本文从三个方面对 pix2pix 方法做了改进,还将他们的方法扩展到交互式语义操作,这对于传统的图像逼真渲染是一个颠覆性的工作。
如果你对本文工作感兴趣,点击底部的阅读原文即可查看原论文。
关于作者:郑琪,华中科技大学硕士生,研究方向为计算机视觉和自然语言处理。
■ 论文 | High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
■ 链接 | https://www.paperweekly.site/papers/1278
■ 作者 | Aidon
论文导读
现有的用于图像逼真渲染的图形学技术,在构建和编辑虚拟环境时往往非常复杂并且耗时,因为刻画真实的世界要考虑的方面太多。
如果我们可以从数据中学习出一个模型,将图形渲染的问题变成模型学习和推理的问题,那么当我们需要创造新的虚拟环境时,只需要在新的数据上训练我们的模型即可。
之前的一些利用语义标签合成图像的工作存在两个主要问题:1. 难以用 GANs 生成高分辨率图像(比如 pix2pix 方法);2. 相比于真实图像,生成的图像往往缺少一些细节和逼真的纹理。
本文从三个方面对 pix2pix 方法做了改进:一个 coarse-to-fine 生成器,一个 multi-scale 判别器和一个鲁棒的 loss,从而成功合成出 2048 x 1024 的逼真图像。此外,本文还将他们的方法扩展到交互式语义操作,这对于传统的图像逼真渲染是一个颠覆性的工作。
模型介绍
1. The pix2pix Baseline
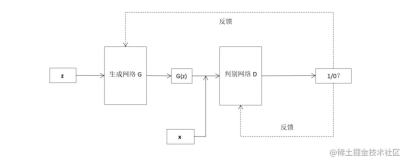
给定语义标签图和对应的真实照片集 (si,xi),该模型中的生成器用于从语义标签图生成出真实图像,而判别器用于区分真实图像和生成的图像,该条件GANs对应的优化问题如下:
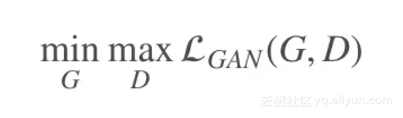
其中:
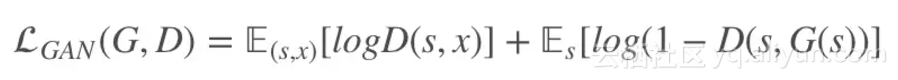
pix2pix 采用 U-Net 作为生成器,在 Cityscapes 数据集上生成的图像分辨率最高只有 256 x 256。
2. Coarse-to-fine 生成器
这里一个基本的想法是将生成器拆分成两个子网络 G={G1,G2}:全局生成器网络 G1 和局部增强网络 G2,前者输入和输出的分辨率保持一致(如 1024 x 512),后者输出尺寸(2048 x 1024)是输入尺寸(1024 x 512)的 4 倍(长宽各两倍)。
以此类推,如果想要得到更高分辨率的图像,只需要增加更多的局部增强网络即可(如 G={G1,G2,G3}),具体的网络结构如图所示:
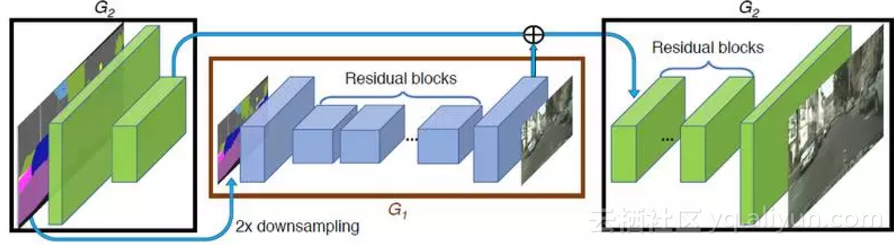
3. Multi-scale 判别器
要在高分辨率下区分真实的与合成的图像,就要求判别器有很大的感受野,这需要更深的网络或者更大的卷积核才能实现,而这两种选择都会增加网络容量从而使网络更容易产生过拟合问题,并且训练所需的存储空间也会增大。
这里用 3 个判别器 {D1,D2,D3} 来处理不同尺度的图像,它们具有相同的网络结构:
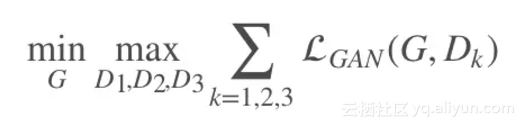
4. 改进的 adversarial loss
由于生成器要产生不同尺度的图像,为使训练更加稳定,这里引入特征匹配损失:
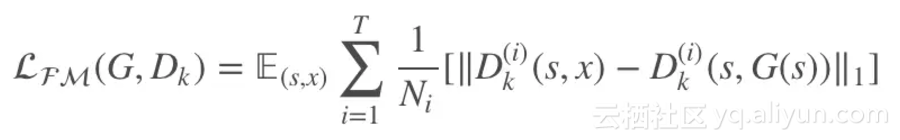
其中表示判别器 Dk 提取的第 i 层特征,T 为总的层数,Ni 为该层总元素的个数。于是,总的目标函数如下:
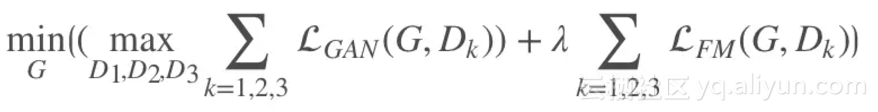
5. 学习 instance-level 的特征嵌入
当前的图像合成方法都只利用了 pixel-level 的语义标签图,这样无法区分同类物体,而 instance-level 的语义标签为每一个单独的物体提供了唯一的标签。
文章指出,示例图(instance map)所提供的最重要的信息其实是物体的边缘。所以本文首先计算出示例边缘图(instance boundary map),如图所示:
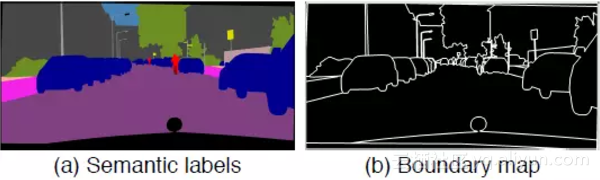
然后将语义标签图和示例边缘图连接起来,输入到生成器网络中。
考虑到一个理想的图像合成算法应该能够从同一个语义标签图产生出多种逼真的图像,而现有的方法无法让用户直观地控制产生什么样的图像,并且不允许 object-level 的控制,于是本文提出将额外的低维特征也输入到生成器网络中。
为此,需要训练一个编码器网络 E,用于确定与真实图像中每个目标示例的低维特征向量,以G(s,E(x)) 代替之前的 G(s),如图所示:
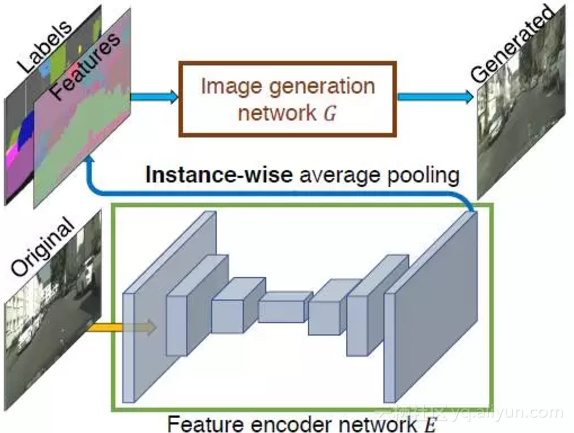
在编码器训练好之后,输入训练图像,找出图像中的所有示例,并记录对应的特征。然后利用 KK-means 聚类得到每一个语义类别的特征编码。推断时,随机选取一个聚类中心作为编码特征,与之前的标签图连接输入到生成器网络中。
实验结果
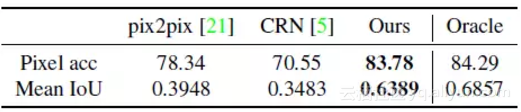
实验中设置 λ=10,K=10,用 3 维向量对示例特征进行编码,采样 LSGANs 用于稳定训练。实验比较了不同的图像合成算法,包括 pix2pix 和 CRN,还比较了加入感知损失(w/o VGG)的结果,其中 F(i) 表示 VGG 网络的第 i 层。
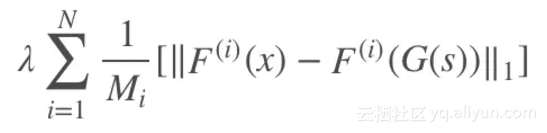
在 Cityscapes 数据集上的实验结果如下:
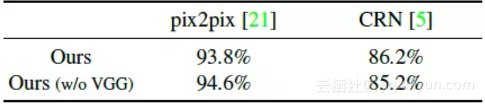
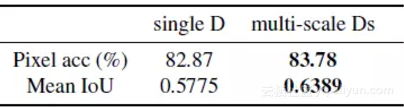

在 NYU Indoor RGBD 数据集上的实验结果如下:


更多关于的实验结果可以阅读原文或者访问 project 网页:
https://tcwang0509.github.io/pix2pixHD/
总结
本文提出了一个有通用性的基于条件 GANs 的网络框架,用于高分辨率图像合成和语义操作。相比于 pix2pix,本文在语义分割结果和图像合成的清晰度以及细节上都有了很大的提升。
原文发布时间为:2017-12-7
本文作者:郑琪
本文来自云栖社区合作伙伴“PaperWeekly”,了解相关信息可以关注“PaperWeekly”微信公众号