一、引言
最近由于业务需求,需要将公有云RDS(业务库)的大表数据归档至私有云MySQL(历史库),以缩减公有云RDS的体积和成本。
那么问题来了,数据归档的方式有n种,选择哪种呢?经过一番折腾,发现使用percona的pt-archiver就可以轻松并优雅地对MySQL进行数据归档。
待我娓娓道来~
1.1 pt-archive是啥
属于大名鼎鼎的percona工具集的一员,是归档MySQL大表数据的最佳轻量级工具之一。
注意,相当轻,相当方便简单。
1.2 pt-archive能干啥
- 清理线上过期数据;
- 导出线上数据,到线下数据作处理;
- 清理过期数据,并把数据归档到本地归档表中,或者远端归档服务器。
二、基本信息
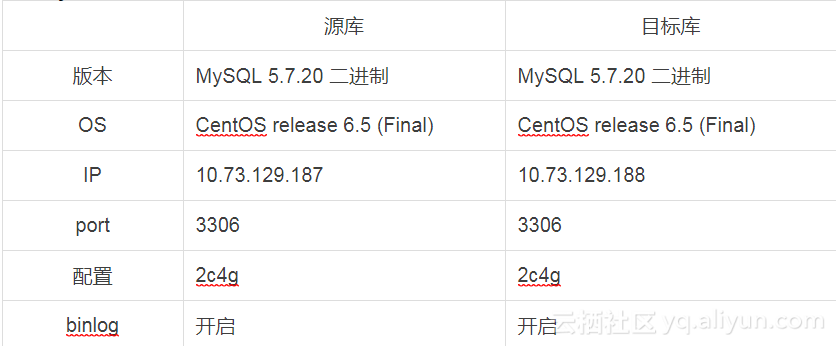
2.1 MySQL环境
2.2 pt-archiver信息

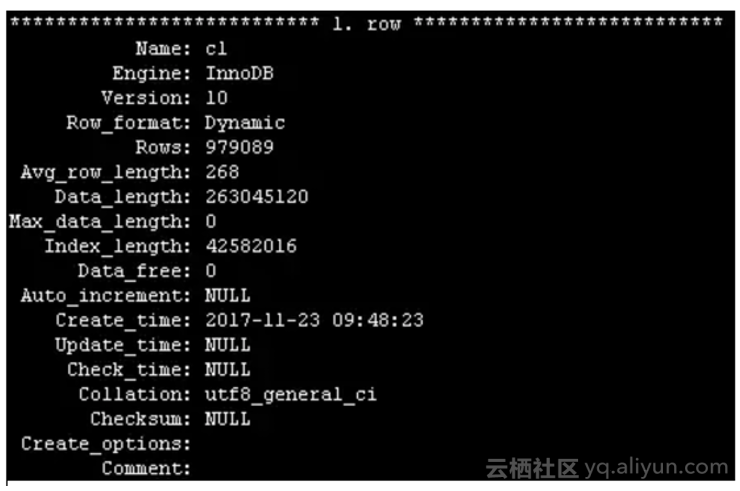
2.3 归档表信息

注意:pt-archiver操作的表必须有主键
三、模拟场景
3.1 场景1-1:全表归档,不删除原表数据,非批量插入
pt-archiver \
--source h=10.73.129.187,P=3306,u=backup_user,p='xxx',D=test123,t=c1 \
--dest h=10.73.129.188,P=3306,u=backup_user,p='xxx',D=test123,t=c1 \
--charset=UTF8 --where '1=1' --progress 10000 --limit=10000 --txn-size 10000 --statistics --no-delete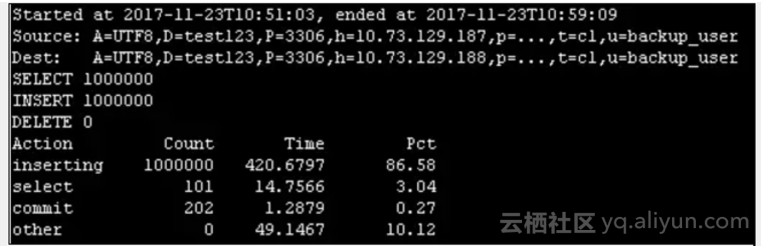
3.2 场景1-2:全表归档,不删除原表数据,批量插入
pt-archiver \
--source h=10.73.129.187,P=3306,u=backup_user,p='xxx',D=test123,t=c1 \
--dest h=10.73.129.188,P=3306,u=backup_user,p='xxx',D=test123,t=c1 \
--charset=UTF8 --where '1=1' --progress 10000 --limit=10000 --txn-size 10000 --bulk-insert --bulk-delete --statistics --no-delete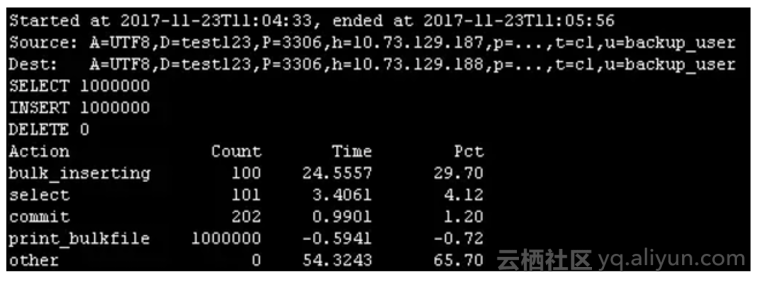
3.3 场景2-1:全表归档,删除原表数据,非批量插入,非批量删除
pt-archiver \
--source h=10.73.129.187,P=3306,u=backup_user,p='xxx',D=test123,t=c1 \
--dest h=10.73.129.188,P=3306,u=backup_user,p='xxx',D=test123,t=c1 \
--charset=UTF8 --where '1=1' --progress 10000 --limit=10000 --txn-size 10000 --statistics --purge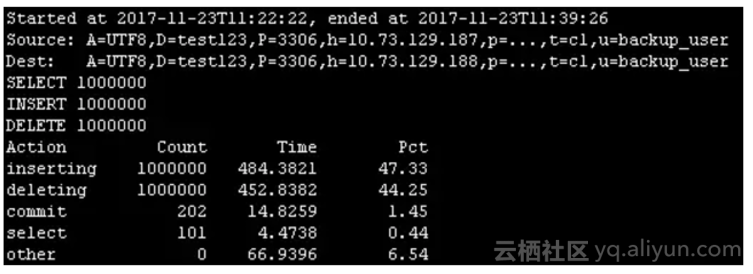
3.4 场景2-2:全表归档,删除原表数据,批量插入,批量删除
pt-archiver \
--source h=10.73.129.187,P=3306,u=backup_user,p='xxx',,D=test123,t=c1 \
--dest h=10.73.129.188,P=3306,u=backup_user,p='xxx',D=test123,t=c1 \
--charset=UTF8 --where '1=1' --progress 10000 --limit=10000 --txn-size 10000 --bulk-insert --bulk-delete --statistics --purge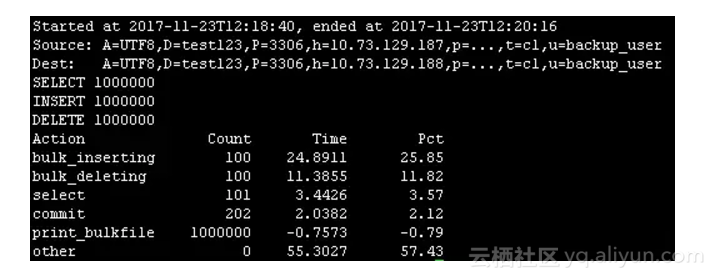
四、小结
4.1 性能对比
通过下表可以看出,批量操作和非批量操作的性能差距非常明显,批量操作花费时间为非批量操作的十分之一左右。
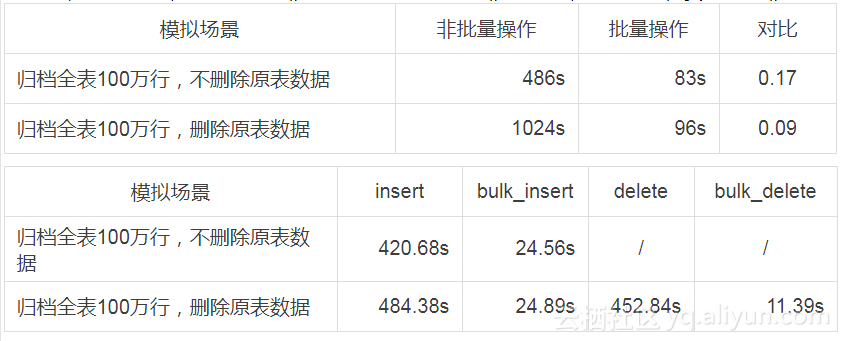
场景2-1:全表归档,删除原表数据,非批量插入,非批量删除4.2 general log分析
- 从日志看起来,源库的查询和目标库的插入有先后顺序
- 从日志看起来,目标库的插入和源库的删除,并无先后顺序。在特定条件下,万一目标库插入失败,源库删除成功,咋搞?感觉这里并不十分严谨
- 删除采用DELETE FROM TABLE WHERE ... ,每次删除一行数据
- 插入采用INSERT INTO TABLE VALUES('...'),每次插入一行数据
源库general log:
- set autocommit=0
- 批量查询(对应参数limit)
SELECT /*!40001 SQL_NO_CACHE */ `uuid` FORCE
INDEX(`PRIMARY`) WHERE (1=1) AND ((`uuid` >= '266431'))
ORDER BY `uuid` LIMIT 100003. 逐行删除
DELETE FROM `test123`.`c1` WHERE (`uuid` = '000002f0d9374c56ac456d76a68219b4')4. COMMIT(对应参数--txn-size,操作数量达到--txn-size,则commit)
目标库general log:
- set autocommit=0
- 逐行插入
INSERT INTO `test123`.`c1`(`uuid`) VALUES ('0436dcf30350428c88e3ae6045649659')3. COMMIT(对应参数--txn-size,操作数量达到--txn-size,则commit)
场景2-2:全表归档,删除原表数据,批量插入,批量删除
- 从日志看起来,源库的批量查询和目标库的批量插入有先后顺序
- 从日志看起来,目标库的批量插入和源库的批量删除,并无先后顺序。
- 批量删除采用DELETE FROM TABLE WHERE ... LIMIT 10000
- 批量插入采用LOAD DATA LOCAL INFILE 'file' INTO TABLE ...
源库:
- set autocommit=0
- 批量查询(对应limit参数)
SELECT /*!40001 SQL_NO_CACHE */ `uuid` FORCE
INDEX(`PRIMARY`) WHERE (1=1) AND ((`uuid` >= '266431'))
ORDER BY `uuid` LIMIT 100003. 批量删除
DELETE FROM `test123`.`c1` WHERE (((`uuid` >= '266432'))) AND (((`uuid` <= '273938'))) AND (1=1) LIMIT 100004. COMMIT(对应参数--txn-size,操作数量达到--txn-size,则commit)
目标库:
- set autocommit=0
- 批量插入
LOAD DATA LOCAL INFILE '/tmp/vkKXnc1VVApt-archiver' INTO TABLE `test123`.`c1`CHARACTER SET UTF8(`uuid`)3. COMMIT(对应参数--txn-size,操作数量达到--txn-size,则commit)
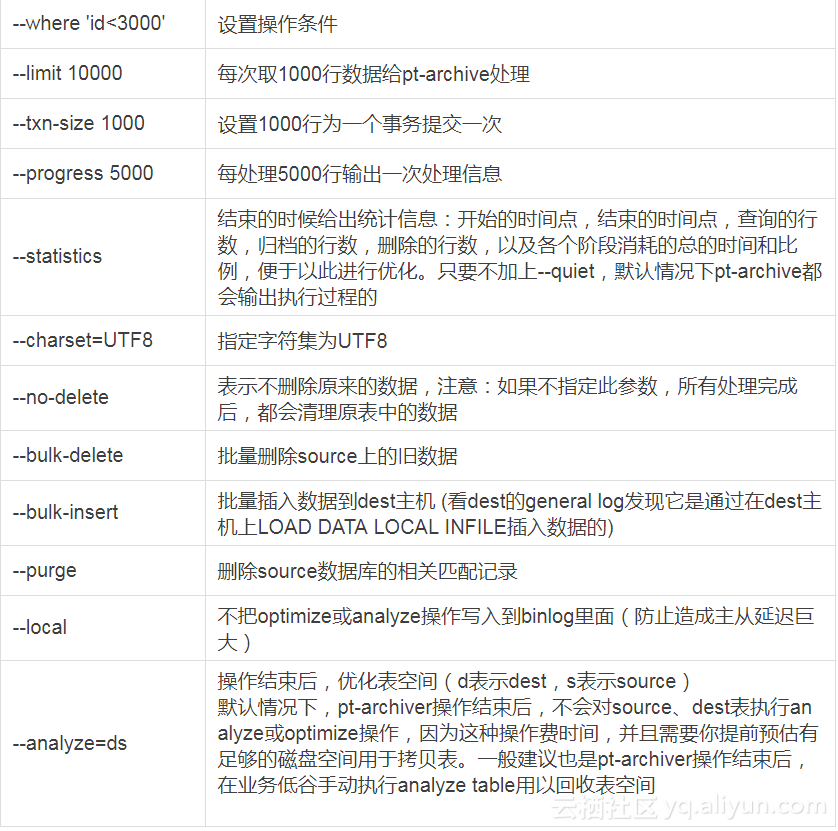
五、附录
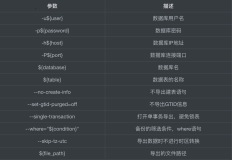
常用参数
原文发布时间为:2017-11-28
本文作者:蓝剑锋@知数堂