchInternal::InsertInto
#7 rocksdb::DBImpl::WriteImpl
#8 rocksdb::DBImpl::Write
#9 rocksdb::TransactionImpl::Commit
#10 myrocks::Rdb_transaction_impl::commit_no_binlog
#11 myrocks::Rdb_transaction::commit
#12 myrocks::rocksdb_commit
#13 ha_commit_low
#14 TC_LOG_MMAP::commit
#15 ha_commit_trans
#16 trans_commit_stmt
#17 mysql_execute_command
#18 mysql_parse
#19 dispatch_command
#20 do_command
#21 do_handle_one_connection提交流程及优化
这里只分析rocksdb引擎的提交流程,实际MyRocks提交时还需先写binlog(binlog开启的情况).
rocksdb引擎提交时就完成两个事情
- 写WAL日志(WAL开启的情况下rocksdb_write_disable_wal=off)
- 将之前的WriteBatch写入到memtable中
然而,写WAL是一个串行操作。为了提高提交的效率, rocksdb引入了group commit机制。
待提交的事务都依次加入到提交的writer队列中,这个writer队列被划分为一个一个group. 每个group有一个leader, 其他为follower,leader负责批量写WAL。每个group由双向链表link_older, link_newer链接。如下图所示
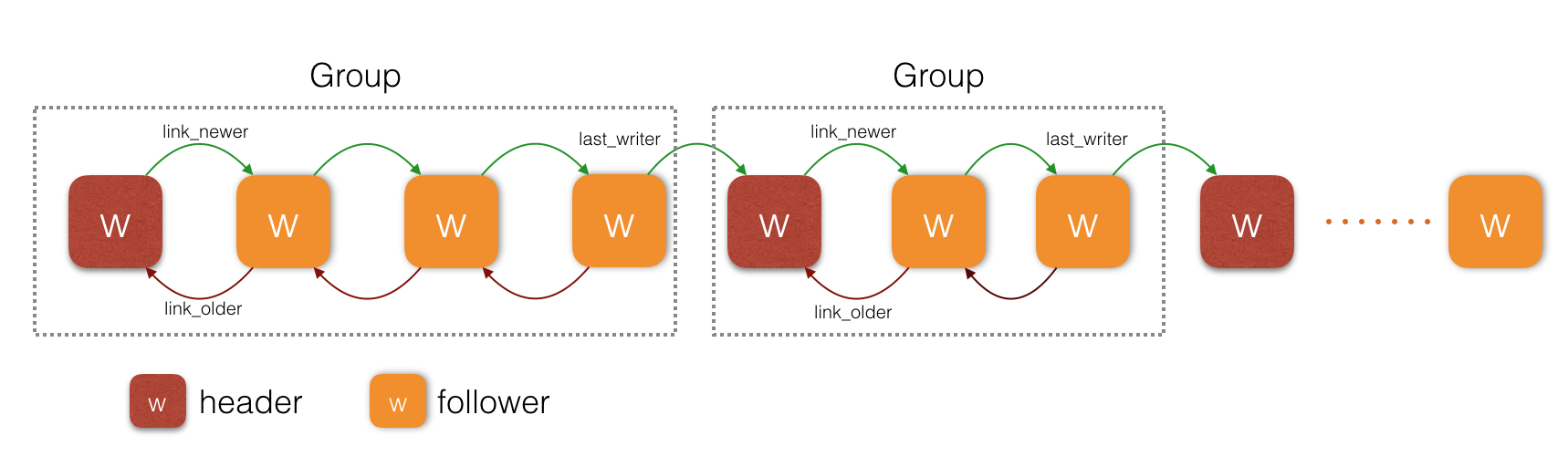
每个writer可能的状态如下
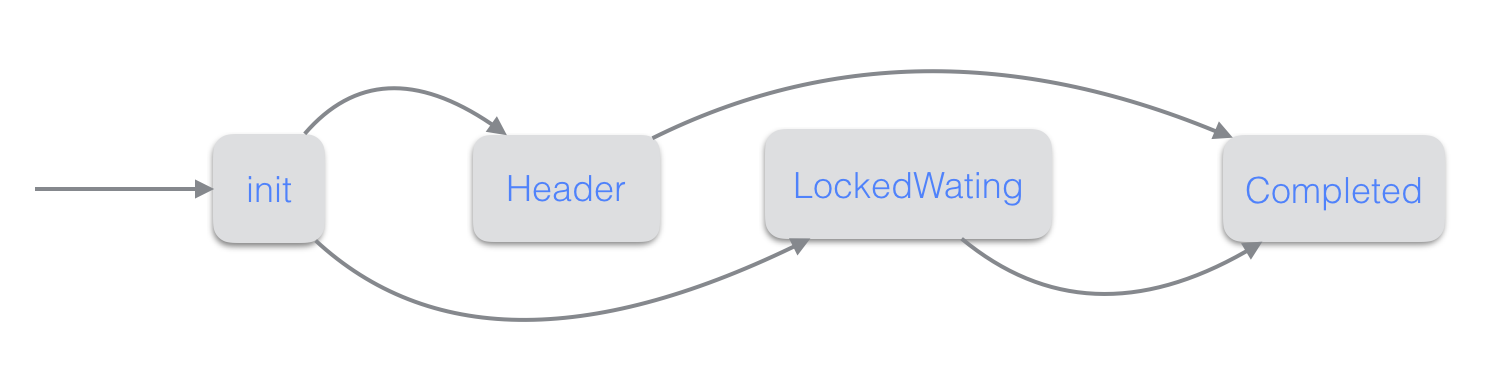
- Init: writer的初始状态
- Header: writer被选为leader
- Follower: writer被选为follower
- LockedWating: writer在等待自己转变为指定的状态
- Completed:writer操作完成
writer的状态变迁跟group是否并发写memtable有关 当开启并发写memtable(rocksdb_allow_concurrent_memtable_write=on)且group中的writer至少有两个时,group才会并发写。
group并发写时writer的状态变迁图如下:
group非并发写时writer的状态变迁图如下:
源码结构图如下(图片来自林青)
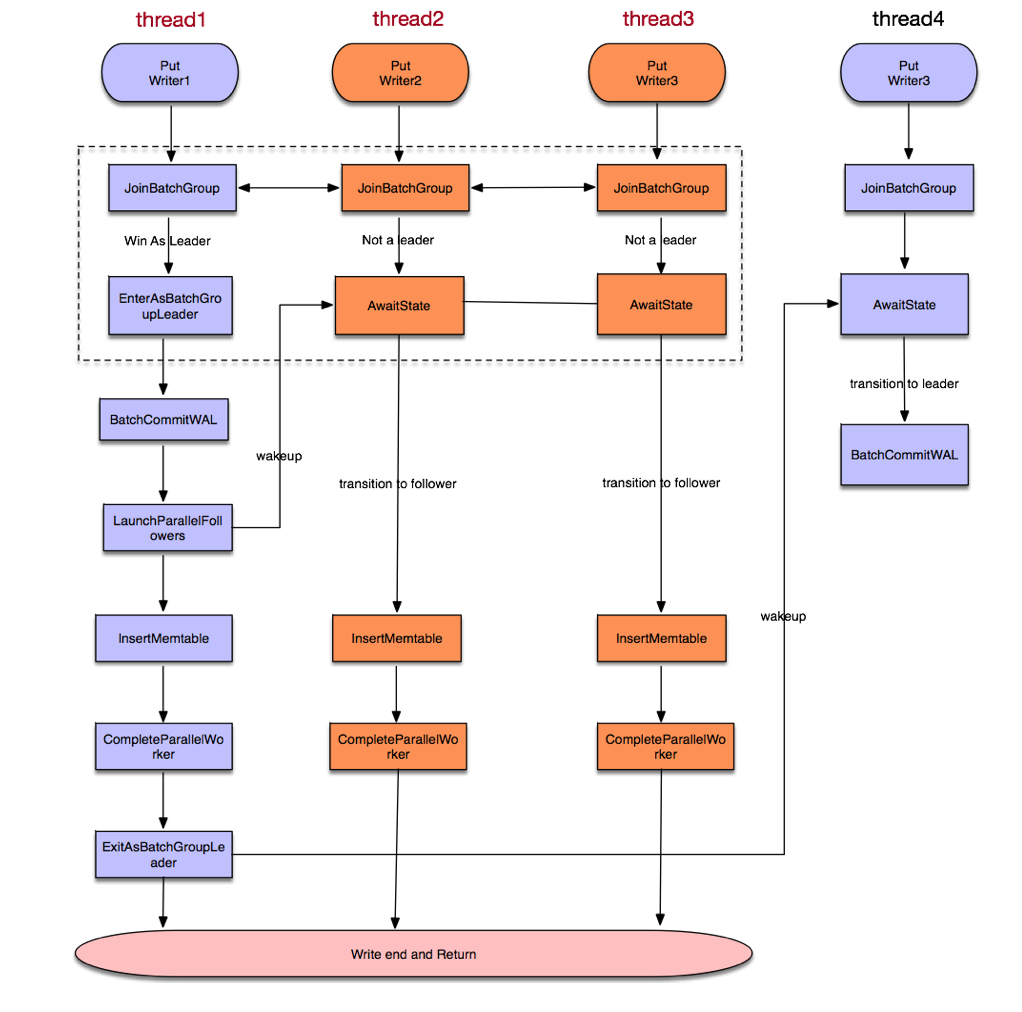
上面的图是在group内writer并发写memtable的情形。 非并发写memtable时,没有LaunchParallelFollowers/CompleteParallelWorker, Insertmemtable是由leader串行写入的。 这里group commit有以下要点
- 同一时刻只有一个leader, leader完成操作后,才设置下一个leader
- 需要等一个group都完成后,才会进行下一个group
- group中最后一个完成的writer负责完成提交和设置下一个leader
- Leader 负责批量写WAL
- 只有leader才会去调整双向链表link_older,link_newer.
注意这里2,3 应该可以优化改进为
- 不需要等一个group完成再进行下一个group
- 不同group的follower可以并发执行
- 只有leader负责完成提交和设置下一个leader
写入控制
rocksdb在提交写入时,需考虑以下几种情况,详见PreprocessWrite
- WAL日志满,WAL日志超过rocksdb_max_total_wal_size,会从所有的colomn family中找出含有最老日志(the earliest log containing a prepared section)的column family进行flush, 以释放WAL日志空间
- Buffer满,全局的write buffer超过rocksdb_db_write_buffer_size时,会从所有的colomn family中找出最先创建的memtable进行切换,详见HandleWriteBufferFull
- 某些条件会触发延迟写 max_write_buffer_number > 3且 未刷immutable memtable总数 >=max_write_buffer_number-1
- 自动compact开启时,level0的文件总数 >= level0_slowdown_writes_trigger
- 某些条件会触发停写 未刷immutable memtable总数 >=max_write_buffer_number
- 自动compact开启时,level0的文件总数 >= level0_stop_writes_trigger
具体可参考RecalculateWriteStallConditions
总结
rocksdb写入流程还有优化空间,Facebook也有相关的优化。
