一、 LSTM网络原理
1.1 要点介绍
- LSTM网络用来处理带“序列”(sequence)性质的数据。比如时间序列的数据,像每天的股价走势情况,机械振动信号的时域波形,以及类似于自然语言这种本身带有顺序性质的由有序单词组合的数据。
- LSTM本身不是一个独立存在的网络结构,只是整个神经网络的一部分,即由LSTM结构取代原始网络中的隐层单元部分。
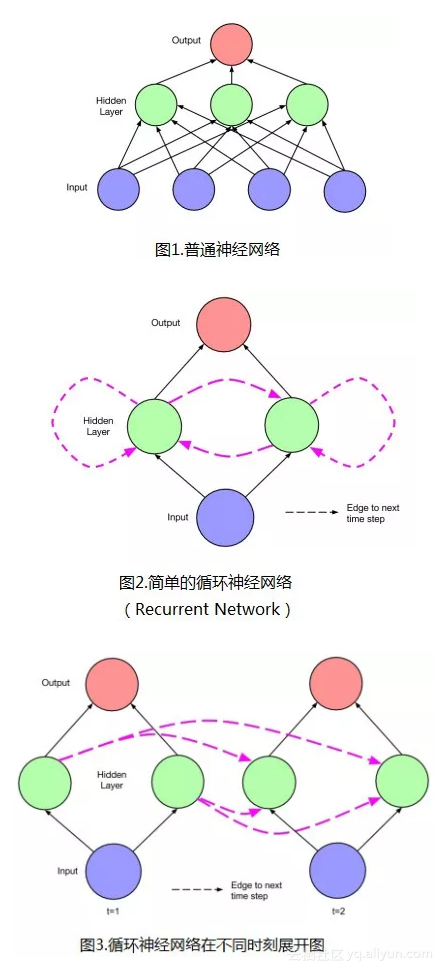
- LSTM网络具有“记忆性”。其原因在于不同“时间点”之间的网络存在连接,而不是单个时间点处的网络存在前馈或者反馈。如下图2中的LSTM单元(隐层单元)所示。图3是不同时刻情况下的网络展开图。图中虚线连接代表时刻,“本身的网络”结构连接用实线表示。
1.2 LSTM单元结构图
图4,5是现在比较常用的LSTM单元结构示意图:
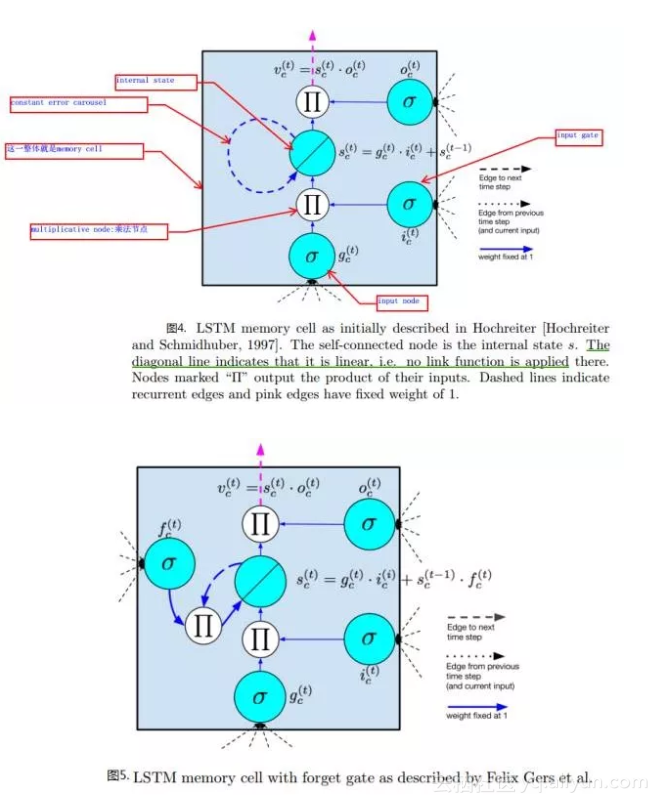
其主要结构成分包含如下:
- 输入节点input node:接受上一时刻隐层单元的输出及当前时刻是样本输入;
- 输入门input gate:可以看到输入门会和输入节点的值相乘,组成LSTM中internal state单元值的一部分,当门的输出为1时,输入节点的激活值全部流向internal state,当门的输出为0时,输入节点的值对internal state没有影响。
- 内部状态internal state。
- 遗忘门forget gate:用于刷新internal state的状态,控制internal state的上一状态对当前状态的影响。
各节点及门与隐藏单元输出的关系参见图4,图5所示。
二、代码示例
后台回复关键词“音乐”,下载完整代码及数据集
运行环境:windows下的spyder
语言:python 2.7,以及Keras深度学习库。
由于看这个赛题前,没有一点Python基础,所以也是边想思路边学Python,对Python中的数据结构不怎么了解,所以代码写得有点烂。但整个代码是可以运行无误的。这也是初赛时代码的最终版本。
2.1 示例介绍
主要以今年参加的“2016年阿里流行音乐趋势预测”为例。
时间过得很快,今天已是第二赛季的最后一天了,我从5.18开始接触赛题,到6.14上午10点第一赛季截止,这一期间,由于是线下赛,可以用到各种模型,而自已又是做深度学习(deep learning)方向的研究,所以选择了基于LSTM的循环神经网络模型,结果也很幸运,进入到了第二赛季。开始接触深度学习也有大半年了,能够将自已所学用到这次真正的实际生活应用中,结果也还可以,自已感觉很欣慰。突然意识到,自已学习生涯这么多年,我想“学有所成,学有所用”该是我今后努力的方向和动力了吧。
下面我简单的介绍一下赛题:
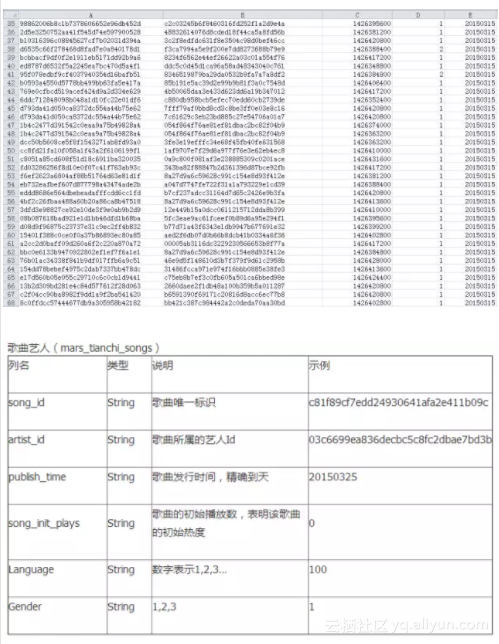
官方给的“输入”,共两张表:
- 一张是用户行为表(时间跨度20150301-20150830)mars_tianchi_user_actions,主要描述用户对歌曲的收藏,下载,播放等行为;
- 一张是歌曲信息表mars_tianchi_songs,主要用来描述歌曲所属的艺人,及歌曲的相关信息,如发行时间,初始热度,语言等。
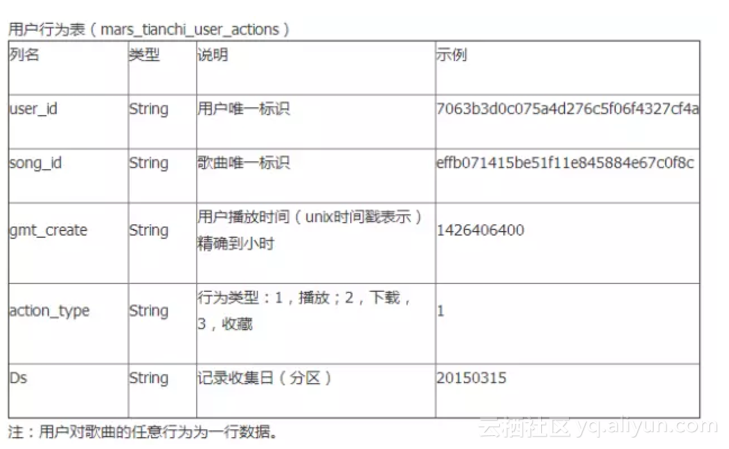
样例:
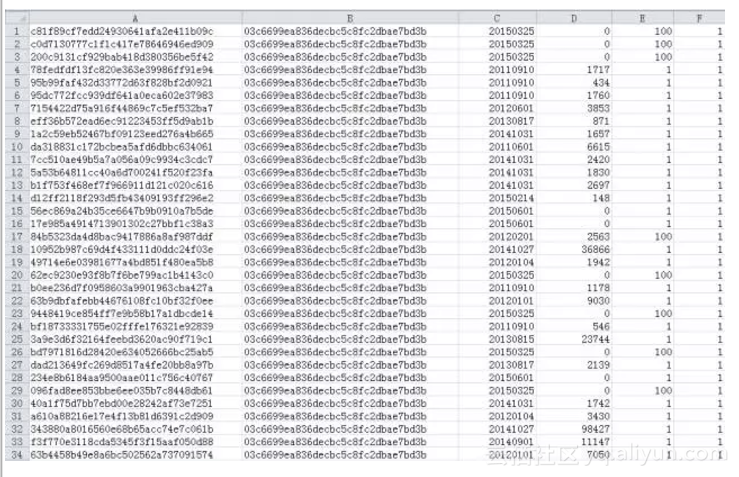
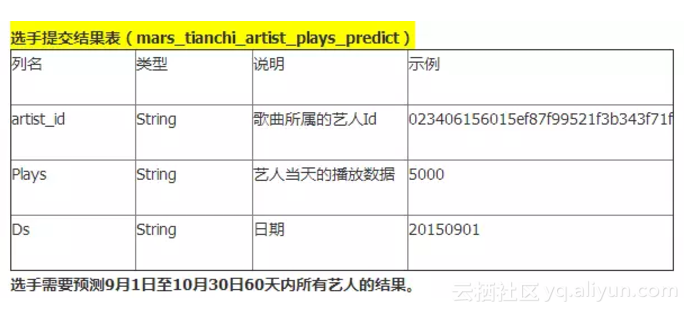
官方要求“输出”:预测随后2个月(20150901-20151030)每个歌手每天的播放量。输出格式:
由于是对歌手的播放量进行预测,所以直接对每个歌手的“播放量”这一对象进行统计,查看在20150301-20151030这8个月内歌手的播放量变化趋势,并以每天的播放量,连续3天的播放均值,连续3天的播放方差,作为一个时间点的样本,“滑动”构建神经网络的训练集。网络的构成如下:
- 输入层:3个神经元,分别代表播放量,播放均值,播放方差;
- 第一隐层:LSTM结构单元,带有35个LSTM单元;
- 第二隐层:LSTM结构单元,带有10个LSTM单元;
- 输出层:3个神经元,代表和输入层相同的含义。
目标函数:重构误差。
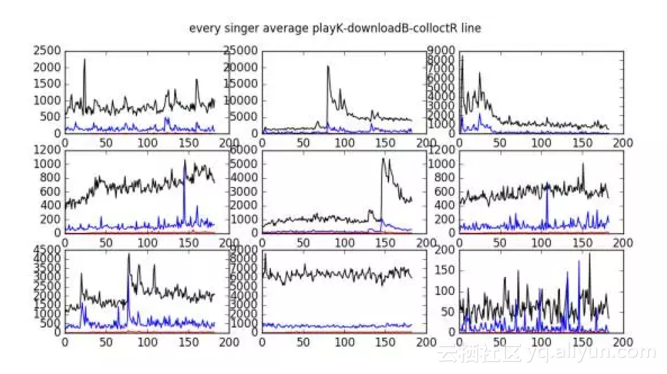
下图是某些歌手的播放统计曲线:
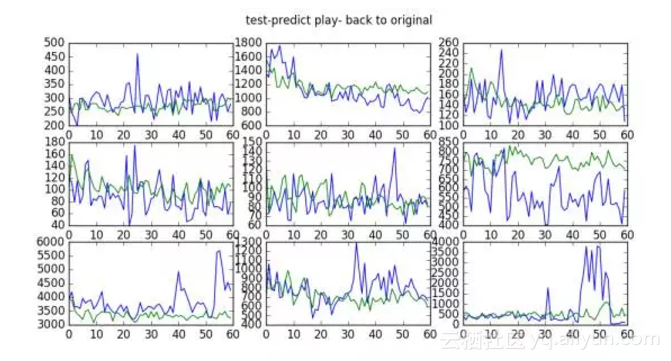
2.2 预测结果
蓝色代表歌手真实的播放曲线,绿色代表预测曲线:
原文发布时间为:2017-12-11
本文来自云栖社区合作伙伴“大数据文摘”,了解相关信息可以关注“x”微信公众号




