一、 RocketMQ概述
1. MessageFilter
1) Broker端消息过滤
在Broker中,按照Consumer的要求做过滤,优点是减少了对于Consumer无用消息的网络传输。缺点是增加了Broker的负担,实现相对复杂。
² 淘宝Notify支持多种过滤方式,包含直接按照消息类型过滤,灵活的语法表达式过滤,几乎可以满足最苛刻的过滤需求。
² RocketMQ支持按照简单的Message Tag过滤,也支持按照Message Header、body进行过滤。
² CORBA Notification规范中也支持灵活的语法表达式过滤。
2) Consumer端消息过滤
这种过滤方式可由应用完全自定义实现,但是缺点是很多无用的消息要传输到Consumer端。
2. 消息可靠性
影响消息可靠性的几种情况:
- Broker正常关闭
- Broker异常Crash
- OSCrash
- 机器掉电,但是能立即恢复供电情况。
- 机器无法开机(可能是cpu、主板、内存等关键设备损坏)
- 磁盘设备损坏。
前四种情况都属于硬件资源可立即恢复情况,RocketMQ在这四种情况下能保证消息不丢,或者丢失少量数据(依赖刷盘方式是同步还是异步)。后两种属于单点故障,且无法恢复,一旦发生,在此单点上的消息全部丢失。RocketMQ在这两种情况下,通过异步复制,可保证99%的消息不丢,但是仍然会有极少量的消息可能丢失。通过同步双写技术可以完全避免单点,同步双写势必会影响性能,适合对消息可靠性要求极高的场合,例如与Money相关的应用。
RocketMQ从3.0版本开始支持同步双写。
3. 消息原语
1) At most once
最多一次,发送一次,无论成败,将不会重发。
2) At least Once
消息投递后,如果未能收到ack,则再次投递。
每个消息必须投递一次RocketMQ Consumer先pull消息到本地,消费完成后,才向服务器返回ack,如果没有消费一定不会ack消息,所以RocketMQ可以很好的支持此特性。
3) Exactly Only Once
² 发送消息阶段,不允许发送重复的消息。
² 消费消息阶段,不允许消费重复的消息。
只有以上两个条件都满足情况下,才能认为消息是“Exactly Only Once”,而要实现以上两点,在分布式系统环境下,不可避免要产生巨大的开销。所以RocketMQ为了追求高性能,并不保证此特性,要求在业务上进行去重,也就是说消费消息要做到幂等性。RocketMQ虽然不能严格保证不重复,但是正常情况下很少会出现重复发送、消费情况,只有网络异常,Consumer启停等异常情况下会出现消息重复。
此问题的本质原因是网络调用存在不确定性,即既不成功也不失败的第三种状态,所以才产生了消息重复性问题。
4. 回溯消费
是指Consumer已经消费成功的消息,由于业务上需求需要重新消费,要支持此功能,Broker在向Consumer投递成功消息后,消息仍然需要保留。并且重新消费一般是按照时间维度,例如由于Consumer系统故障,恢复后需要重新消费1小时前的数据,那么Broker要提供一种机制,可以按照时间维度来回退消费进度。RocketMQ支持按照时间回溯消费,时间维度精确到毫秒,可以向前回溯,也可以向后回溯。
5. 消息堆积
消息中间件的主要功能是异步解耦,还有个重要功能是挡住前端的数据洪峰,保证后端系统的稳定性,这就要求消息中间件具有一定的消息堆积能力,消息堆积分以下两种情况:
消息堆积在内存Buffer,一旦超过内存Buffer,可以根据一定的丢弃策略来丢弃消息,如CORBA Notification规范中描述。适合能容忍丢弃消息的业务,这种情况消息的堆积能力主要在于内存Buffer大小,而且消息堆积后,性能下降不会太大,因为内存中数据多少对于对外提供的访问能力影响有限。
消息堆积到持久化存储系统中,例如DB,KV存储,文件记录形式。当消息不能在内存Cache命中时,要不可避免的访问磁盘,会产生大量读IO,读IO的吞吐量直接决定了消息堆积后的访问能力。
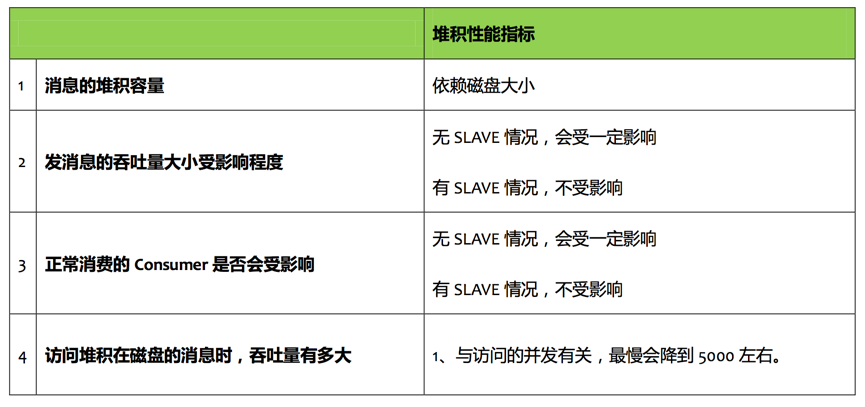
评估消息堆积能力主要有以下四点:
² 消息能堆积多少条,多少字节?即消息的堆积容量。
² 消息堆积后,发消息的吞吐量大小,是否会受堆积影响?
² 消息堆积后,正常消费的Consumer是否会受影响?
² 消息堆积后,访问堆积在磁盘的消息时,吞吐量有多大?
6. 分布式事务
常见的分布式事务解决方案有:最终一致性,两阶段/三界阶段提交,TCC,本地消息表等。这些解决方案中,最终以执行的性能最好。可以通过RocketMQ实现最终一致性。
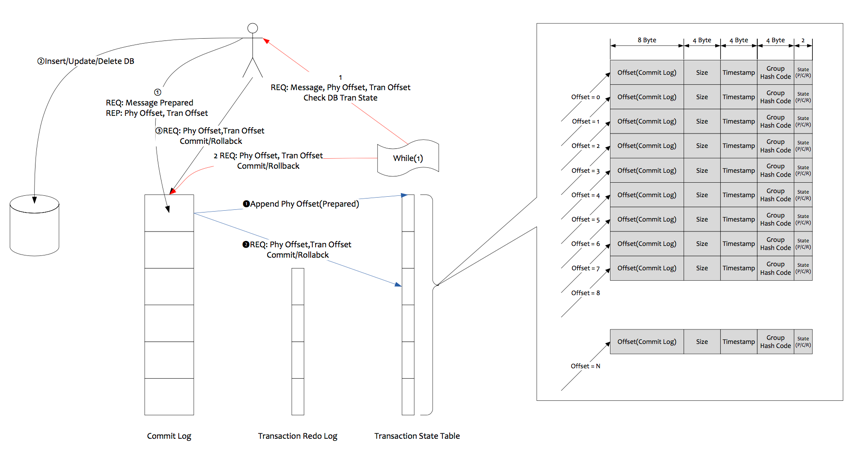
分布式事务涉及到两阶段提交问题,在数据存储方面的方面必然需要KV存储的支持,因为第二阶段的提交回滚需要修改消息状态,一定涉及到根据Key去查找Message的动作。RocketMQ在第二阶段绕过了根据Key去查找Message的问题,采用第一阶段发送Prepared消息时,拿到了消息的Offset,第二阶段通过Offset去访问消息,并修改状态,Offset就是数据的地址。
RocketMQ这种实现事务方式,没有通过KV存储做,而是通过Offset方式,存在一个显著缺陷,即通过Offset更改数据,会令系统的脏页过多,需要特别关注。
7. 定时消息
定时消息是指消息发到Broker后,不能立刻被Consumer消费,要到特定的时间点或者等待特定的时间后才能被消费。
如果要支持任意的时间精度,在Broker层面,必须要做消息排序,如果再涉及到持久化,那么消息排序要不可避免的产生巨大性能开销。
RocketMQ支持定时消息,但是不支持任意时间精度,支持特定的level,例如定时5s,10s,1m等。
8. 消息重试
Consumer消费消息失败后,要提供一种重试机制,令消息再消费一次。Consumer消费消息失败通常可以认为有以下几种情况
² 由于消息本身的原因,例如反序列化失败,消息数据本身无法处理(例如话费充值,当前消息的手机号被注销,无法充值)等。因为这条失败的消息即使立刻重试消费,99%也不成功,所以通常需要跳过这条消息,接着消费其他消息。
² 由于依赖的下游应用服务不可用,例如db连接不可用,外系统网络不可达等。遇到这种错误,即使跳过当前失败的消息,消费其他消息同样也会报错。这种情况建议应用sleep30s,再消费下一条消息,这样可以减轻Broker重试消息的压力。
二、 RocketMQ特点
1. RocketMQ特点
是一个队列模型的消息中间件,具有高性能、高可靠、高实时、分布式特点。
² Producer、Consumer队列都可以分布式。
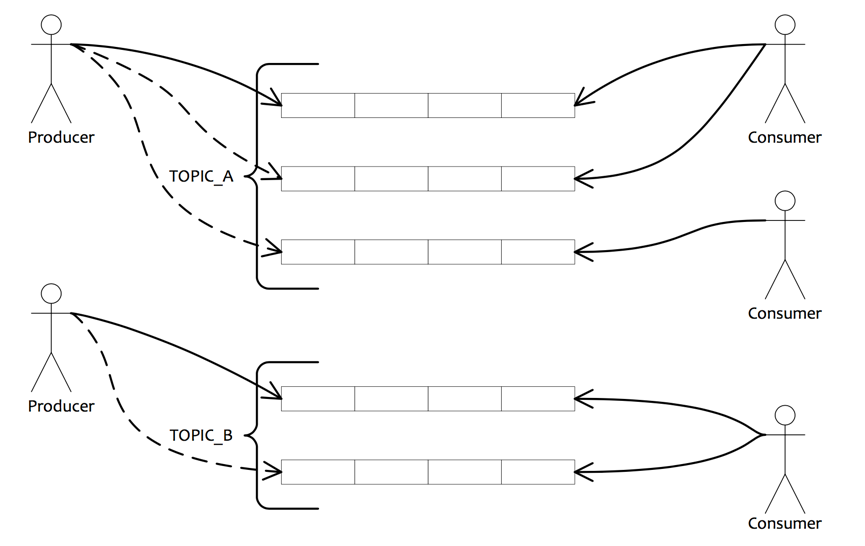
² Producer向一些队列轮流发送消息,队列集合称为Topic,Consumer如果做广播消费,则一个consumer 实例消费这个Topic对应的所有队列,如果做集群消费,则多个Consumer实例平均消费这个topic对应的 队列集合。
² 能够保证严格的消息顺序
² 提供丰富的消息拉取模式
² 高效的订阅者水平扩展能力
² 实时的消息订阅机制
² 亿级消息堆积能力
2. 消息发送、消费模型
三、 RocketMQ原理
1. 零拷贝原理
Consumer消费消息过程,使用了零拷贝,零拷贝包含以下两种方式:
1) 使用mmap+write方式
² 优点
即使频繁调用,使用小块文件传输,效率也很高
² 缺点
不能很好的利用DMA方式,会比sendfile多消耗CPU,内存安全性控制复杂,需要避免JVM Crash问题。
2) 使用sendfile方式
² 优点
可以利用DMA方式,消耗CPU较少,大块文件传输效率高,无内存安全新问题。
² 缺点
小块文件效率低于mmap方式,只能是BIO方式传输,不能使用NIO。
RocketMQ选择了第一种方式,mmap+write方式,因为有小块数据传输的需求,效果会比sendfile更好。
2. 文件系统
RocketMQ选择LinuxExt4文件系统,原因:Ext4文件系统删除1G大小的文件通常耗时小于50ms,而Ext3文件系统耗时约1s左右,且删除文件时,磁盘IO压力极大,会导致IO写入超时。
文件系统层面需要做以下调优措施文件系统IO调度算法需要调整为deadline,因为deadline算法在随机读情况下,可以合并读请求为顺序跳跃方式,从而提高读IO吞吐量。
3. 数据存储结构
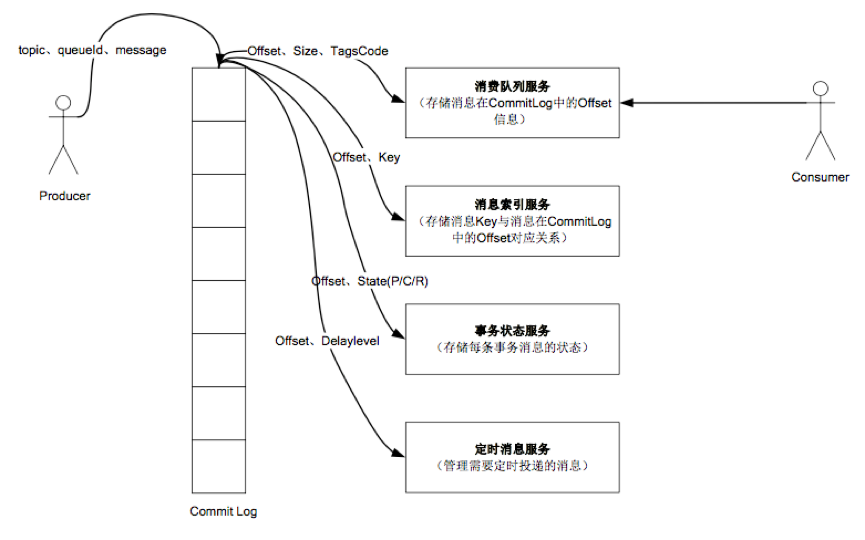
4. RocketMQ队列
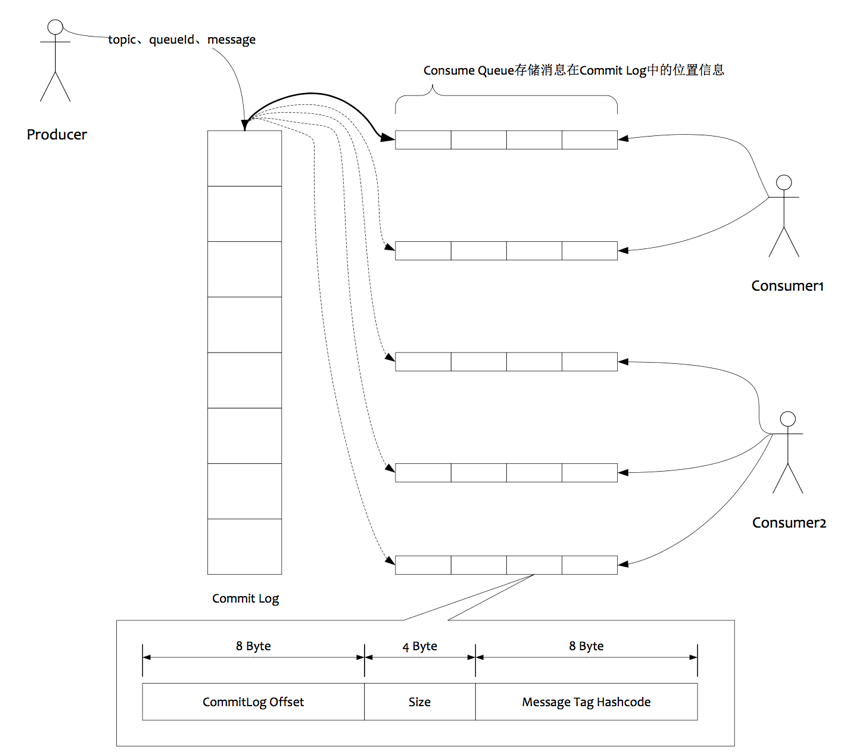
1) RocketMQ队列
² 所有数据单独存储到一个Commit Log,完全顺序写,随机读。
² 对最终用户展现的队列实际只存储消息在Commit Log的位置信息,并且串行方式刷盘。
2) 优点
² 队列轻量化,单个队列数据量非常少。
² 对磁盘的访问串行化,避免磁盘竟争,不会因为队列增加导致IO WAIT增高。
3) 缺点
- 写虽然完全是顺序写,但是读却变成了完全的随机读。
- 读一条消息,会先读Consume Queue,再读Commit Log,增加了开销。
- 要保证Commit Log与Consume Queue完全的一致,增加了编程的复杂度。
4) 缺点解决方案
- 随机读,尽可能让读命中PAGECACHE,减少IO读操作,所以内存越大越好。如果系统中堆积的消息过多,读数据要访问磁盘会不会由于随机读导致系统性能急剧下降,答案是否定的。
a) 访问PAGECACHE时,即使只访问1k的消息,系统也会提前预读出更多数据,在下次读时,就可能命中内存。
b) 随机访问Commit Log磁盘数据,系统IO调度算法设置为NOOP方式,会在一定程度上将完全的随机读变成顺序跳跃方式,而顺序跳跃方式读较完全的随机读性能会高5倍以上。
c) 另外4k的消息在完全随机访问情况下,仍然可以达到8K次每秒以上的读性能。
- 由于Consume Queue存储数据量极少,而且是顺序读,在PAGECACHE预读作用下,Consume Queue的读性能几乎与内存一致,即使堆积情况下。所以可认为ConsumeQueue完全不会阻碍读性能。
- CommitLog中存储了所有的元信息,包含消息体,类似于Mysql、Oracle的redolog,所以只要有Commit Log在,Consume Queue即使数据丢失,仍然可以恢复出来。
5. 刷盘策略
RocketMQ的所有消息都是持久化的,先写入系统PAGECACHE,然后刷盘,可以保证内存与磁盘都有一份数据,访问时直接从内存读取。
1) 异步刷盘
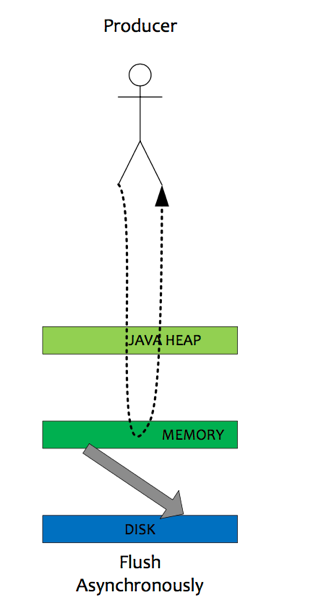
在有RAID卡,SAS15000转磁盘测试顺序写文件,速度可以达到300M每秒左右,而线上的网卡一般都为千兆网卡,写磁盘速度明显快于数据网络入口速度,那么是否可以做到写完内存就向用户返回,由后台线程刷盘呢?
a) 由于磁盘速度大于网卡速度,那么刷盘的进度肯定可以跟上消息的写入速度。
b) 万一由于此时系统压力过大,可能堆积消息,除了写入IO,还有读取IO,万一出现磁盘读取落后情况,会不会导致系统内存溢出,答案是否定的,原因如下:
² 写入消息到PAGECACHE时,如果内存不足,则尝试丢弃不干净的PAGE,腾出内存供新消息使用,策略是LRU方式。
² 如果干净页不足,此时写入PAGECACHE会被阻塞,系统尝试刷盘部分数据,大约每次尝试32个PAGE,来找出更多干净PAGE。
综上,内存溢出的情况不会出现。
2) 同步刷盘
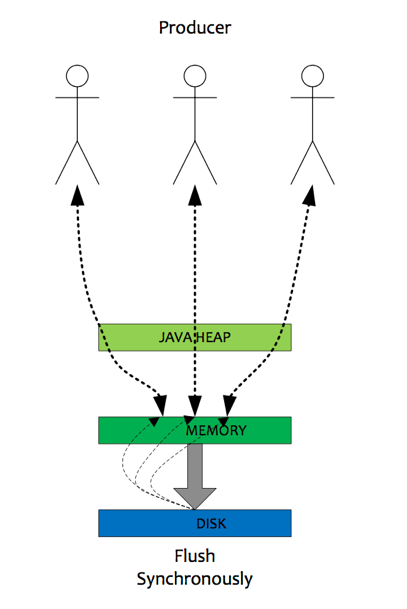
同步刷盘与异步刷盘的唯一区别是异步刷盘写完PAGECACHE直接返回,而同步刷盘需要等待刷盘完成才返回,同步刷盘流程如下:
- 写入PAGECACHE后,线程等待,通知刷盘线程刷盘。
- 刷盘线程刷盘后,唤醒前端等待线程,可能是一批线程。
- 前端等待线程向用户返回成功。
6. 消息查询
1) 按照Message Id查询消息
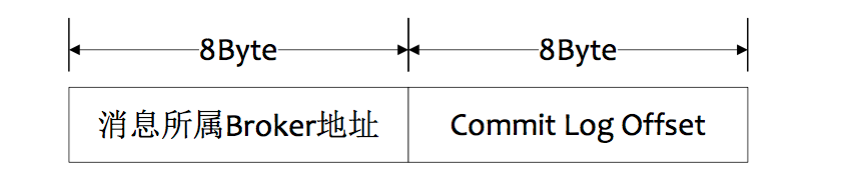
msgId的数据结构
MsgId总共16字节,包含消息存储主机地址,消息Commit Log offset。从 MsgId中解析出 Broker 的地址和CommitLog的偏移地址,然后按照存储格式所在位置消息buffer解析成一个完整的消息。
2) 按照Message Key查询消息
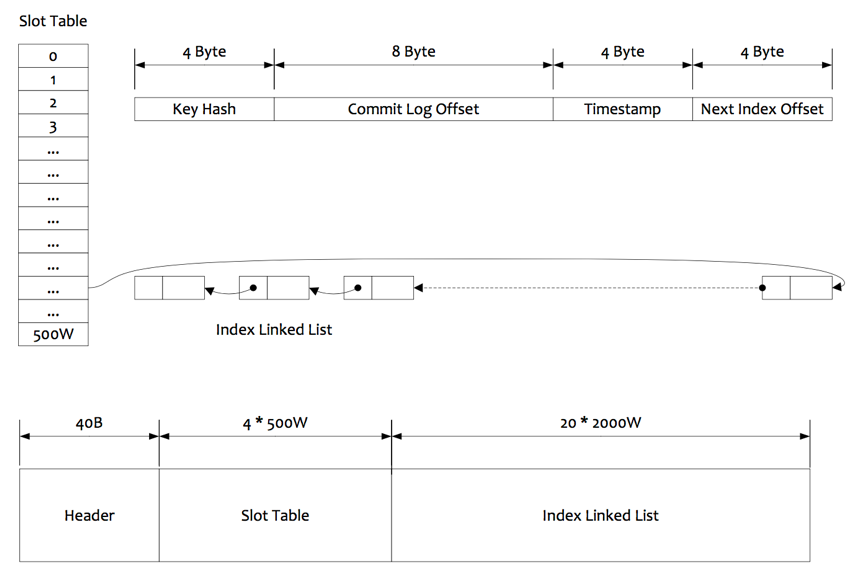
索引的逻辑结构,类似HashMap实现。
根据查询的key的hashcode % slotNum得到具体的槽的位置(slotNum是一个索引文件里面包含的最大槽的数目,例如图中所示slotNum=5000000)。
根据slotValue(slot位置对应的值)查找到索引项列表的最后一项(倒序排列,slotValue总是指向最新的一个索引项)。
遍历索引项列表返回查询时间范围内的结果集(默认一次最大返回的32条记录)
Hash冲突;寻找key的slot位置时相当于执行了两次散列函数,一次key的hash,一次key的hash值取模, 因此这里存在两次冲突的情况;第一种,key的hash值不同但模数相同,此时查询的时候会在比较一次key的hash值(每个索引项保存了key的hash值),过滤掉hash值不相等的项。第二种,hash值相等但key不等,出于性能的考虑冲突的检测放到客户端处理(key的原始值是存储在消息文件中的,避免对数据文件的解析),客户端比较一次消息体的key是否相同。
存储;为了节省空间,索引项中存储的时间是时间差值(存储时间-开始时间,开始时间存储在索引文件头中),整个索引文件是定长的,结构也是固定的。
7. 服务器消息过滤
RocketMQ的消息过滤方式有别于其他消息中间件,是在订阅时再做过滤,先来看下Consume Queue的存储

在Broker端进行Message Tag比对,先遍历Consume Queue,如果存储的Message Tag与订阅的Message Tag不符合,则跳过,继续比对下一个,符合则传输给Consumer。注意:Message Tag是字符串形式,Consume Queue中存储的是其对应的hashcode,比对时也是比对hashcode。
Consumer收到过滤后的消息后,同样也要执行在Broker端的操作,但是比对的是真实的MessageTag字符串,而不是Hashcode。
为什么过滤要这样做?
² MessageTag存储Hashcode,是为了在ConsumeQueue定长方式存储,节约空间。
² 过滤过程中不会访问CommitLog数据,可以保证堆积情况下也能高效过滤。
² 即使存在Hash冲突,也可以在Consumer端进行修正,保证万无一失。
8. 事务消息
9. 发送消息负载均衡
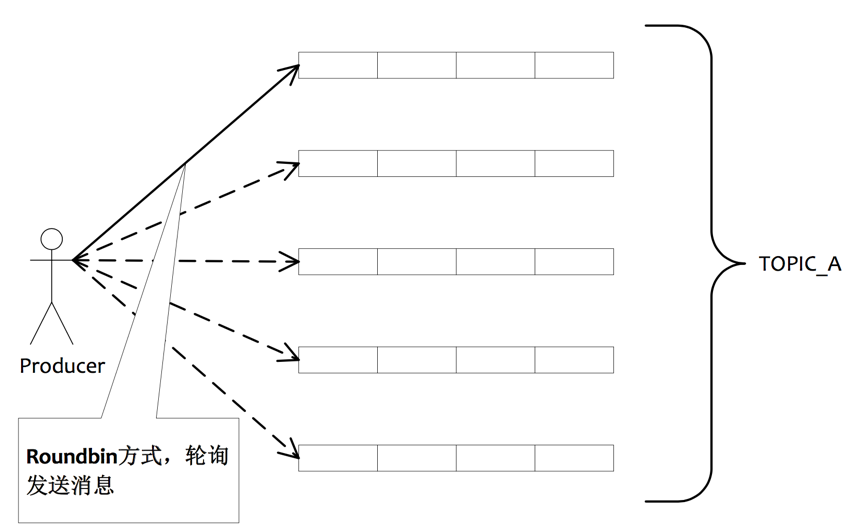
5个队列可以部署在一台机器上,也可以分别部署在5台不同的机器上,发送消息通过轮询队列的方式
发送,每个队列接收平均的消息量。通过增加机器,可以水平扩展队列容量。另外也可以自定义方式选择发往哪个队列。
10.订阅消息负载均衡
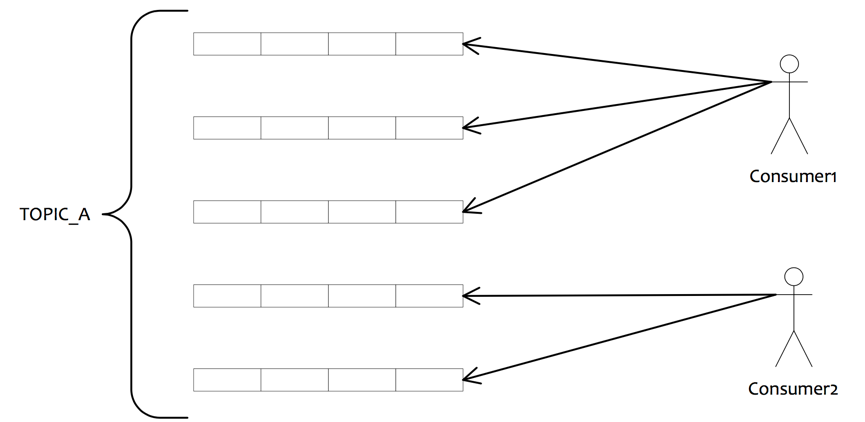
如果有5个队列,2个consumer,那么第一个Consumer消费3个队列,第二consumer消费2个队列。
这样即可达到平均消费的目的,可以水平扩展Consumer来提高消费能力。但是Consumer数量要小于等于队列数量,如果Consumer超过队列数量,那么多余的Consumer将不能消费消息。
11.单队列并行消费
单队列并行消费采用滑动窗口方式并行消费,如图所示,3~7的消息在一个滑动窗口区间,可以有多个线程并行消费,但是每次提交的Offset都是最小Offset,如下图

12.同步双写/异步复制
异步复制的实现思路非常简单,Slave启动一个线程,不断从Master拉取CommitLog中的数据,然后在异步build出Consume Queue数据结构。整个实现过程基本同Mysql主从同步类似。
13.充分利用服务器内存
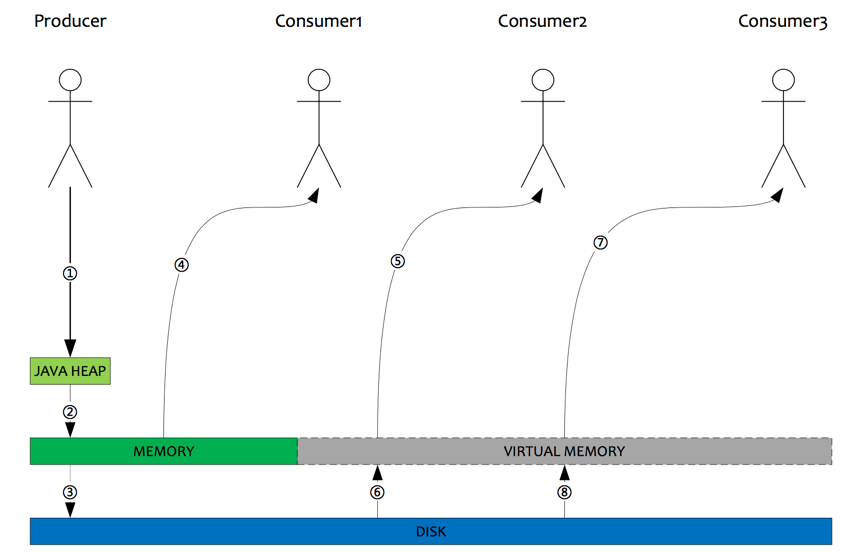
- Producer发送消息,消息从socket进入java堆。
- Producer发送消息,消息从java堆转入PAGACACHE,物理内存。
- Producer发送消息,由异步线程刷盘,消息从PAGECACHE刷入磁盘。
- Consumer拉消息(正常消费),消息直接从PAGECACHE(数据在物理内存)转入socket,到达consumer,不经过java堆。这种消费场景最多,线上96G物理内存,按照1K消息算,可以在物理内存缓存1亿条消息。
- Consumer拉消息(异常消费),消息直接从PAGECACHE(数据在虚拟内存)转入socket。
- Consumer拉消息(异常消费),由于Socket访问了虚拟内存,产生缺页中断,此时会产生磁盘IO,从磁盘Load消息到PAGECACHE,然后直接从socket发出去。
- 同5一致。
- 同6一致。
14.消息堆积问题解决办法
衡量消息中间件堆积能力的几个指标:
在有Slave情况下,Master一旦发现Consumer访问堆积在磁盘的数据时,会向Consumer下达一个重定向指令,令Consumer从Slave拉取数据,这样正常的发消息与正常消费的Consumer都不会因为消息堆积受影响,因为系统将堆积场景与非堆积场景分割在了两个不同的节点处理。这里会产生另一个问题,Slave会不会写性能下降,答案是否定的。因为Slave的消息写入只追求吞吐量,不追求实时性,只要整体的吞吐量高就可以,而Slave每次都是从Master拉取一批数据,如1M,这种批量顺序写入方式即使堆积情况,整体吞吐量影响相对较小,只是写入RT会变长。
四、 参考资料
1. 文档
RocketMQ_design.pdf
RocketMQ_experience.pdf
2. 博客
分布式开放消息系统(RocketMQ)的原理与实践
http://www.jianshu.com/p/453c6e7ff81c
ZeroCopy
http://www.linuxjournal.com/article/6345
IO方式的性能数据
http://stblog.baidu-tech.com/?p=851
Ext4文件系统有以下Bug,请注意