
我们再来看重新定义JOIN后如何能够提高运算性能,先看外键式JOIN的情况。
设有两个表:

其中sales表中的productid是指向products表中id字段的外键,id是products表的主键。
现在我们想计算销售额有多少(为简化讨论,就不再设定条件了),用SQL写出来:
SELECT SUM(sales.quantity*products.price) FROM sales JOIN products ON sales.productid=products.id
基于笛卡尔积定义的JOIN,原则上只能两层循环全遍历来计算,不过这个计算量实在太大,关系数据库一般采用HASH分段方法优化,即分别计算两表关联字段的HASH值,将HASH同值记录拼到一起再做小范围遍历。网上有很多文章介绍这个算法,这里就不详述了。这样做后的复杂度能显著降低,但仍然要做多次HASH值计算和比对。
我们再用前述的简化的JOIN语法写出这个运算:
SELECT SUM(quantity*productid.price) FROM sales
而这个写法其实也就预示了它还可以有更好的优化方案,下面来看看怎样实现。
我们先考虑全内存的情况,如果所有数据都能够装入内存,我们可以实现外键指针化。
将事实表sales中的外键字段productid,转换成指向维表products记录的指针,即productid的取值就已经是某个products表中的记录,那么就可以直接引用记录的字段进行计算了。
用SQL不方便描述这个运算的细节过程了,我们采用过程式语法、并用文件作为数据源来说明计算过程:
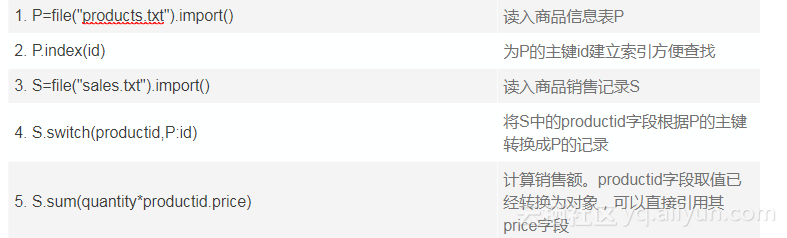
上面算法中,第2步建主键索引一般也是用HASH办法,对id计算HASH值,第4步转换指针还是计算productid的HASH值与P的HASH索引表对比。这样的话,如果只做一次关联运算,指针化的方案和传统HASH分段方案的计算量基本上一样,没有根本优势。
但不同的是,如果数据能在内存中放下,这个指针一旦建立起来之后可以复用,也就是说第2和第4步只要做一次,下次再做关于这两个字段的关联运算时就不必再计算HASH值和比对了,性能就能大幅提高。而关系代数体系下没有对象指针这个概念,并且基于笛卡尔积定义的JOIN运算也无法假定外键指向记录的唯一性,没办法使用外键指针化的方法,每次关联时都要计算HASH值并比对。
而且,如果事实表中有多个外键分别指向多个维表,传统的HASH分段JOIN方案每次只能解析掉一个,有N个JOIN要执行N遍动作,每次关联后都需要保持中间结果供下一轮使用,计算过程复杂得多,数据也会被遍历多次。而外键指针化方案在面对多个外键时,只要对事实表遍历一次, 没有中间结果,计算过程要清晰很多。
还有一点,内存本来应当是很适合并行计算的,但HASH分段JOIN算法却不容易并行。即使把数据分段并行计算HASH值,但要把相同HASH值的记录归聚到一起供下一轮比对,就会发生共享资源冲突的事情,这会把并行计算的优势完全抵消掉。而外键式JOIN模型下,关联两表的地位不对等,明确区分出维表和事实表后,只要简单地将事实表分段就可以并行计算。
将HASH分段技术参照外键属性方案进行改造后,也能一定程度地改善多外键一次解析和并行能力,有些数据库能在工程层面上实施这种优化。不过,这种优化在只有两个表JOIN时问题不大,在有很多表及各种JOIN混在一起时,数据库并不容易识别出应当把哪个表当作事实表去并行遍历、而把其它表当作维表建立HASH索引,这时优化并不总是有效的。所以我们经常会发现当JOIN的表变多时性能会急剧下降的现象(常常到四五个表时就会发生,结果集并无显著增大)。而从JOIN模型上引入外键概念后,将这种JOIN专门处理时,就总能分清事实表和维表,更多的JOIN表只会导致性能的线性下降。
内存数据库是当前比较火热的技术,但上述分析表明,采用SQL模型的内存数据库在JOIN运算上是很难快起来的!
原文发布时间为:2017-12-5
本文作者:蒋步星
