本文是一个通过模拟预测股票,教会大家如何动手操作TensorFlow的教程,结果不具有权威性。因为股票价格的实际预测是一项非常复杂的任务,尤其是像本文这种按分钟的预测。
导入并预处理数据
我们的团队从我们的抓取服务器中的数据并csv格式的保存。数据集包含n = 41266分钟的数据,从2017年4月到8月,500只股票,以及标准普尔500指数成份股。指数和股票以宽格式排列。
1
# Import data
2
data = pd.read_csv('data_stocks.csv')
3
# Drop date variable
4
data = data.drop(['DATE'], 1)
5
# Dimensions of dataset
6
n = data.shape[0]
7
p = data.shape[1]
数据已经被清理并预处理完毕,缺失的股票和指数价格已经被LOCF(末次观测值结转法),这样文件里就没有任何缺失值了。
使用pyplot.plot(‘SP500’)可以快速查看标准普尔时间序列:
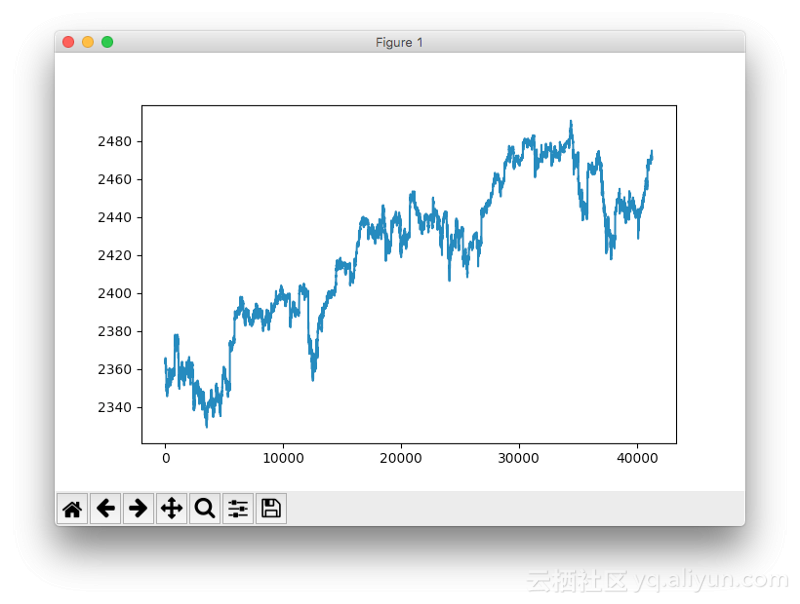
标准普尔500指数的时间序列图
注:这实际上是标准普尔500指数的主要指标,也就是说,它的值向未来移动了1分钟。因为我们想要预测下一分钟的指数,这个操作是必须的。
准备训练和测试数据
数据集被分成训练集和测试集。训练数据为总数据集的80%。数据不进行打乱,而是按顺序切片。训练数据可以从2017年4月选取到2017年7月底,测试数据则选取到2017年8月底为止。
1
# Training and test data
2
train_start = 0
3
train_end = int(np.floor(0.8*n))
4
test_start = train_end + 1
5
test_end = n
6
data_train = data[np.arange(train_start, train_end), :]
7
data_test = data[np.arange(test_start, test_end), :]
对时间序列的交叉验证有很多不同的方法,比如不带有refitting或更复杂概念的滚动预测,或者时间序列引导重采样。后者涉及时间序列的周期性分解的重复样本,以便模拟遵循与原始时间序列相同的周期性模式样本,但这并不是完全的复制他们的值。
数据缩放
大多数神经网络架构能受益于标准化或归一化输入(有时也是输出)。因为网络的神经元使用tanh或sigmoid(最常见的激活函数)分别定义在[-1, 1]或[0, 1]区间。目前,ReLu(Rectified Linear Units)激活函数十分常用,它在激活值的轴上没有上界。但无论如何,我们都会调整输入和目标值。在Python中使用sklearn中的MinMaxScaler可实现缩放。
01
# Scale data
02
from sklearn.preprocessing import MinMaxScaler
03
scaler = MinMaxScaler()
04
scaler.fit(data_train)
05
scaler.transform(data_train)
06
scaler.transform(data_test)
07
# Build X and y
08
X_train = data_train[:, 1:]
09
y_train = data_train[:, 0]
10
X_test = data_test[:, 1:]
11
y_test = data_test[:, 0]pycharm
备注:缩放哪部分的数据以及何时缩放都需要谨慎决定。常见的错误是在训练和测试拆分完成之前缩放整个数据集。因为缩放调用了统计数据,例如向量的最大或最小值。而在现实生活中进行时间序列预测时,预测时没有来自未来观测的信息。因此,必须对训练数据进行缩放统计计算,然后必须应用于测试数据。否则,在预测时使用未来的信息,通常偏向于正向预测指标。
TensorFlow简介
TensorFlow是一个深度学习和神经网络中处于领先地位的计算框架。它底层基于C++,通常通过Python进行控制(也有用于R语言的)。TensorFlow以底层计算任务的图形表示进行操作。这种方法允许用户将数学运算指定数据,变量和运算符作为图中的元素。由于神经网络实际上是数据图和数学运算,因此TensorFlow非常适合神经网络和深度学习。看看这个简单的例子:
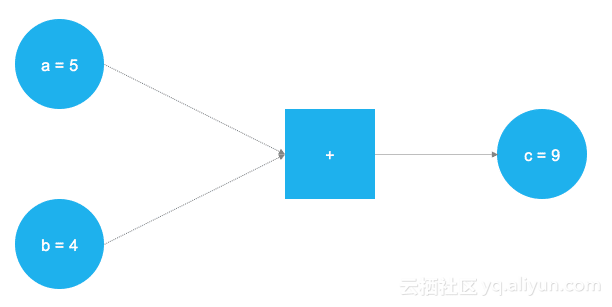
一个非常简单的图表,将两个数字相加。
在上图中,添加两个数字。这些数字存储在两个变量,a和b中。这些数字存储在两个变量a和b中,这两个值通过图形流动,到达了标有加号的正方形节点然后相加。相加的结果被存储到变量c中。其实a,b和c可以被视为占位符。任何被输入到a和b的值都会相加并储存到c中。这就是TensorFlow的工作原理。用户通过占位符和变量来定义模型(神经网络)的抽象表示。然后占位符用实际数据“填充”,并发生实际计算。以下代码在实现上图的简单示例:
01
# Import TensorFlow
02
import tensorflow as tf
03
04
# Define a and b as placeholders
05
a = tf.placeholder(dtype=tf.int8)
06
b = tf.placeholder(dtype=tf.int8)
07
08
# Define the addition
09
c = tf.add(a, b)
10
11
# Initialize the graph
12
graph = tf.Session()
13
14
# Run the graph
15
graph.run(c, feed_dict{a: 5, b: 4})
导入了TensorFlow库,然后用tf.placeholder()定义了两个占位符。使它之们对应于上图中左侧的两个蓝色圆圈。之后,通过定义数学加法tf.add()。计算结果为c = 9。设置占位符后,可以在篮圈中使用任何整数值来执行a和b。当然,这只是简单的例子。神经网络真正需要的图形和计算要复杂得多。
占位符
我们需要从占位符。为了适应我们的模型,我们需要两个占位符:X包含网络的输入(在T = t时所有标准普尔500成份股的价格)和Y网络输出(T = t + 1标准普尔500指数的指数)。
占位符的形状为[None, n_stocks]和[None],表示输入是一个二维矩阵,输出是一维向量。要正确地设计出神经网络所需的输入和输出维度,了解这些是至关重要的。
1
# Placeholder
2
X = tf.placeholder(dtype=tf.float32, shape=[None, n_stocks])
3
Y = tf.placeholder(dtype=tf.float32, shape=[None])
None表示,在这一点上我们还不知道在每个批处理中流过神经网络图的观测值的数量,使用它是为了保持灵活性。我们稍后将定义batch_size控制每次训练的批处理观察次数。
向量
除了占位符,向量是TensorFlow的另一个基础。占位符用于在图中存储输入数据和目标数据,而向量被用作图中的灵活容器在图形执行过程中允许更改。权重和偏置被表示为向量以便在训练中调整。向量需要在模型训练之前进行初始化。稍后我们会详细讨论。
该模型由四个隐藏层组成。第一层包含1024个神经元,略大于输入大小的两倍。随后的每个隐藏层是上一层的一半,也就是512、256和128个神经元。每个后续层的神经元数量的减少压缩了网络在先前层中识别的信息。当然,也有其他网络架构和神经元配置,但不在这篇文章的介绍范围之内。
01
# Model architecture parameters
02
n_stocks = 500
03
n_neurons_1 = 1024
04
n_neurons_2 = 512
05
n_neurons_3 = 256
06
n_neurons_4 = 128
07
n_target = 1
08
# Layer 1: Variables for hidden weights and biases
09
W_hidden_1 = tf.Variable(weight_initializer([n_stocks, n_neurons_1]))
10
bias_hidden_1 = tf.Variable(bias_initializer([n_neurons_1]))
11
# Layer 2: Variables for hidden weights and biases
12
W_hidden_2 = tf.Variable(weight_initializer([n_neurons_1, n_neurons_2]))
13
bias_hidden_2 = tf.Variable(bias_initializer([n_neurons_2]))
14
# Layer 3: Variables for hidden weights and biases
15
W_hidden_3 = tf.Variable(weight_initializer([n_neurons_2, n_neurons_3]))
16
bias_hidden_3 = tf.Variable(bias_initializer([n_neurons_3]))
17
# Layer 4: Variables for hidden weights and biases
18
W_hidden_4 = tf.Variable(weight_initializer([n_neurons_3, n_neurons_4]))
19
bias_hidden_4 = tf.Variable(bias_initializer([n_neurons_4]))
20
21
# Output layer: Variables for output weights and biases
22
W_out = tf.Variable(weight_initializer([n_neurons_4, n_target]))
23
bias_out = tf.Variable(bias_initializer([n_target]))
理解输入层,隐藏层和输出层之间所需的可变维度是很重要的。作为多层感知器(MLP)的一个经验法则,前一层的第二维是当前图层中权重矩阵的第一维。听起来很复杂,但其实只是每一层将其输出作为输入传递到下一层。偏置的维度等于当前层权重矩阵的第二维度,它对应于该层中的神经元的数量。
设计网络体系结构
在定义所需的权重和偏置向量之后,需要指定网络拓扑结构和网络结构。因此,占位符(数据)和向量(权重和偏置)需要被组合成一个连续的矩阵乘法系统。
此外,网络的隐藏层还要被激活函数转换。激活函数是网络体系结构的重要组成部分,因为它们将非线性引入系统。有几十个可能的激活函数,其中最常见的是整流线性单元(ReLU),它也将在这个模型中使用。
1
# Hidden layer
2
hidden_1 = tf.nn.relu(tf.add(tf.matmul(X, W_hidden_1), bias_hidden_1))
3
hidden_2 = tf.nn.relu(tf.add(tf.matmul(hidden_1, W_hidden_2), bias_hidden_2))
4
hidden_3 = tf.nn.relu(tf.add(tf.matmul(hidden_2, W_hidden_3), bias_hidden_3))
5
hidden_4 = tf.nn.relu(tf.add(tf.matmul(hidden_3, W_hidden_4), bias_hidden_4))
6
7
# Output layer (must be transposed)
8
out = tf.transpose(tf.add(tf.matmul(hidden_4, W_out), bias_out))
下图展示了网络架构。该模型由三个主要部分组成。输入层,隐藏层和输出层。这种架构被称为前馈网络。前馈表示该批数据仅从左向右流动。其他网络体系结构(如递归神经网络)也允许数据在网络中“反向”流动。
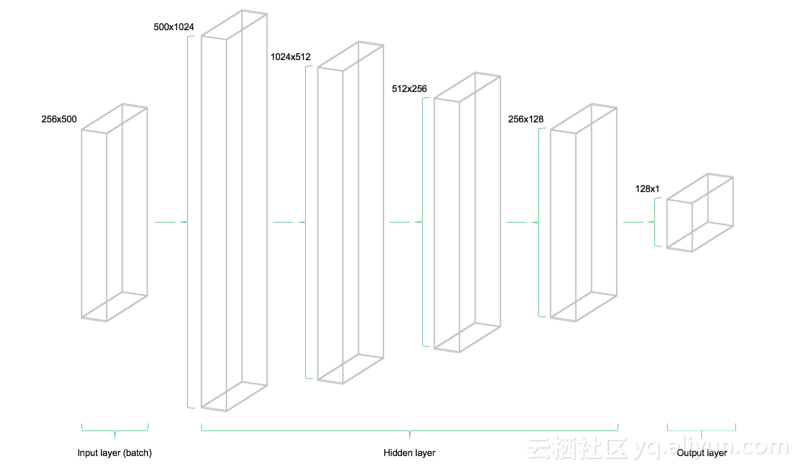
前馈网络架构
损失函数
网络的损失函数用于度量生成的网络预测与实际观察到的训练目标之间的偏差。回归问题,常用均方误差(MSE)函数。MSE计算预测和目标之间的平均方差。一般来说,任何可微函数都可以做预测和目标之间的偏差度量。
1
# Cost function
2
mse = tf.reduce_mean(tf.squared_difference(out, Y))
但是,MS有利于解决一些常见优化问题。
优化器
优化器是在训练期间调整网络的权重和偏置向量的必要计算。这些计算调用了梯度计算,它们指示训练期间权重和偏置需要改变的方向,以最小化网络的损失函数。稳定快速优化器的开发是神经网络深入学习研究的一个重要领域。
1
# Optimizer
2
opt = tf.train.AdamOptimizer().minimize(mse)
我们这里使用了Adam优化器r,这是当前深度学习开发的默认优化器之一。它的名称来源于适应性矩估计,可以看作另两个流行的优化器AdaGrad和RMSProp的组合。
初始化器
初始化器用于在训练之前初始化网络的向量。由于神经网络是使用数值优化技术进行训练的,所以优化问题的出发点是寻找解决底层问题的关键。在TensorFlow中有不同的初始化器,每个都有不同的初始化方法。在这里,我使用了tf.variance_scaling_initializer(),这是默认的初始化策略。
1
# Initializers
2
sigma = 1
3
weight_initializer = tf.variance_scaling_initializer(mode="fan_avg", distribution="uniform", scale=sigma)
4
bias_initializer = tf.zeros_initializer()
请注意,TensorFlow可以为图中的不同向量定义多个初始化函数。但大多数情况下,统一的初始化就足够了。
拟合神经网络
在定义了网络的占位符,向量,初始化器,损失函数和优化器之后,可以对模型进行训练了。通常通过小批量训练完成。在小批量训练期间,从训练数据中抽取n = batch_size随机数据样本并馈送到网络中。训练数据集被分成n / batch_size个批量按顺序馈入网络。此时的占位符,X和Y发挥作用。他们存储输入和目标数据,并将其作为输入和目标在网络中显示。
采样数据X批量流经网络,到达输出层。在那里,TensorFlow将模型预测与当前批量的实际观测目标Y进行比较。之后,TensorFlow进行优化步骤并更新与所选学习方案相对应的网络参数。在更新权重和偏置之后,下一个批量被采样,并重复此过程。直到所有的批量都被提交给网络。完成所有批量被称为完成一次epoch。
epoch达到最大或者用户定义的其他停止标准,网络的训练就会停止。
01
# Make Session
02
net = tf.Session()
03
# Run initializer
04
net.run(tf.global_variables_initializer())
05
06
# Setup interactive plot
07
plt.ion()
08
fig = plt.figure()
09
ax1 = fig.add_subplot(111)
10
line1, = ax1.plot(y_test)
11
line2, = ax1.plot(y_test*0.5)
12
plt.show()
13
14
# Number of epochs and batch size
15
epochs = 10
16
batch_size = 256
17
18
for e in range(epochs):
19
20
# Shuffle training data
21
shuffle_indices = np.random.permutation(np.arange(len(y_train)))
22
X_train = X_train[shuffle_indices]
23
y_train = y_train[shuffle_indices]
24
25
# Minibatch training
26
for i in range(0, len(y_train) // batch_size):
27
start = i * batch_size
28
batch_x = X_train[start:start + batch_size]
29
batch_y = y_train[start:start + batch_size]
30
# Run optimizer with batch
31
net.run(opt, feed_dict={X: batch_x, Y: batch_y})
32
33
# Show progress
34
if np.mod(i, 5) == 0:
35
# Prediction
36
pred = net.run(out, feed_dict={X: X_test})
37
line2.set_ydata(pred)
38
plt.title('Epoch ' + str(e) + ', Batch ' + str(i))
39
file_name = 'img/epoch_' + str(e) + '_batch_' + str(i) + '.jpg'
40
plt.savefig(file_name)
41
plt.pause(0.01)
在训练期间,我们评估测试集上的网络预测数据,测试集数据不被网络学习,每5批量就留下一个,并将其可视化。此外,这些图像被导出到磁盘,然后组合成训练过程的视频(如下)。该模型快速学习测试数据中的时间序列的形状和位置,并且能够在几个epoch之后产生准确的预测。
网络测试数据预测(橙色)的视频动画在训练期间。
我们可以看到网络很快适应时间序列的基本形状,并继续学习更精细的数据模式。这也对应于在模型训练期间降低学习速率的Adam学习方案,防止错过优化最小值。经过10个epoch之后,我们与测试数据非常接近了。最后的测试MSE等于0.00078(已经非常低了,目标曾缩放过)。测试集预测的平均绝对百分比误差等于5.31%,这是相当不错的。当然,这个结果只在测试数据中,在现实中没有实际的样本去度量。
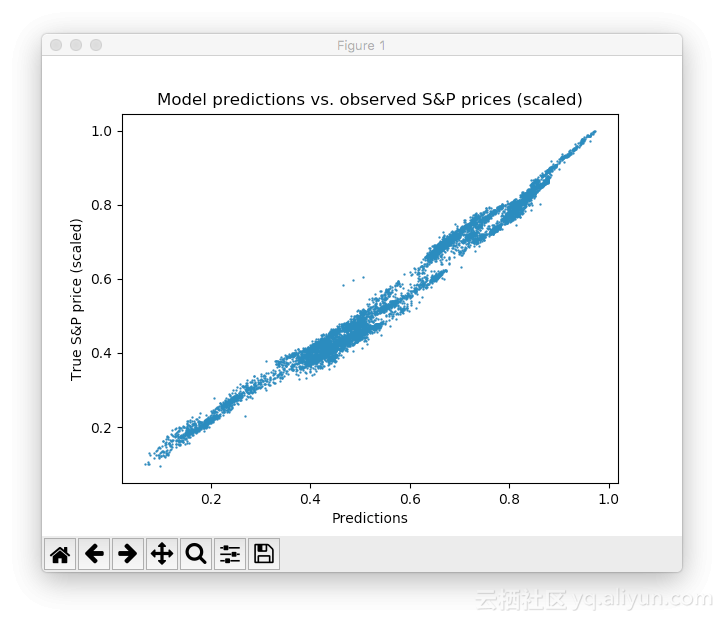
缩放后的预测与实际标准普尔散点图
请注意,有很多方法可以进一步改善这个结果:层和神经元的设计,选择不同的初始化和激活方案,引入神经元退出层等等。此外,不同类型的深度学习模型(如递归神经网络)可能在此任务上会有更好的性能。
本文由AiTechYun编译,转载请注明出处。更多内容关注微信公众号:atyun_com 或访问网站:http://www.atyun.com/