英伟达和UC Berkeley的研究者最近公开一个名为pix2pixHD的“用条件GAN进行2048x1024分辨率的图像合成和处理”项目,并公开了论文和代码。pix2pixHD能够利用语义标注图还原接近真实的现实世界图像,例如街景图、人脸图像等,并且只需简单的操作即可修改和搭配图像。
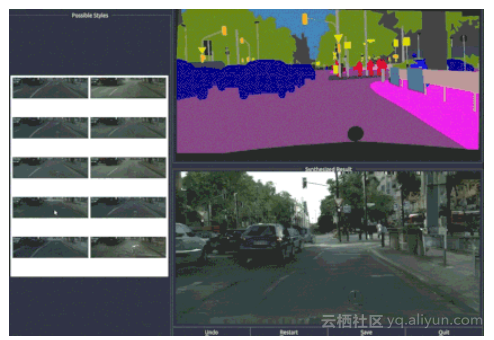
图:上方是输入的语义地图,下方是pix2pixHD合成图像
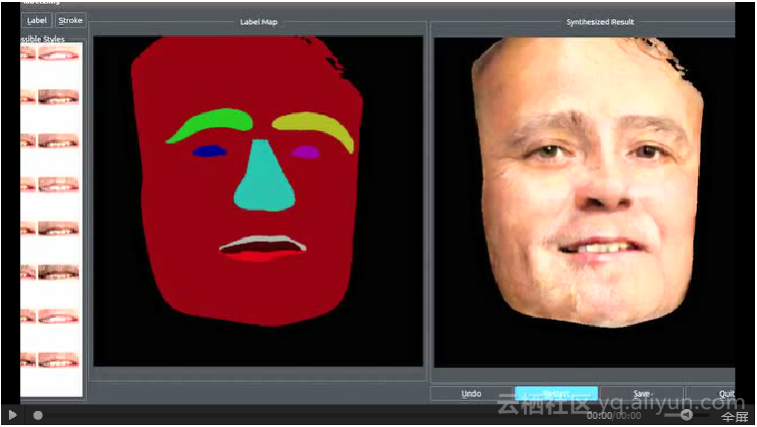
作者发布的视频介绍中,可以看到,你可以选择更换街景中车辆的颜色和型号,给街景图增加一些树木,或者改变街道类型(例如将水泥路变成十字路)。类似地,利用语义标注图合成人脸时,给定语义标注的人脸图像,你可以选择组合人的五官,调整大小肤色,添加胡子等。

图:左下角是人脸的语义标注图,pix2pixHD合成各种不同五官、接近真实的人脸图像。
视频介绍:
论文:High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
作者:Ting-Chun Wang¹, Ming-Yu Liu¹, Jun-Yan Zhu², Andrew Tao¹, Jan Kautz¹, Bryan Catanzaro¹
¹NVIDIA Corporation ²UC Berkeley
摘要
本文提出了一种利用条件生成对抗网络(conditional GANs)来合成高分辨率、照片级真实的图像的新方法。条件GAN已经实现了各种各样的应用,但是结果往往是低分辨率的,而且也缺乏真实感。在这项工作中,我们的方法生成了2048x1024分辨率的视觉上非常棒的效果,利用新的对抗损失,以及新的多尺度生成器和判别器架构。此外,我们还将我们的框架扩展到具有两个附加特征的交互式可视化操作。首先,我们合并了对象实例分割信息,这些信息支持对象操作,例如删除/添加某个对象或更改对象类别。其次,我们提出了一种方法,可以在给定相同输入条件下生成不同的结果,允许用户交互式地编辑对象的外观。人类意见研究(human opinion study)表明,我们的方法显著优于现有的方法,既提高了图像的质量,也提高了图像合成和编辑的分辨率。

图1:我们提出了一个利用语义标注图(上图(a)的左下角)合成2048×1024分辨率图像的生成对抗框架。与以前的工作相比,我们的结果表现出更自然的纹理和细节。(b)我们可以在原始标签地图上改变标签来创建新的场景,例如用建筑物替换树木。(c)我们的框架还允许用户编辑场景中单个对象的外观,例如改变汽车的颜色或道路的纹理。请访问网站进行更多的对比和交互式编辑演示。
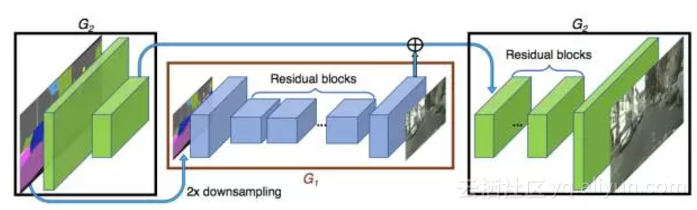
图2:生成器的网络架构。我们首先在较低分辨率的图像上训练一个残差网络G₁。 然后,将另一个残差网络G₂附加到G₁,然后两个网络在高分辨率图像上进行联合训练。具体来说,G₂中的残差块的输入是来自G₂的特征映射和来自G₁的最后一个特征映射的元素和。
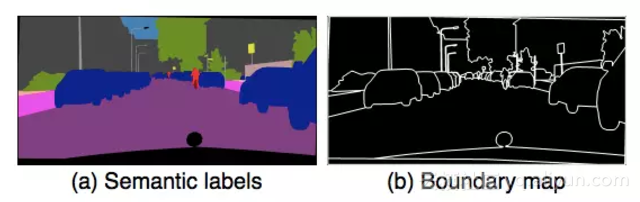
图3:使用实例图(instance map):(a)一个典型的语义标签图。请注意,所有汽车都有相同的标签,这使得它们很难区分开来。(b)提取的实例边界图。有了这些信息,更容易区分不同的对象。

图4:没有实例映射(instance map)和带有实例映射的结果之间的比较。可以看出,当添加实例边界信息时,相邻车辆的边界更加清晰。
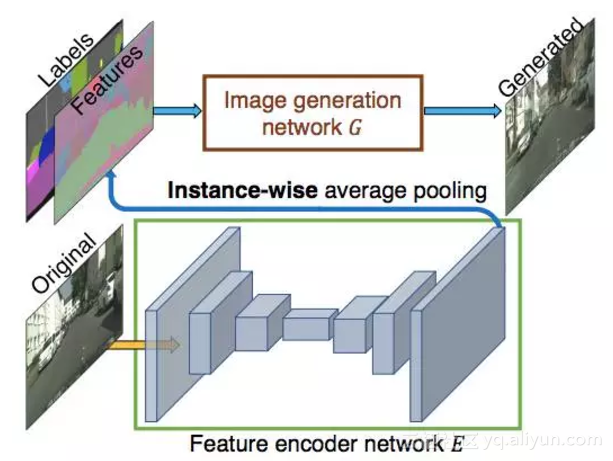
图5:除了用于生成图像的标签之外,还使用 instance-wise特征。
结果
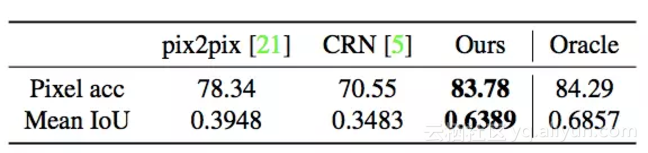
表1:Cityscapes 数据集上不同方法得出的结果的语义分割得分。我们的结果大大优于其他方法,并且非常接近原始图像的准确率(即Oracle)。

图7:在Cityscapes数据集上的比较(语义标注图显示在(a)的左下角)。对于有VGG损失和没有VGG损失,我们的结果比其他两种方法更接近真实。可以放大图片查看更多细节。

图8:在NYU数据集上的比较。我们的方法比其他方法生成的图像更加逼真、色彩更丰富。
讨论和结论
本研究的结果表明,条件GAN(conditional GAN)能够合成高分辨率、照片级逼真的图像,而不需要任何手工损失或预训练的网络。我们已经观察到,引入perceptual loss可以稍微改善结果。我们的方法可以实现许多应用,并且可能对需要高分辨率结果,但是预训练的网络不可用的领域有潜在的用处,例如医学成像和生物学领域。
本研究还表明,可以扩展图像-图像的合成流程以产生不同的输出,并且在给定适当的训练输入 - 输出对(例如本例中的实例图)的情况下实现交互式图像处理。我们的模型从未被告知什么是“纹理”,但能学习将不同的对象风格化,这也可以推广到其他数据集(即,使用一个数据集中的纹理来合成另一个数据集中的图像)。我们相信这些贡献拓宽了图像合成的领域,并可以应用于许多其他相关的研究领域。
原文发布时间为:2017-12-3
本文作者:马文
本文来自云栖社区合作伙伴新智元,了解相关信息可以关注“AI_era”微信公众号


