爱可可老师的微博账号创建于2010年底,初期的微博内容充满了人情味,分享了爱女出生的喜悦、行业资讯、学习资料,以及人生工作感悟。
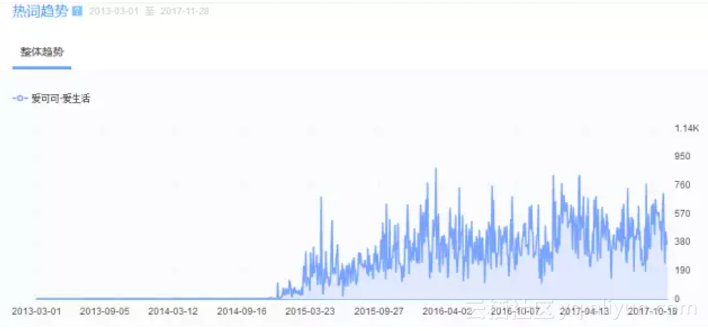
热词分析显示,爱可可微博是从2014年底开始热度变高,此时该账号已是每日凌晨四五点起分享大量的学习资料。
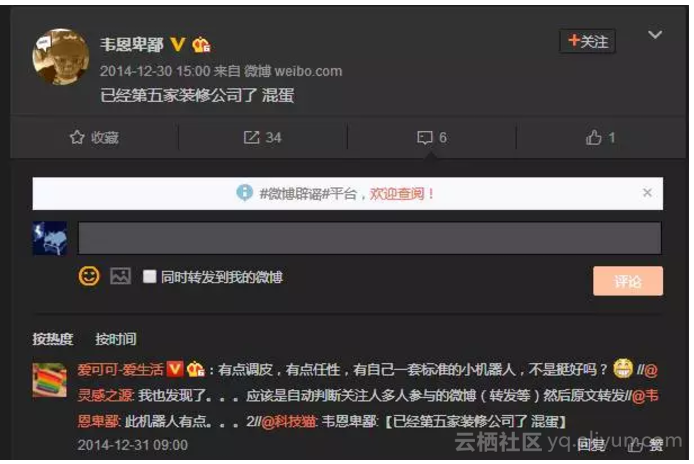
在分享资料的间隙,爱可可老师也会发布一些个人见解,其中有一条微博内容值得玩味。
一个机器人账号,连微博昵称带内容一起转发了某位它的关注人的微博,被该博主发现了,评价它“此机器人有点二”,然后爱可可老师评论道:“有点调皮,有点任性,有自己一套标准的小机器人,不是挺好吗?”
由此可见,爱可可老师觉得微博机器人是很有趣的,同时,他也经常分享该机器人转发的内容。
从2015年1月以后,爱可可老师的微博内容基本为学术资料,且不带任何感情色彩,让人不禁猜测,这些资料是否全由机器人挖掘并转发呢?
我们采集了该账号从2017年10月30号——2017年11月30号所有微博的信息做了如下统计:
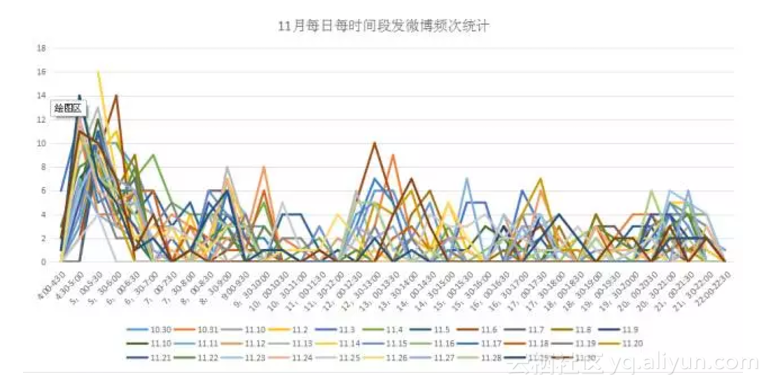
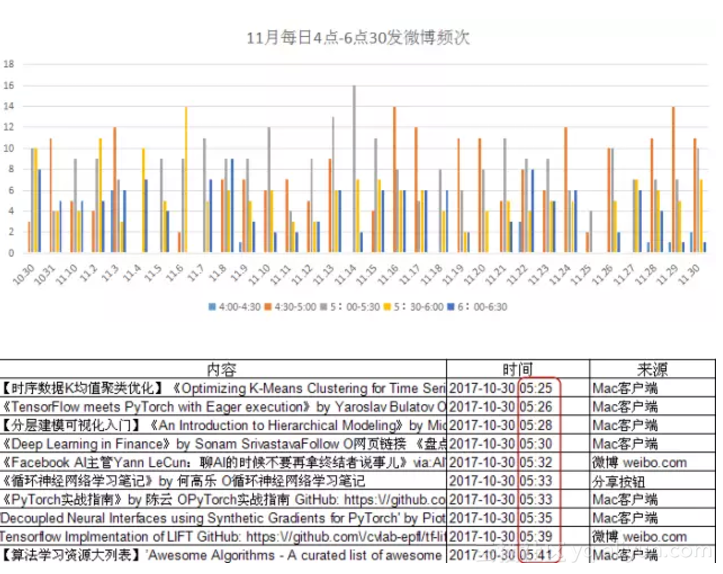
这个月以来,他一共发布了1952条微博,平均每天发布61条,时间集中在凌晨四点半至晚上十点半以前,平均每天凌晨4点44分开始发布第一条微博。由统计图看出,爱可可老师发微博最集中的时间段为每日凌晨四点半到六点半,在这两个小时之内,他平均发布25条,占每天总数的近一半。
具体统计每日4点—6点半的数据可以发现,爱可可在该时间段发微博的频次非常高,特点为连续两、三分钟内发送一条或多条带6-9张图的微博。
根据词频分析微博内容,出现最多的词语全部与数据科学相关。

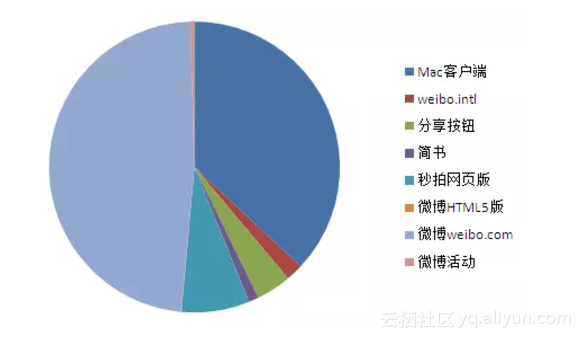
根据微博来源可以看出,爱可可老师最常使用的是Mac客户端和微博网页版。在前几年充满人情味的微博里,尚且有Android客户端的来源显示,而现在的内容全部发自于电脑。
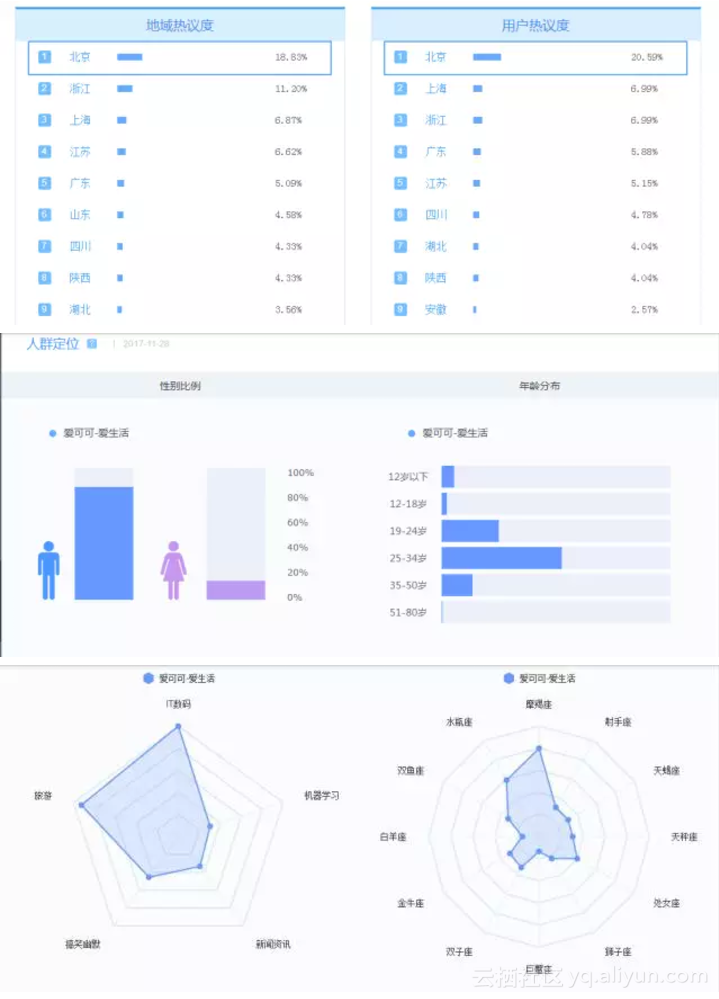
我们还对爱可可老师的粉丝进行了分析,发现最活跃的用户画像为北京IT男青年,而且还是严谨细致内敛腹黑的摩羯座。粉丝对爱可可老师的留言,多半是保存资料和表达感谢,然而爱可可老师很少与他们互动。
那么,爱可可老师的微博内容究竟是否由机器人产出呢?下面我们将盘点出机器人写作的特点,并与之进行比较。
机器写作效率VS爱可可老师写作效率
从工作方式和步骤来看,机器写作与人工写作相像,都是三步走的工作模式:围绕报道主题采集信息——分析信息,联系背景解读意义——按照新闻格式和语法规则写出文章。不同的是,写稿机器人是一套执行命令的程序,能够快速抓取、处理海量的文献资料数据;而人类作为生物,先天具有生理和行动局限,在处理数据方面与机器人相形见绌,比速度自然落后。九寨沟发生7级地震后,地震信息播报机器人在21个小时的时间内,连续自动推送了15条地震速报,字数均在110-634字之间,最快的一条耗时5秒成稿为126字。
对比爱可可老师,该账号在7年内发布近45000条微博,日均18条左右,只是现阶段活跃度远高于其早期阶段,近一个月日均在60条左右。此前,微博大V“@任志强”在5年多时间内发出9万余条微博,日均50条左右,属于典型的活跃性微博用户,所以日均五六十条微博的频次也不足以对@爱可可-爱生活的运营者做出准确判断。然而,爱可可老师发送微博的特点为特别时间段非常密集,一到三分钟发一条、甚至几条微博是常有之事。这样的高效率背后,是难以做到从浏览文章到分享文章的流程的。
此外,机器运作的微博可以实现实时推送的功能,而爱可可老师虽然推送频率高,但并不是实时进行分享,而是集中性分享,所以,爱可可老师应该是通过集中性的浏览文章,或者是利用机器学习自动抓取信息结合自己空闲时间手动进行高频率的集中性推送。

机器写作内容VS爱可可微博内容
机器人写作本质上是一种程序化运作,这套程序在规则作用下进行逻辑推理,处理数据量丰富、时效性强的工作,因此,写稿机器人从基因上决定了其自动化生产偏向以数据为基础的内容。具体就是擅长财经、体育、自然灾害等模式化领域。如今年年初,南方都市报社上线的写稿机器人“小南”,基于机器学习算法,融合领域知识,能够对数据进行深度分析,发掘重要的消息和事件,并用自然语言进行表达。
而爱可可老师微博高频更新的内容绝大多数属数据科学领域,又倾向于机器学习这一分支。制定以“机器学习”“算法”等为关键词的规则,连接并抓取学科资源库数据,是方便高效可操作性强的选择,猜想@爱可可-爱生活由机器运营也并不奇怪。不过,目前出现微博上的机器人账号,程序大都比较简陋,在人类看来有些“愚笨”,如果爱可可老师用机器发微博,想必此套程序更加智能巧妙。
机器写作风格VS爱可可微博风格
引入机器写作的目的就是解放人力、服务社会,归根结底,机器写作服务人就要模仿人。例如,在编辑团队的指引下,“小南”就会学习人类的写作方式,以人类特有的生活化语言表述某一事实的现实影响,如“小南”在判断出列车剩余票数不足后,小南会使用“票数紧张”提醒读者。随着用户社交数据的接入,机器将不断发掘洞察用户习惯,越来越有人情味,以精准化的服务提升用户体验,人工和机器作业的界限将越来越模糊。另外,据英国《每日邮报》3月10日报道,南加利福尼亚大学进行的一项最新研究发现,推特中的机器人数量达4800万,占15%,它们能发出“点赞”、“转发”、“关注”等社交行为。
反观爱可可老师的微博,涉及个人观点和情感的内容几乎为零,而微博评论以网友内部交流为主,博主参与较少,且回复语句较短,互动活跃度不高,有可能是机器运营的结果。
通过以上分析,@爱可可-爱生活发布的微博内容很可能有机器学习算法的参与,参与环节在信息收集、筛选方面的可能性较大。
原文发布时间为:2017-12-9
本文作者:数据派
