MaxCompute2.0(原Odps):通过性能评测,MaxCompute2.0离线计算比同类产品Hive2.0 on Tez性能优势快约90%以上;MaxCompute2.0从新一代执行引擎到编译引擎、基于代价的优化器全流程针对性能提升做出了卓越改进。
本次评测侧重于已发布的MaxCompute2.0与离线处理同类竞品及线上稳定版本的性能对比,通过测试我们看到MaxCompute2.0在功能上更强大、使用和发布更新更高效、开放生态的同时针对线上作业占比80%以上的Sql以及其中占比约50%的Sql离线批量计算性能有极大提升。
一,新一代执行引擎
MaxCompute2.0开发了新一代执行引擎。新的执行引擎是是基于代码生成(Codegen)的执行引擎,同时采用向量化执行和缓存友好的算法。我们可以看到新一代执行引擎执行比开源社区新一代离线计算执行引擎HiveOnTez性能对比优势显著。
我们记录下在MaxCompute2.0新一代执行引擎和社区新一代离线计算执行引擎HiveOnTez中相同数据量上相同数量执行实例处理的操作时间(单位是秒),下面的表格能够体现出新的新一代执行引擎的性能。
可以看到,在总体数据量T级别instance数量(百级别)情况,相同数据量相同数量的instance执行性能,MaxCompute2.0执行的平均执行性能优于Hive2.0OnTez(Hive2.0已调整最优):
1- sum with group性能快速1倍
2-sort-merge join提升约2倍以上
3-hashjoin提升在1倍以上
4-stremline提升50%以上

二,新的编译引擎和基于代价的优化器
MaxCompute2.0开发了全新的解析器和引入了基于代价的优化器,在兼容Hive语法和语义和开发应用各种基于规则的优化器(Rbo)的前提下,引入和开发了基于统计数据指导下精确的optimizer组件,增加了全新的优化规则。
在新的编译引擎和基于代价的优化器下端至端的执行性能进行评测,MaxCompute2.0离线计算对比社区同类产品Hive2.0 on Tez在最优执行下TPC-H benchmark数据: 
测试环境:
1. 集群规模:30台机器测试集群,其中20台计算节点
2. 机器配置:22core\96G\千兆全双工网络\每节点12块1TB SATA硬盘
3. 软件版本:MaxCompute2.0Sp24rc5/hive2.0onTez/MaxCompute1.0Sp23s14/hive2.0onMr
4. 数据规模:1TB(zlib压缩)
为了保证数据的合理性,性能测试数据都是每个测试案例完成多轮测试的稳定值,测试搭建使用独立的性能评测集群,测试前清理恢复初始环境,多轮测试非连续执行,连续执行完整个测试集合后再执行下一轮的测试集合。
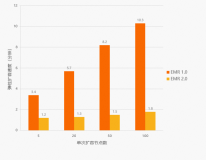
图中整体对比数据为:
1- MaxCompute2.0离线计算比同类产品Hive2.0 on Tez性能优势快约90%以上
2.MaxCompute2.0执行95%以上基准sql执行比hive快,同时我们分析了内部执行细节,去除调度等其他消耗时间,MaxCompute2.0针对执行的性能改进比Hive2.0提升在114%以上
3-MaxCompute2.0比MaxCompute1.0性能提升68%
4-MaxCompute2.0比Hive2.0 on Mr整体优势提升190%,其中77%的基准sql性能提升2x以上

三,MaxCompute2.0性能提升及后续性能衍进期待
1. 兼容社区产品、兼容hive的所有数据类型、遵循SQL 2003、支持多维分组
2. 研发whole-stage code generation,即通过在运行期间优化那些拖慢整个查询的代码到一个单独的函数中,消除函数调用以及利用CPU寄存器来存放那些中间数据等性能消耗
3. 更多得优化规则及已有规则的更新升级, Join Reordering全面默认开启,Range partitioning支持等 基于飞天的一代执行引擎性能有极大提升外,MaxCompute2.0已上线的基于rbo和cbo执行性能优化:
1- 裁剪规则:列裁剪、分区裁剪、子查询裁剪
2- 下推/合并规则:谓词下推
3- 去重规则:Project去重、Exchange去重、Sort去重
4- 常量折叠/谓词推导
5- 关联优化:Auto MapJoin、 Skew Join;实现BroadcastHashJoin、ShuffleHashJoin、MergeJoin;Join Reordering
6- 聚合优化: HashAggregate、SortedAggregate、Deduplicate
7- 处理优化: GroupBy下推、Exchange下推、Sort下推