NVMe SSD具有高性能、低时延等优点,是目前存储行业的研究热点之一,但在光鲜的性能下也同样存在一些没有广为人知的问题,而这些问题其实对于一个生产系统而言至关重要,例如:
- QoS无法做到100%保证;
- 读写混合情况下,与单独读相比,性能下降严重,且读长尾延迟比较严重;
所以如何利用好NVMe盘的性能,并更好的为业务服务,我们需要从硬件,Linux内核等多个角度去剖析和解决。
从内核中NVMe IO框架来看其中存在的问题
当前Linux内核中对NVMe SSD的访问是通过MQ框架来实现的,接入NVMe驱动后直接略过IO调度器,具体实现上来说是从block layer中的通用块层回调make_request从而打通上下层IO通路。示意图如下,这里面有几个关键的点:

IO发送过程
MQ的框架提升性能最主要的将锁的粒度按照硬件队列进行拆分,并与底层SSD的队列进行绑定,理想的情况每一个CPU都有对应的硬件发送SQ与响应CQ,这样可以并发同时彼此之前无影响。按照NVMe SPEC协议中的标准,硬件最多支持64K个队列,所以理想情况下硬件队列个数将不会是我们需要担心的地方。但是实际情况又如何呢?由于硬件队列的增加会给NVMe SSD带来功耗的增加,所以不同的厂商在设计硬件队列个数时的考量是不同的,比如intel P3600支持32个队列,intel最新的P4500支持128个,但是SUMSUNG PM963却只支持到8个。那么当CPU的个数超过硬件的队列个数,就会出现多个CPU共用一个硬件队列的情况,对性能就会产生影响。
下面使用SUMSUNG PM963做一个简单的测试:
#!/bin/bash
fio -name=test1 -filename=/dev/nvme11n1 -thread=1 -bs=4k -rw=randread -iodepth=256 -direct=1 -numjobs=1 -ioengine=libaio -group_reporting -runtime=60 -cpus_allowed=1 --output=urgent.txt &
fio -name=test2 -filename=/dev/nvme11n1 -thread=1 -bs=4k -rw=randread -iodepth=256 -direct=1 -numjobs=1 -ioengine=libaio -group_reporting -runtime=60 -cpus_allowed=10 --output=high.txt &
测试结果为
read : io=59198MB, bw=986.61MB/s, iops=252567, runt= 60002msec
read : io=59197MB, bw=986.62MB/s, iops=252571, runt= 60001msec
也就是整个IOPS可以达到50w
如果使用同一个硬件队列
#!/bin/bash
fio -name=test1 -filename=/dev/nvme11n1 -thread=1 -bs=4k -rw=randread -iodepth=256 -direct=1 -numjobs=1 -ioengine=libaio -group_reporting -runtime=60 -cpus_allowed=1 --output=urgent.txt &
fio -name=test2 -filename=/dev/nvme11n1 -thread=1 -bs=4k -rw=randread -iodepth=256 -direct=1 -numjobs=1 -ioengine=libaio -group_reporting -runtime=60 -cpus_allowed=2 --output=high.txt &
结果为:
read : io=51735MB, bw=882937KB/s, iops=220734, runt= 60001msec
read : io=52411MB, bw=894461KB/s, iops=223615, runt= 60001msec
整个IOPS只有44w,性能下降12%,主要原因是多个CPU共用硬件队列进行发送的时候会有自旋锁争抢的影响。所以对于共用硬件队列的情况下,如何绑定CPU是需要根据业务的特点来确定的。
IO响应过程
IO响应过程中最主要问题是中断的balance,由于默认linux中并没有对NVMe的中断进行有效的绑定,所以不同的绑定策略会带来截然不同的性能数据。不过在我们的实际测试中,虽然我们没有做中断的绑定,但是貌似不管是性能还是稳定性的下降并没有那么严重,什么原因呢?根据我们的分析,这里面最主要的原因是(后面也会提到),我们并没有大压力的使用NVMe盘,所以实际的应用场景压力以及队列深度并不大。
从应用本身的IO Pattern来看使用NVMe问题
我们在评测一个NVMe SSD的性能的时候,往往都是通过benchmark工具,例如见1, 见2。
然而这些测试的结果与业务实际使用NVMe SSD看到的性能相比差距很大, 原因是因为这些性能测试存在两个比较大的误区,因而并不能反映生产系统的真实情况。
1. 片面夸大了NVMe盘的性能
从上面两篇文章中的测试中我们可以看到,大多数压测中使用的队列深度为128,并且是用libaio这样的异步IO模式来下发IO。但是在实际应用场景中很少有这么大的队列深度。在这种场景下,根据“色子效应”,并不会将NVMe盘的并发性能充分发挥出来。


2. 低估了NVMe的长尾延迟
然而在另外一些场景下,队列深度又会非常高(比如到1024甚至更高),在这种情况下NVMe SSD带来的QoS长尾延迟影响比上面的benchmark的测试又严重得多。
所以综合起来看,这种评测选择了一个看上去没啥大用的场景做了测试,所以得出的结果也对我们实际的应用基本没有参考价值。那么问题出在什么地方么?
问题分析
首先让我们再次强调一下一般评测文章中benchmark进行的测试场景的特点:
- 大多是
fio工具,开启libaio引擎增加IO压力 队列深度到128或者256
在这种场景下确实基本都可以将NVMe盘的压力打满。
在展开分析问题的原因之前,我们先看看Linux内核的IO栈。

在实际应用中,VFS提供给应用的接口,从IO的特点来分类,大致上可以分为两类:direct IO与buffer IO。使用direct IO的业务大多在应用本身就已经做了一层cache,不依赖OS提供的page cache。其他的情况大多使用的都是buffer IO。linux kernel中的block layer通过REQ_SYNC与~REQ_SYNC这两种不同的标志来区分这两类IO。大家常用的direct IO这个类型,内核要保证这次IO操作的数据落盘,并且当响应返回以后,应用程序才能够认为这次IO操作是完成的。所以是使用了这里的REQ_SYNC标志,而对应的buffer IO,则大量使用了~REQ_SYNC的标志。让我们一个一个看过去。
direct IO
由于在实际使用方式中AIO还不够成熟,所以大多使用direct IO。但是direct IO是一种SYNC模式,并且完全达不到测试用例中128路并发AIO的效果。
这主要两个方面原因:
direct io在下发过程中可能会使用文件粒度的锁inode->i_mutex进行互斥。
101 static ssize_t
102 ext4_file_dio_write(struct kiocb *iocb, const struct iovec *iov,
103 unsigned long nr_segs, loff_t pos)
104 {
105 struct file *file = iocb->ki_filp;
106 struct inode *inode = file->f_mapping->host;
107 struct blk_plug plug;
108 int unaligned_aio = 0;
109 ssize_t ret;
110 int overwrite = 0;
111 size_t length = iov_length(iov, nr_segs);
112
..........
122
123 BUG_ON(iocb->ki_pos != pos);
124
125 mutex_lock(&inode->i_mutex);
127前面说的IO SYNC模式
1052 static inline ssize_t
1053 do_blockdev_direct_IO(int rw, struct kiocb *iocb, struct inode *inode,
1054 struct block_device *bdev, const struct iovec *iov, loff_t offset,
1055 unsigned long nr_segs, get_block_t get_block, dio_iodone_t end_io,
1056 dio_submit_t submit_io, int flags)
...........
1283 if (retval != -EIOCBQUEUED)
1284 dio_await_completion(dio);也就是说,我们很难通过direct IO来达到压满NVMe盘的目的。如果一定要打满NVMe盘,那么一方面要提高进程并发,另外一方面还要提高多进程多文件的并发。而这是生产系统中很难满足的。
buffer IO
我们再来看看buffer IO的特点。下面我使用了比较简单的fio通过buffer IO的模式下发,而且通过rate限速,我们发现平均下来每秒的数据量不到100MB,整个IO的特点如下:
fio -name=test1 -filename=/home/nvme/test1.txt -thread=1 -bs=4k -rw=randwrite -iodepth=32 -numjobs=32 -ioengine=sync -size=10G -group_reporting -runtime=600 -rate=200m -thinktime=1000
06/11/17-14:06:02 0.00 0.00 0.00 78.2K 0.00 354.3K 4.53 313.00 3.84 0.00 30.90
06/11/17-14:06:03 0.00 0.00 0.00 193.0K 0.00 866.5K 4.49 781.00 3.91 0.00 76.40
06/11/17-14:06:04 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
06/11/17-14:06:05 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
06/11/17-14:06:06 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
06/11/17-14:06:07 0.00 0.00 0.00 3.00 0.00 12.00 4.00 0.00 0.00 0.00 0.00
06/11/17-14:06:08 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
06/11/17-14:06:09 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Time ----------------------------------------nvme11n1----------------------------------------
Time rrqms wrqms rs ws rsecs wsecs rqsize qusize await svctm util
06/11/17-14:06:10 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
06/11/17-14:06:11 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
06/11/17-14:06:12 0.00 0.00 0.00 3.00 0.00 12.00 4.00 0.00 0.00 0.00 0.00
06/11/17-14:06:13 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
06/11/17-14:06:14 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
06/11/17-14:06:15 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
06/11/17-14:06:16 0.00 0.00 0.00 32.5K 0.00 152.0K 4.68 128.00 3.83 0.00 13.00
06/11/17-14:06:17 0.00 0.00 0.00 31.8K 0.00 152.0K 4.78 128.00 3.95 0.00 13.10
06/11/17-14:06:18 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
06/11/17-14:06:19 0.00 0.00 0.00 229.2K 0.00 1.1M 4.85 986.00 4.19 0.00 97.00
06/11/17-14:06:20 0.00 0.00 0.00 100.7K 0.00 467.8K 4.64 419.00 4.07 0.00 41.40
06/11/17-14:06:21 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
06/11/17-14:06:22 0.00 0.00 0.00 3.00 0.00 12.00 4.00 0.00 0.00 0.00 0.00
FUNC COUNT
submit_bio 113805
FUNC COUNT
submit_bio 143703
FUNC COUNT
submit_bio 154
FUNC COUNT
submit_bio 86
FUNC COUNT
submit_bio 78
FUNC COUNT
submit_bio 96
FUNC COUNT
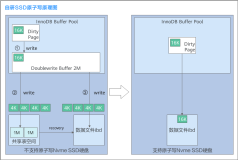
submit_bio 124抓取了下submit_bio在每秒的调用次数并分析可以得出,buffer IO在下刷的时候并不会考虑QD的多少,而是类似aio那样,kworker将需要下发的脏页都会bio形式下发,而且不需要等待某些bio返回。注意这里面有一个细节从qusize观察到IO最大值986,并没有达到百K,或者几十K,这个原因是由本身MQ的框架中tag机制nr_request决定,目前单Q设置默认值一般为1024。总之buffer IO这样特点的结果就是突发量的高iops的写入,buffer IO对于应用程序来说是不可见的,因为这是linux kernel的本身的刷脏页行为。但是它带给应用的影响确实可见的,笔者曾经总结过异步IO的延时对长尾的影响,如下图所示,分别是buffer IO与direct IO在相同带宽下延时表现,可以看出这延迟长尾比我们简单的通过fio benchmark测试严重的多,特别是盘开始做GC的时候,抖动更加严重;而且随着盘的容量用着越来越多,GC的影响越来越大,长尾的影响也是越来越严重。

在HDD的时代上面的问题同样会存在,但是为什么没有那么严重,原因主要是HDD大多使用CFQ调度器,其中一个特性是同步、异步IO队列分离。并且在调度过程中同步优先级比较高,在调度抢占、时间片等都是同步优先。
解决问题
前面描述了使用NVMe硬盘的严重性,下面介绍一下如何解决这些问题。
(1)MQ绑定的问题,需要根据当前业务的特点,如果硬件的队列小于当前CPU的个数,尽量让核心业务上跑的进程分散在绑定不同硬件队列的CPU上,防止IO压力大的时候锁资源的竞争。
(2)中断绑定CPU,建议下发的SQ的CPU与响应的CQ的CPU保持一致,这样各自CPU来处理自己的事情,互相业务与中断不干扰。
(3)解决direct IO状态下长尾延迟,因为长尾延迟是本身NVMe SSD Controller带来,所以解决这个问题还是要从控制器入手,使用的方法有WRR(Weight Round Robin),这个功能在当前主流厂商的最新的NVMe SSD中已经支持。

(4)解决buffer IO状态下长尾延迟,可以通过控制NVME SSD处理的QD来解决,使用的NVME多队列IO调度器,充分利用了MQ框架,根据同步写、读延迟动态调整异步IO的队列,很好的解决buffer io带来的长尾延迟。