Hello World!今天我们将讨论深度学习中最核心的问题之一:训练数据。深度学习已经在现实世界得到了广泛运用,例如:无人驾驶汽车,收据识别,道路缺陷自动检测,以及交互式电影推荐等等。
我们大部分的时间并不是花在构建神经网络上,而是处理训练数据。深度学习需要大量的数据,然而有时候仅仅标注一张图像就需要花费一个小时的时间!所以我们一直在考虑:能否找到一个方法来提升我们的工作效率?是的,我们找到了。

现在,我们很自豪的将Supervisely令人惊叹的新特性公诸于世:支持AI的标注工具来更快速地分割图像上的对象。
在本文中,我们将重点介绍计算机视觉,但是,类似的思路也可用在大量不同类型的数据上,例如文本数据、音频数据、传感器数据、医疗数据等等。
重点:数据越多,AI越智能
让我们以吴恩达非常著名的幻灯片开始,首先对其进行小小的修改。 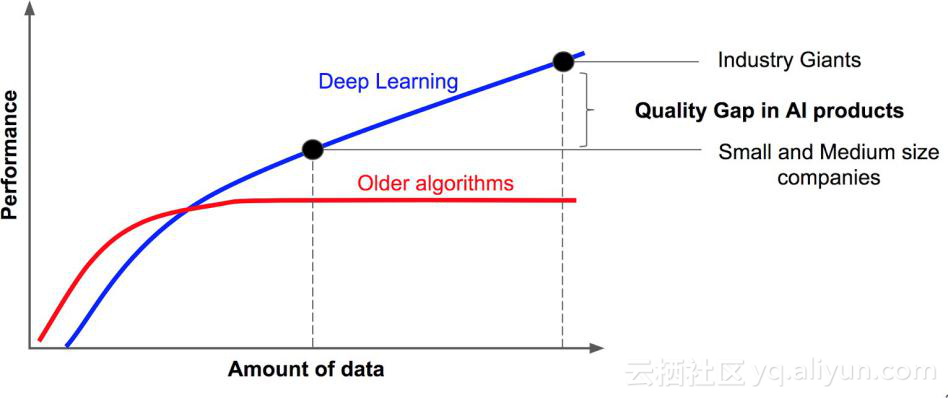
深度学习的表现优于其它机器学习算法早已不是什么秘密。从上图可以得出以下结论。
结论 0:AI产品需要数据。
结论 1:获得的数据越多,AI就会越智能。
结论 2:行业巨头所拥有的数据量远超其它企业。
结论 3:AI产品的质量差距是由其所拥有的数据量决定的。
网络架构对AI系统的表现影响很大,但是训练数据的多少对系统表现的影响最大。致力于数据收集的公司可以提供更好的AI产品并获得巨大的成功。
常见错误:AI全都是关于构建神经网络的。
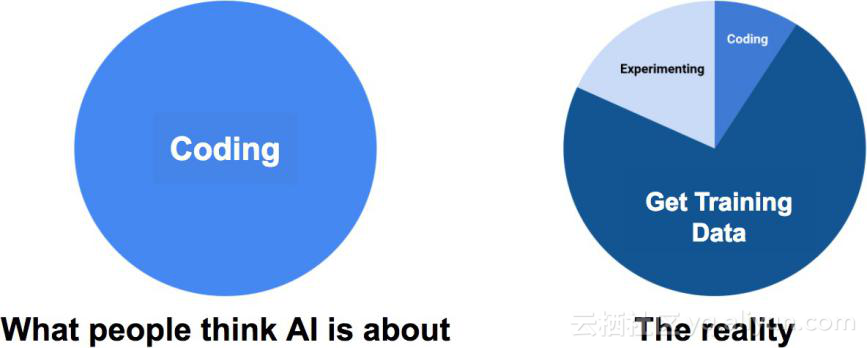
如上图所示,当人们一想到AI,就会想到算法,但是也应该考虑到数据。算法是免费的:谷歌和其他巨头更倾向于向世界分享他们最先进的(state-of-the-art)研究成果,但是他们从不会共享数据。

许多人已经跳上了人工智能潮流的列车,并且创造了极棒的构建和训练神经网络的工具,然而关注训练数据的人却少的可怜。当企业打算将人工智能转换成实际应用时,会倾尽全部工具用于训练神经网络,却没有用于开发训练数据上的工具。
吴恩达说论文已经足够了,现在让我们来构建AI吧!
好主意,我们完全赞同。目前有许多论文和开源成果论述了最先进的(state of the art )且涵盖所有的实际应用的神经网络架构。想象一下,你获得了一个价值10亿美元的新想法。首先想到的肯定不会是:我将使用哪种类型的神经网络?最有可能的是:我在哪里可以得到能建立最优价值的数据?

让我们来寻找一些有效的方法训练数据,可行的方法如下:
1.开源数据集。深度神经网络(DNN)的价值是用于训练数据,在计算机视觉研究中,大多数可用数据都是针对特定研究小组所研究的课题而设计的,通常对于新研究人员来说,需要搜集更多额外的数据去解决他们自己的课题。这就是在大多数情况下开源数据集并不是一个解决方案的原因。
2.人工数据。它适用于类似OCR文字识别或者是文本检测,然而很多实例(如人脸识别,医学影像等)表明人工数据很难甚至是不可能产生,通常的做法是将人工数据和带标注的图像相结合使用。
3.Web。自动收集高质量的训练数据是很难的,通常我们会对收集的训练数据进行修正和过滤。
4.外面订购图像标注服务。一些公司提供这样的服务,我们也不例外。但其很大的缺点是不能进行快速的迭代。通常,即使是数据专家也不确定如何标注。通常的顺序是做迭代研究:标注图像的一小部分→建立神经网络架构 →检查结果。每个新的标注都将会影响后续的标注。
5.手动标注图像。仅适用于你自己的工作,领域内的专业知识是很关键的。医学影像就是个很好的例子:只有医生知道肿瘤在哪里。手动注解图像这个过程很耗时,但是如果你想要一个定制化的AI,也没有其他办法。
正如我们所看到的,其实并没有万能方法,最常见的方案是创建我们自己任务特定的训练数据,形成人工数据,如果可能的话再整合到公共数据集中。这其中的关键是,你必须为特定的任务建立自己独一无二的数据集。
让我们深入学习来构建深度学习
深度学习接近于数据匮乏,且其性能极度依赖于可供训练数据的数量。
通过实例我们可以看出标注的过程有多困难。这里是标注过程所花费时间的一些原始数据,例如使用Cityscapes数据集(用于无人驾驶),在对Cityscapes数据集中单个图像的精细像素级的标注平均需要花费1.5h,如果标注5000个图像,则需要花费5000*1.5=7500h。假设1h=$10(美国最低工资),那么仅仅是标注该数据集就需要花费约$7.5万左右(不包括其他额外的成本)。同样吃惊的是,像这样一家拥有1000名做无人驾驶图像标注员工的公司,只不过是冰山一角。
神经网络能否帮助我们提高图像标注的效率呢?我们可不是第一个试图回答这一问题的人。
半自动化实例标注很早就开始使用了, 有很多经典的方法可提高标注的效率,如超像素块算法(Superpixels),分水岭算法(Watershed),GrabCut分割算法等。近几年,研究人员试图用深度学习完成这一任务(link1, link2, link3),这些经典的算法有很多缺陷,需要很多超参数对每一幅图像进行检索,难以对结果进行标准化和修正。最新的基于深度学习的成果要好很多,但在大多情况下这些成果是不开源的。我们是第一个为每个人提供基于AI的标注工具的人,我们自己独立设计了与上边三个links概念类似的神经网络架构。它有一个很大的优势:我们的神经网络不需要对对象实例进行分类。这就意味着,可以对行人、汽车、路面上的凹陷处、医学影像上的肿瘤、室内场景、食物成分、卫星上的物体等等进行分割。
那么,它是如何工作的呢?如下图所示:

你只需要剪裁感兴趣的对象,然后神经网络将会对其进行分割。人机交互非常重要,你可以点击图像的内部和外部标签进行修正错误。
语义分割是将图像划分为多个预定义语义类别的区域,与它不同的是,我们的交互式图像分割旨在根据用户的输入提取其感兴趣的对象。
交互式分割的主要目标是根据用户最少的操作,即可精确的提取对象以改善整体的用户体验,因此我们大大提高了标注的效率。
这是我们的第一次尝试,当然在有些情况下,再好的标注依然会有缺陷。但我们正不断的改进算法,并在领域适应性上做一些简单的设计:在不编码的情况下,为适应内部特定的任务自定义工具。
结语
数据是深度学习的关键,训练数据是费时和高代价的。但是我们和深度学习的团体积极尝试着去解决训练数据的问题,并且成功的迈出了第一步,希望能够在以后提供更好的解决方案。
以上为译文。
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《Big Challenge in Deep Learning:Training Data》,译者:Mags,审校:袁虎。
文章为简译,更为详细的内容,请查看原文