
摘要:2017云栖大会dataworks专场,国网浙江电力大数据平台架构师陈振带来Dataworks/MaxCompute在国网应用的实践。本文主要从建设数据仓库的三个痛点开始谈起,引出企业级数仓架构设计,着重通过数据集成和企业级管理为大家分享了具体的应用情况,最后作了简要的展望。
以下是精彩内容整理:
背景&动机
由于长期业务系统的竖井式发展,导致业务系统中数据存储分散,当你要进行多个业务系统中数据的联合统计场景时,我们通常不得不汇总三到四个以上的业务系统数据,久而久之就会在数据中心里形成一张非常复杂的数据集成网络,由于业务系统给出的接口非常老旧,导致在数据集成网络中涉及到的技术手段又非常多,总共这三大痛点给我们数据中心管理带来非常大的困难。
所以,我们开始思考,为什么不把全部的业务数据放到统一的数据仓库中去呢?为了进行数据的统计分析,不得不建设复杂的数据集成网络,那么,为什么不把统计和计算放到企业级数仓中去呢?既然我们的数据源端技术手段那么多,为什么我们不把企业级数仓建设成一个能够兼容多种数据源的企业级数仓呢?
我们想要企业级数仓具备比较高的时效性,因为我们的数据最终面向不特定的业务场景,它的后端需求是在不断变化的;其次,我们需要企业级数仓具备企业级管理能力,这必定会成为公司的多人协作平台,如果不具备企业级管理能力,就无法实现多人协作;最后,我们需要有灵活的数据输出,企业级数仓的数据必须能够合理赋能给我们业务团队。
架构设计
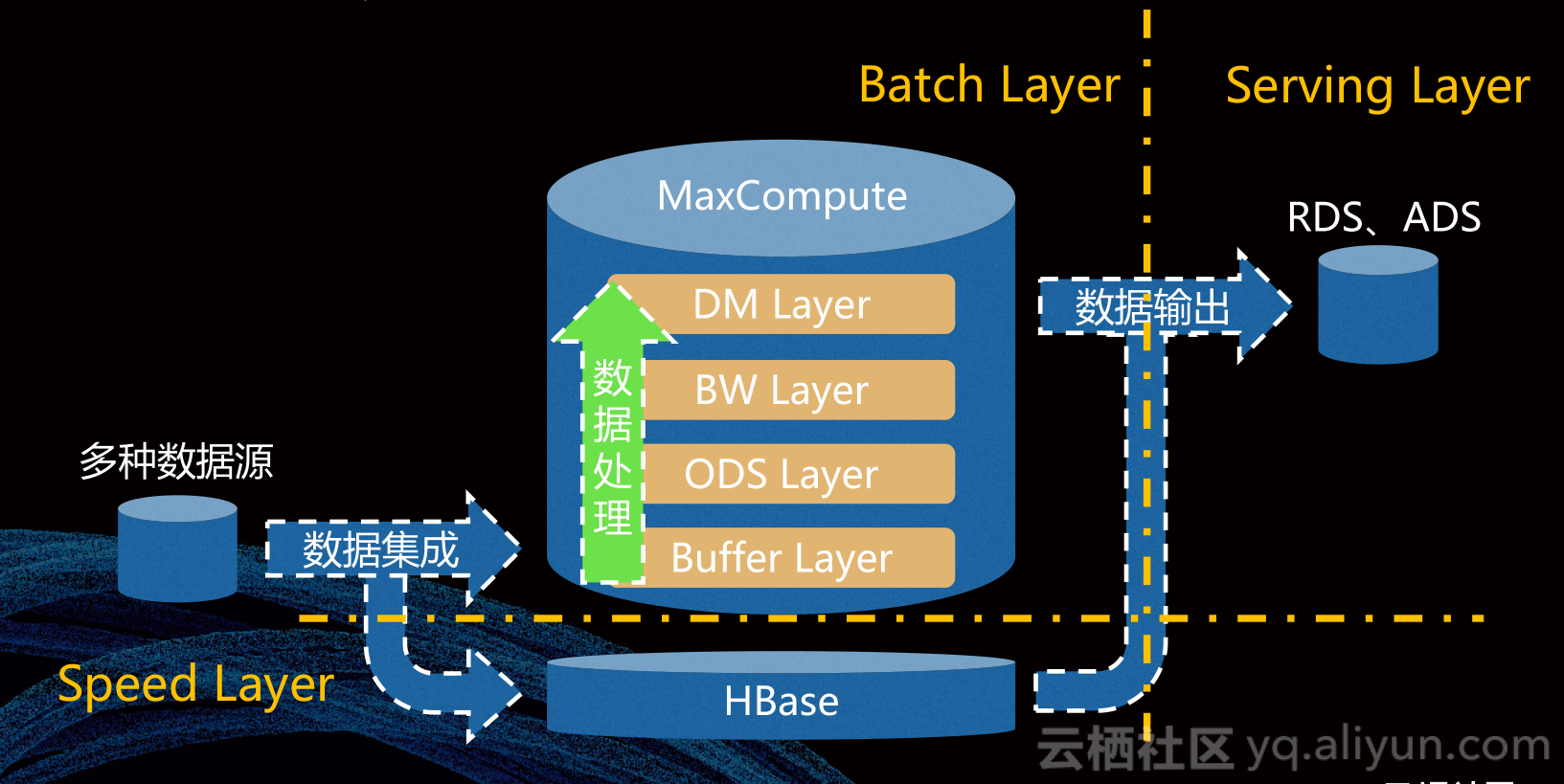
基于以上需求,我们开展了企业级数据仓库架构设计,最后,我们设计出了如图的数据仓库。我们的数仓符合一般的数仓技术架构,数据从多种数据源出来,被数据集成框架输入到两条路径中,上面一条路径比较慢,下面一条路径比较快,快路径数据输入到HBase中,慢路径数据输入到MaxCompute中,我们会把慢数据中全部业务数据都放到数据仓库中,快路径主要接入一些电力传输网络上的传感器发送过来的数据,这部分数据实时性比较高,MaxCompute和HBase中数据经过统计和分析之后,产生的结果数据通过数据输出链路传输给RDS、ADS实例,由它们作为企业级数仓数据输出端口。
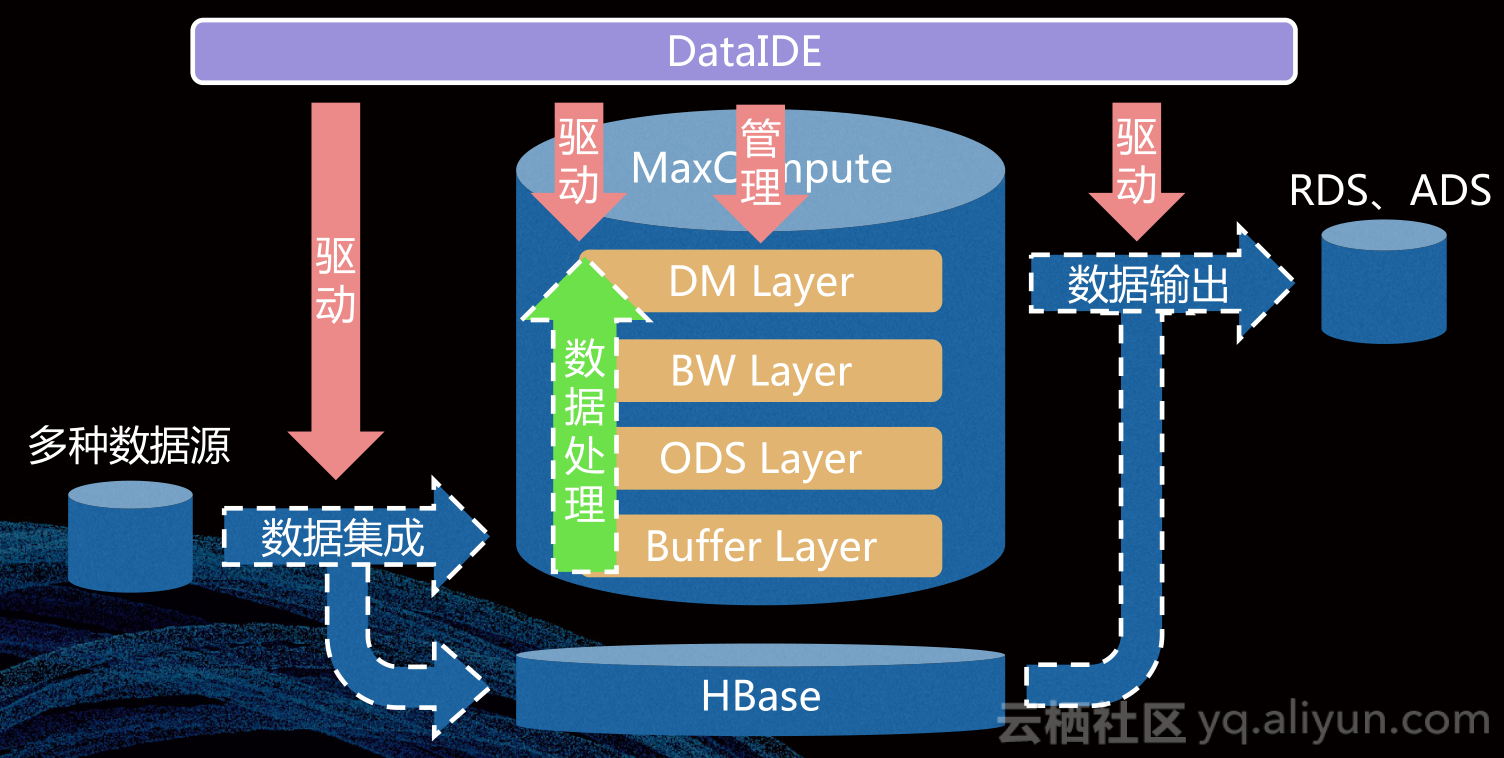
在这一整套技术架构里面,数据在里面成功流转的关键在于两方面。一方面是数据集成、数据处理和数据输出三条链路的驱动;一方面是MaxCompute中四层企业级管理。那么,我们到底是怎样做的呢?
数据集成
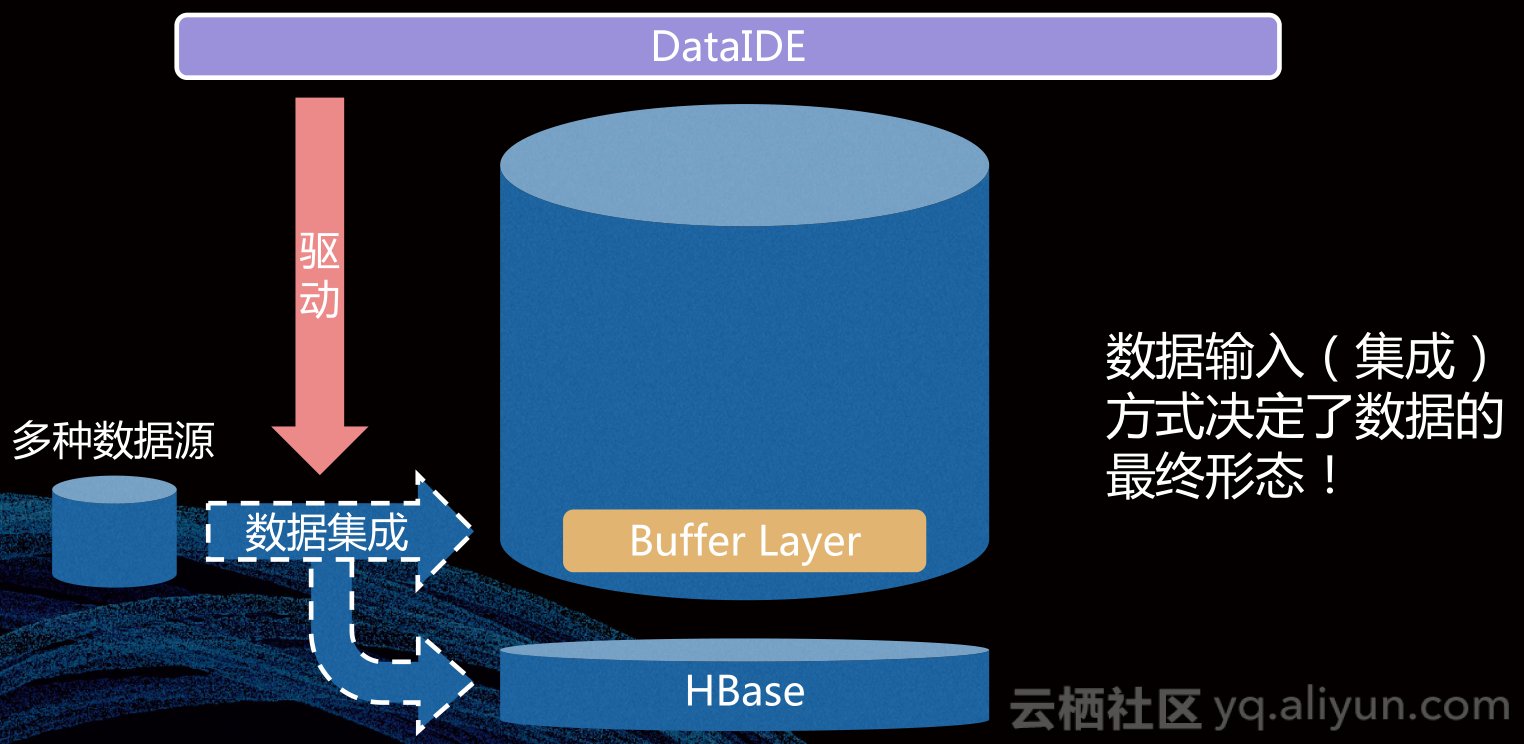
数据集成作为把守企业级数仓的数据输入端,最终决定了数据仓库保有的信息量,也决定了数据最后表现出来的最终形态。由于我们是面向全公司的所有数据业务集成,始终面对着变化的数据源,数据集成架构必须要满足不同业务、不同数据源的数据输出方式的架构。我们有很多中集成方式,包括批式集成、流式集成、局部增量集成、流转批、流转局部增量、流转拉链表。
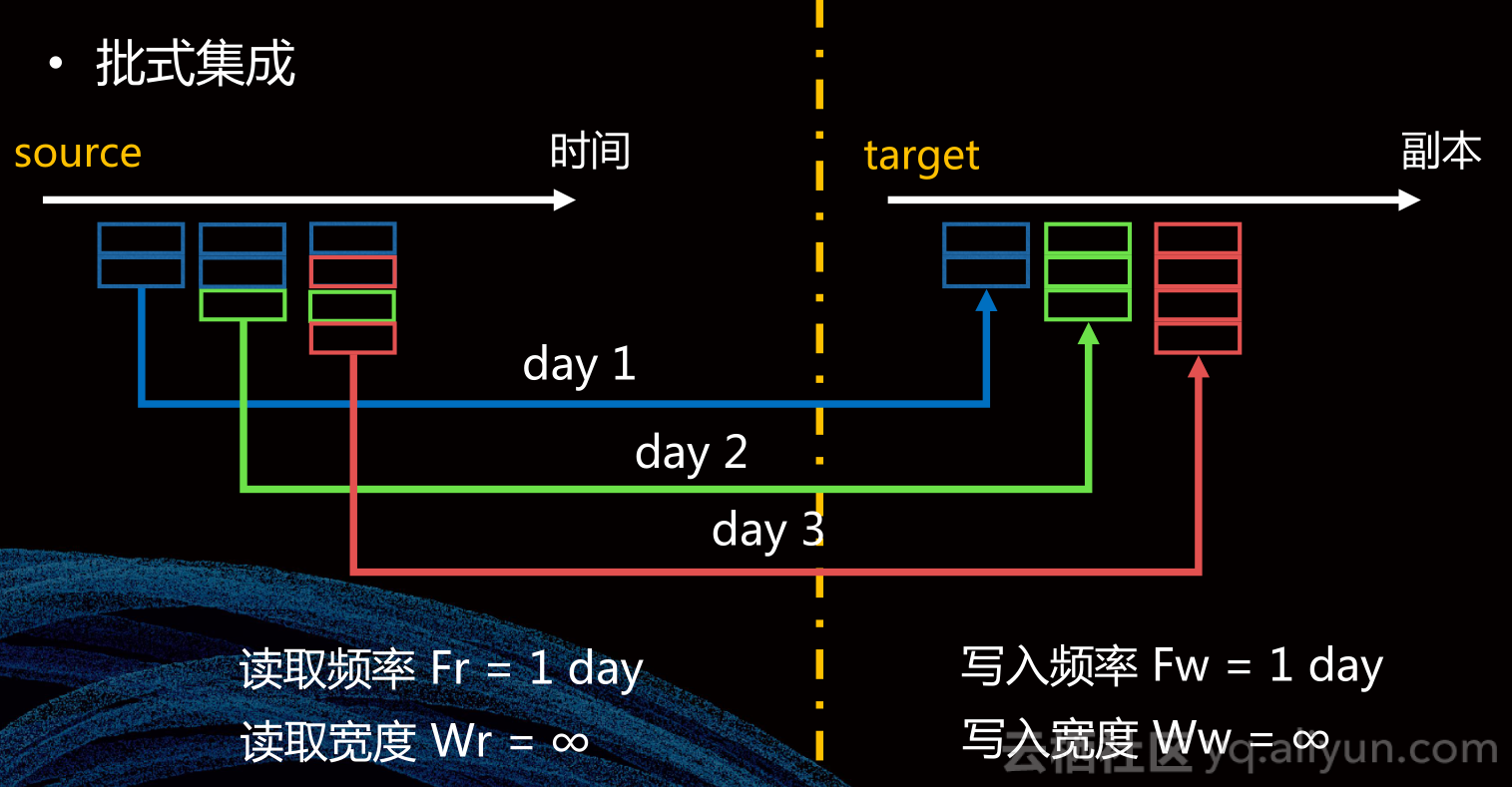
批式集成会在每个数据集成周期开始时候把源库中原表的最新快照复制到目标库中,并且把最新快照加入到目标表的最新的时间分区中,这个目标表的时间分区是按照接入这一刻的时间点进行划分的。
这种数据集成方式使用数加CDP即可完成,优缺点很明显,优点是结构简单,兼容性好,易排错,自带ETL;缺点是源端压力大,CDP自带限速光环,目标端存储效率低。批式集成方式一般用于小表、维度表、主数据表。
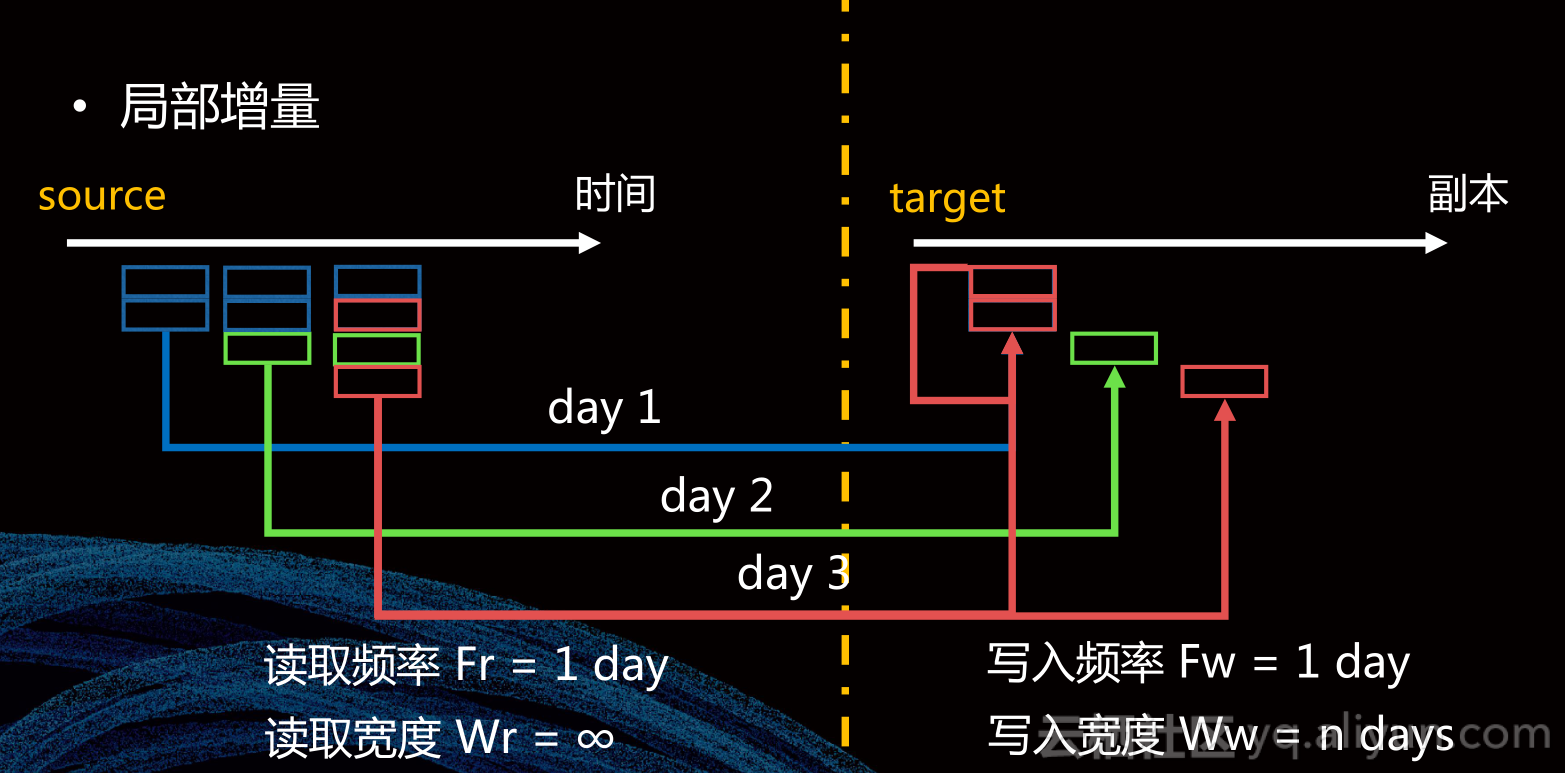
为了弥补批式集成的空白,我们设计了一种局部增量数据集成。这种集成方式在原表中行为与批式集成一样,只不过它将原表最新快照复制过来不是马上插入到目标表中,而是把它存为一张中间表,中间表中我们会过滤出每天最新部分数据,按照这部分数据业务时间插入到目标表对应的时间分区里面,这里目标表的时间分区不是按照集成时刻进行划分的,而是按照表里面每一条业务数据的业务时间进行划分的。
这种数据集成方式保证了每一条数据都不会被重复存储,优点是update友好,目标端存储效率高;缺点是要求主键,依赖Timestamp,需设置自依赖,丢失历史信息。适用于有明确业务周期、有良好Timestamp的大表,并且确实考虑到目标端存储效率的表。
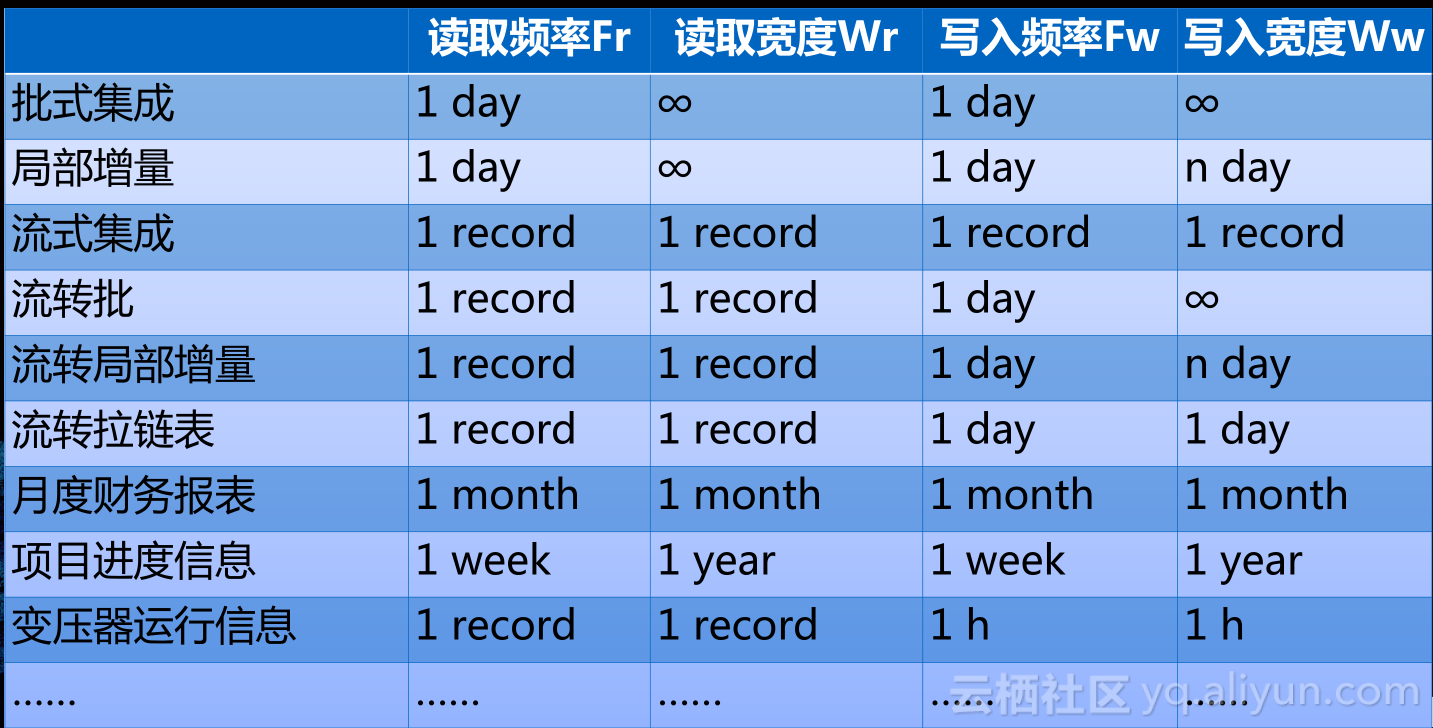
除了以上两种集成方式,还有其他集成方式,这些方式都不是凭空产生的,我们都是通过四个不同的参数来描述,这四个参数都是可以根据实际数据情况自由配置的。我们要满足一些关系保证数据集成链路运行过程中信息量不会丢失,比如Fr ≤ Wr , Fw ≤ Ww, Fr ≤ Fw,Fr 、Wr根据业务属性设计,Fw、Ww根据时效性需求设计,Fr < Fw,则存在数据积累,需中间表,Wr < Ww,则存在历史数据归并,需自依赖。
企业级管理
企业级管理在一般数仓中是不用去考虑的,但是我们汇总的是全公司全部数据,一旦这些数据进入到仓库中,我们就把其看成是一种生产资料,围绕着生产资料,必定会有很多人协同进行数据管理、运维、处理和使用,我们需要数据仓库的组织账号管理,也要有数据仓库中资源数据权限隔离,还要有专人运维和数据服务发布。
账号组织管理
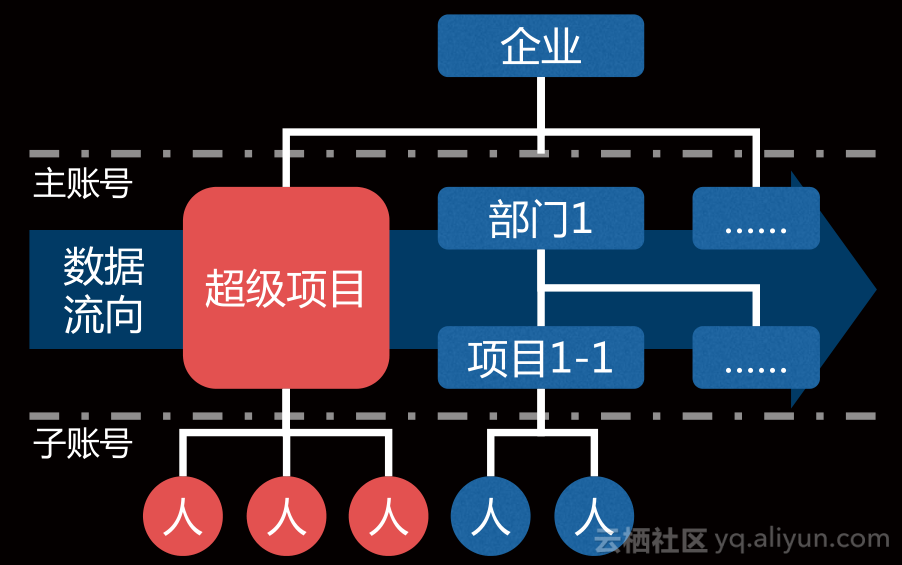
组织账号管理是管理项目和人。对应数加中的两层账号体系,一是主账号,对应项目,用于项目资源分配、成本核算、赋权;一是子帐号,对应人,用于行为审计。我们又把项目分为两大类,一类是超级项目:数据服务团队,维护公共数据(数据集成、ODS、BW);一类是一般项目:业务项目团队,生产特定业务口径数据(DM)。
权限管理
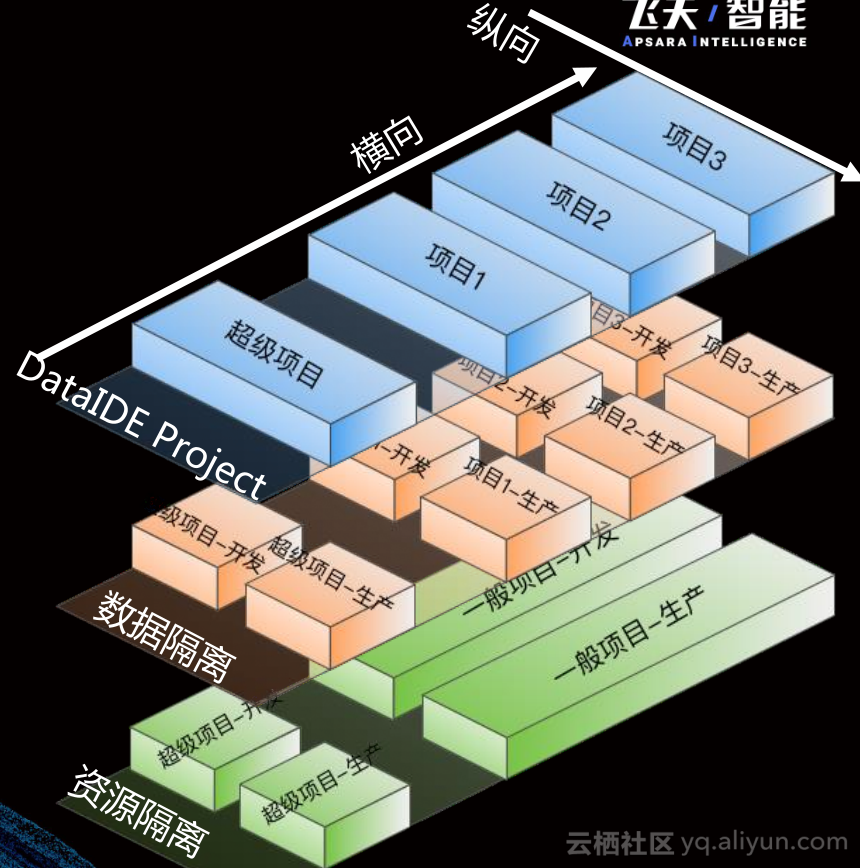
权限管理管理对象为资源权限和数据权限。我们从横向、纵向两方面管理,横向隔离业务项目 <-> 业务项目,纵向隔离开发项目 <-> 生产项目。从资源策略上讲,纵向隔离、横向归并。从数据策略说,横向纵向两个维度都会隔离。如果要打破隔离,需要进行数据授权,表授权使用DataWorks IDE,横向行授权通过视图 + 物化过程,纵向行据授权通过数据采样与脱敏。
运维
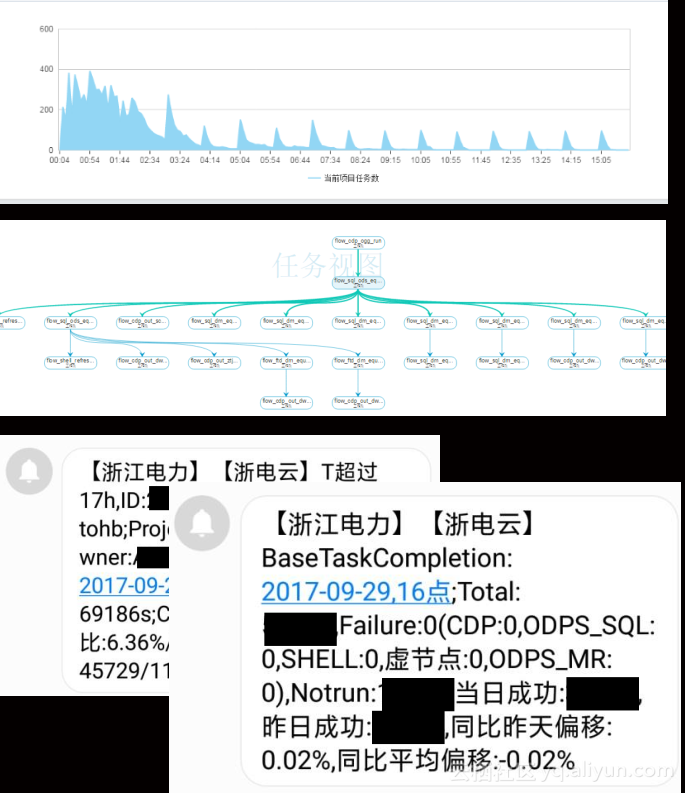
运维主要分成四大块,具体如下:
1. 任务管理:多种类型任务的定义,任务编排,虚节点的使用;
2. 任务测试:单任务测试,任务树测试(补数据),忌:直接在开发窗口测试任务;
3. 任务发布:专人审核发布,开发生产依赖解耦;
4. 任务监控:多类型任务统一监控,批量控制,任务异常告警,时间基线告警,计数基线告警。
数据服务发布
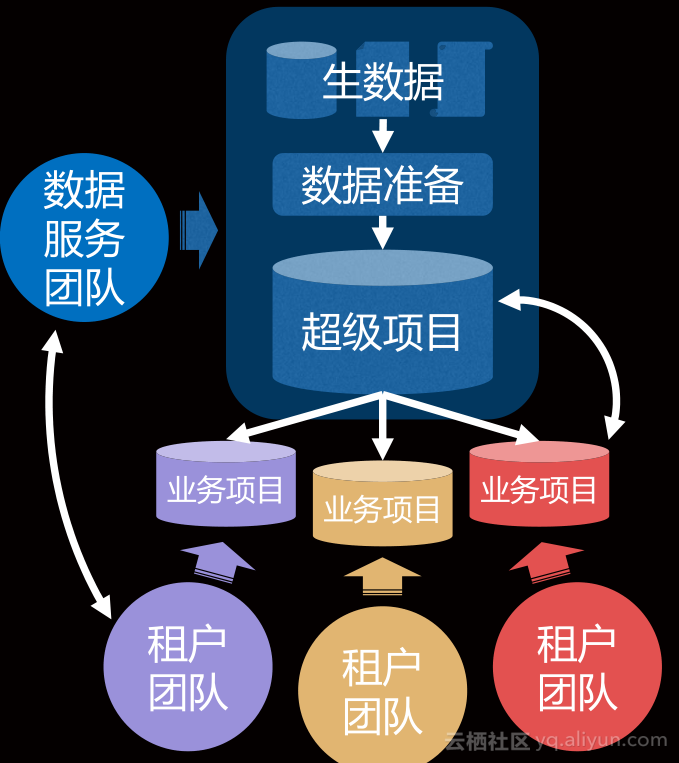
数据服务是数据仓库的生命力所在,我们成立了数据服务团队“经营”数据仓库“超级项目”。包括:
1. 准备环节:业务需求调研,技术需求调研,数据接入,数据整理,数据分级,业务模型整理,标准服务目录整理
2. 售前环节:项目接洽,业务范围、组织范围、时间范围敲定,技术方案敲定,集成需求确认
3. 售中环节:数据补接,数据授权,基础资源准备,数据交付,业务上线
4. 售后环节:数据集成链路运维,数据处理任务运维,数据共享,数据资产升级
期望与展望
我们希望在以下方面进行优化和升级:
1. 基础技术层面:我们期望可以驱动更多底层引擎,提供更多技术选项。这会涉及到不同处理引擎间迁移数据,我们可以通过一系列自动配置数据集成链路来处理不同数据处理引擎间的数据交互。
2. 数据处理层面:我们需要解决数据处理任务从慢到快的过程,增量过滤条件上推,全增量处理,规范源端时间标记,全链路维护时间戳,优化增量数据处理性能。
3. 数据服务:加强数据服务发布工具研发,优化数据使用体验,包括数据服务目录发布,自动分级、脱敏,链路异常告警广播等。
欢迎加入“数加·MaxCompute购买咨询”钉钉群(群号: 11782920)进行咨询,群二维码如下:


阿里巴巴大数据-玩家社区 https://yq.aliyun.com/teams/6/
---阿里大数据博文,问答,社群,实践,有朋自远方来,不亦说乎……





