在《代码重构(一):函数重构规则(Swift版)》和《代码重构(二):类重构规则(Swift版)》中详细的介绍了函数与类的重构规则。本篇博客延续之前博客的风格,分享一下在Swift语言中是如何对数据进行重构的。对数据重构是很有必要的,因为我们的程序主要是对数据进行处理。如果你的业务逻辑非常复杂,那么对数据进行合理的处理是很有必要的。对数据的组织形式以及操作进行重构,提高了代码的可维护性以及可扩展性。
与函数重构与类重构类似,对数据结构的重构也是有一定的规则的。通过这些规则可以使你更好的组织数据,让你的应用程序更为健壮。在本篇博客中将会结合着Swift代码实现的小实例来分析一下数据重构的规则,并讨论一下何时使用那些重构规则进行数据重构。还是那句话“物极必反”呢,如果不恰当的使用重构规则,或者过度的使用重构规则不但起不到重构的作用,有时还会起到反作用。废话少说,进入今天数据重构的主题。
一. Self Encapsulate Field (自封装字段)
"自封装字段"理解起来比较简单,一句话概括:虽然字段对外是也隐藏的,但是还是有必要为其添加getter方法,在类的内部使用getter方法来代替self.field,该方式称为自封装字段,自己封装的字段,自己使用。当然该重构规则不是必须执行的,因为如果你直接使用self来访问类的属性如果不妨碍你做扩展或者维护,那么也是可以的,毕竟直接访问变量更为容易阅读。各有各的好处,间接访问字段的好处是使你的程序更为模块化,可以更为灵活的管理数据。比如在获取值时,因为后期需求的变化,该获取的字段需要做一些计算,那么间接访问字段的方式就很容易解决这个问题,而直接访问字段的方式就不是很好解决了。所以间接一下还是好处多多的,不过直接访问不影响你的应用程序的话,也是无伤大雅的。
下方会通过一个实例来看一下间接访问字段的好处。下方的IntRange类中的字段就没有提供间接访问的方法,在代码中通过直接访问的形式来使用的字段。这种做法对当前的程序影响不大,但是如果提出需求了。要在high赋值后,在IntRange对类进行一个较为复杂的修改。那么对于下方代码而言,有两种解决方案,就是在构函数中进行修改,在一个就是在使用self.high的地方进行修正,当然这两种方法都不理想。最理性的方案是在相应字段的getter方法修改。
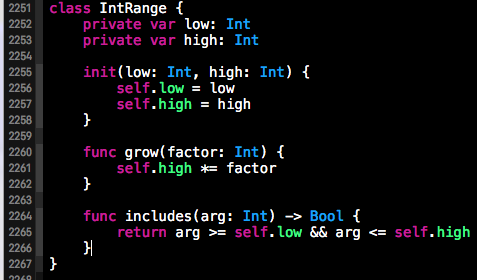
下方截图就是为InRange类中相应的字段自封装了getter和setter方法,并在使用self.字段的地方使用该自封装的方法代替(构造函数中对字段的初始化除外,因为设置方法一般在对象创建完毕以后在调用,所以不能在创建对象时调用,当然Swift语言也不允许你在构造函数函数中调用设置方法)。下方红框中的是我们添加的自封装方法,绿框中是对自封装方法的使用,白框中是需要注意的一点,构造函数中不能使用该设置函数。
当然,只添加上上述自封装字段后,优点不明显。当然子类CappedRange继承了IntRange函数后,这种优点就被显示了出来。在子类中CappedRange的high需要与新添加的字段cap进行比较,取较大的值作为区间的上限。在这种情况下自封装字段的优点就被凸显了出来。在子类中只需要对getHigh()函数进行重新,在重写的方法中进行相应的计算即可。因为当在子类中调用inclued()方法时,在include()方法中调用的是子类的getHigh()方法。具体请看下方子类截图:

二. Replace data Value with Object(以对象取代数据值)
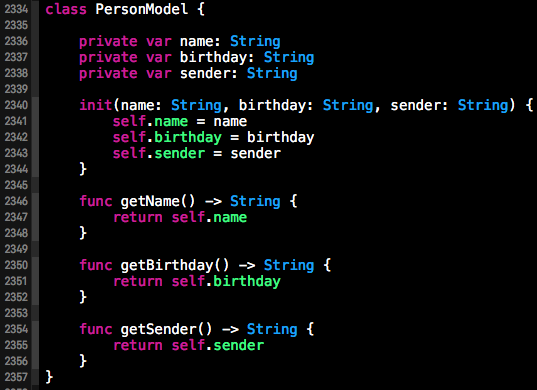
“以对象取代数据值”说白了就是我们常说的实体类,也就是Model类。Model的职责就将一些相关联的数据组织在一起来表示一个实体。Model类比较简单,一般只用于数据的存储,其中有一些相关联的字段,并为这些相关联的字段添加getter/和setter方法。下方是一个Person的数据模型,我们命名为PersonModel,其中有三个表示Person属性的字段name、birthday、sender。然后提供了一个构造器以及各个属性对应的getter和setter方法。具体请看下方代码所示:
三、Change Value to Reference (将值对象改变成引用对象)
在介绍“将值对象改变成引用对象”之前,我们先去了解一下值对象和引用对象的区别。先说一下值对象,比如两个相等的数值,存入了两个值对象中,这两个值对象在内存中分别占有两块不同的区域,所以改变其中一个值不会引起另一个值得变化。而引用对象正好相反,一个内存区域被多个引用指针所引用,这些引用指针即为引用对象,因为多个指针指向同一块内存地址,所以无论你改变哪一个指针中的值,其他引用对象的值也会跟着变化。
基于值对象和引用对象的特点,我们有时候根据程序的上下文和需求需要将一些值类型改变成引用类型。因为有时候需要一些类的一些对象在应用程序中唯一。这和单例模式又有一些区别,单例就是一个类只能生成一个对象,而“将值对象改变成引用对象”面临的就是类可以创建多个对象,但是这多个对象在程序中是唯一的,并且在某一个引用点修改对象中的属性时,其他引用点的对象值也会随之改变。下方就通过一个订单和用户的关系来观察一下这个规则。
1. 值引用的实例
(1) 首先我们需要创建一个消费者也就是Customer类。Customer类比较简单,其实就是一个数据实体类。其中有name和idCard属性并对应着getter/setter方法,具体代码如下所示:

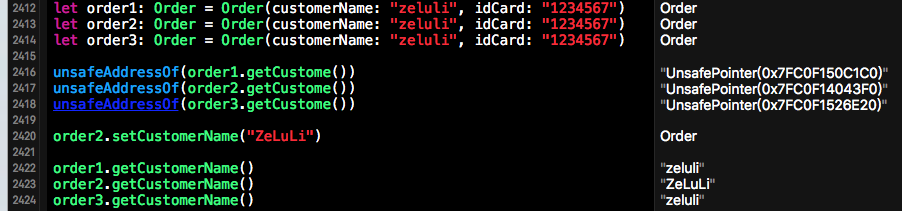
(2)、紧接着我们需要创建一个订单类,在订单创建时我们需要为该订单关联一个Customer(当然这为了简化实例,我们省略了Order中的其他字段)。该Order类的代码也是比较简单的在此就不做过的的赘述了。不过有一点需要注意的是为了测试,我们将customer设计成值类型,也就是每个Order中的customer都会占用不同的内存空间,这也就是值类型的特点之一。

(3).创建完Order与Customer类后,紧接着我们要创建测试用例了。并通过测试用例来发现问题,并在重构时对该问题进行解决。在测试用例中我们创建了三个订单,为每个订单关联一个Customer。从测试用例中可以看出,关联的消费者数据为同一个人,但是这一个人在内存中占用了不同的存储空间,如果一个订单中的用户信息进行了更改,那么其他订单中的用户信息是不会更新的。如果创建完用户后,信息不可更改,虽然浪费点存储空间,但是使用值类型是没用问题的。一旦某个订单修改了用户名称,那么就会出现数据不同步的问题。
2.将Order中Customer改为引用类型(重新设计Order类)
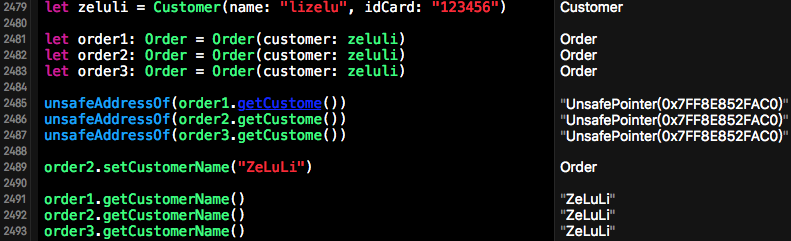
因为在Swift语言中类本身就是引用类型,所以在设计Order时,我们值需要将其中的customer字段改成引用外部的Customer类的对象即可。这样一来多个订单可以引用同一个用户了,而且一个订单对用户信息修改后,其他订单的用户信息也会随之改变。要实现这一点需要对Order的构造函数和customer的设置函数进行修改,将在Order内部创建Customer对象的方式改变成将外部Customer对象的引用赋值给Order中的custom对象。说白了,修改后的Order中的customer对象就是外部对象的一个引用。这种方法可以将值对象改变成引用对象

上面这种做法可以将值对象改变成引用对象,但是代价就是改变Order创建的方式。上面代码修改完了,那么我们的测试用例也就作废了,因为Order的创建方式进行了修改,需要外部传入一个Customer对象,下方截图就是我们修改后的测试用例。(如果你是在你的工程中这么去将值对象修改引用对象的,不建议这么做,下面会给出比较好的解决方案)。
3.从根本上进行重构
上面代码的修改不能称为代码的重构,因为其改变的是不仅仅是模块内部的结构,而且修改了模块的调用方式。也就是说里外都被修改了,这与我们重构所提倡的“改变模块内部结构,而不改变对外调用方式”所相悖。所以在代码重构时不要这么做了,因为上面的这种做法的成本会很高,并且出现BUG的几率也会提高。因为每个使用订单的地方都会创建一个Customer的类来支持订单的创建,那么问题来了,如果同一用户在不同地方创建订单怎么办?所以上面的做法还是有问题的,终归是治标不治本。所以我们要从根本上来解决这个问题。因为该问题是因为Customer数据不同步引起的,所以我们还得从Customer来下手。
该部分的重构,在第一部分的基础上做起。我们本次重构的目标就是“不改变对外调用方式,但能保持每个用户是唯一的”。好接下来就开始我们真正的重构工作。在本次重构中,依照重构的规则,我们不会去修改我们的测试用例,这一点很重要。
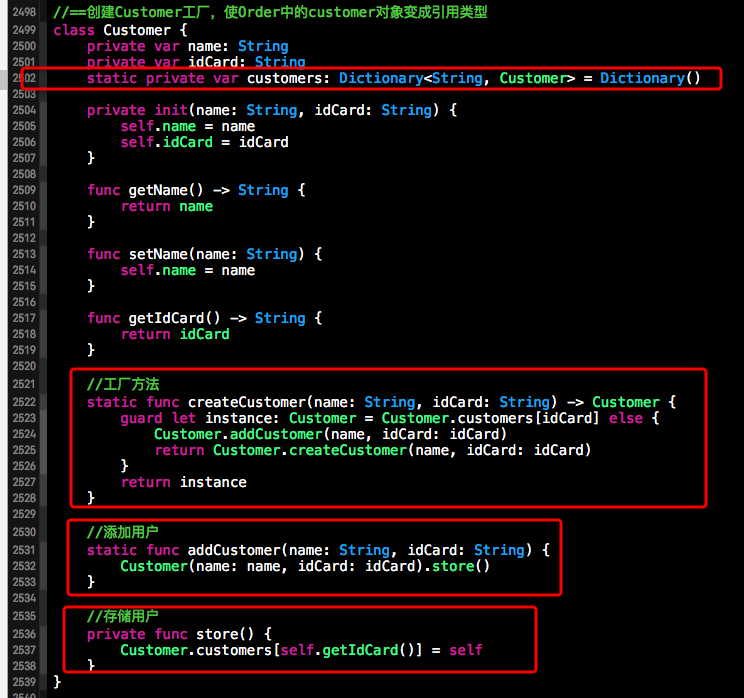
(1)从根本解决问题,首先我们对Customer进行重构。在Customer中添加了一个静态的私有变量customers, 该静态私有变量是字典类型。其中存储的就是每次创建的消费者信息。在字典中每个消费者的key为消费者独一无二的身份证信息(idCard)。在添加完上述变量后,我们需要为创建一个工厂方法createCustomer() 在工厂方法中,如果当前传入的用户信息未被存入到字典中,我们就对其进行创建存入字典,并返回该用户信息。如果传入的用户已经被创建过,那么就从字典中直接取出用户对象并返回。具体做法如下所示。
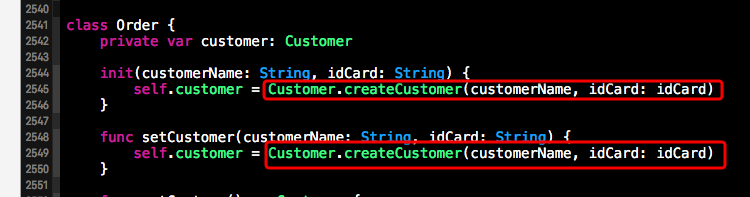
(2)、对Customer类修改完毕后,我们需要在Order中通过Customer的工厂方法来获取Customer类的实例,这样就能保证Order中的customer对象也是引用对象了。不过此时的引用对象是从Customer中获取的,而不是外部传过来的。下方是Order类中对工厂方法的调用,这样做的好处就是,我们只对模块的内部进行了修改,而测试用例无需修改。
(3)、对此次重进行测试,我们任然使用第一部分使用的测试用例。也就是说该模块对外的接口是没有变化的,下方就是对重构后的代码的测试结果。由结果可以看出,在不同订单中的用户,只要是信息一致,那么其内存地址是一致的。也就是经过重构,我们将原来的值对象改成了引用对象。

四、Change Reference to Value(将引用对象改为值对象)
将引用对象改为值对象,该重构规则正好与上面相反。在一些情况下使用值对象更为简单,更易管理,但前提是该值对象很小并且不会被改变。在这种情况下你就没有必要使用引用对象了。从上面的示例来看,使用引用对象实现起来还是较为复杂的。还是那句话,如果你的对象非常小,而且在创建后其中的数据不会被改变,如果需要改变就必须在创建一个新的对象来替换原来的对象。在这种情况下使用值对象是完全可以的。在此就不做过多的赘述了。
不过在使用值对象时,你最好为值对象提供一个重载的相等运算符用来比较值对象中的值。也就是说只要是值对象中的每个属性的值都相同,那么这两个值对象就相等。至于如何对“==” 运算符进行重载就不做过多的赘述了,因为该知识点不是本篇博客的重点。
五、Replace Array or Dictionary with Object(以对象取代数组或字典)
这一点呢和本篇博客的第二部分其实是一个。就是当你使用数组或者字典来组织数据,这些数据组合起来代表一定的意义,这是最好将其定义成一个实体类。还是那句话,定义成实体类后,数据更易管理, 便于后期需求的迭代。下方代码段就是讲相应的字典和数组封装成一个实体类,因为确实比较简单,在此就不做过多的赘述了。具体请参加下方代码段。

六、Duplicate Observed Data(复制“被监测数据”)
这一部分是比较重要的部分,也是在做UI开发时经常遇到的部分。用大白话将就是你的业务逻辑与GUI柔和在了一起,因为UI作为数据的入口,所以在写程序时,我们就很容易将数据处理的方式与UI写在一起。这样做是非常不好的,不利于代码的维护,也不利于代码的可读性。随着需求不断的迭代,版本不断的更新,UI与业务逻辑融合的代码会变得非常难于维护。所以我们还是有必要将于UI无关的代码从UI中进行分离,关于如何进行分层宏观的做法请参加之前发布的博客《iOS开发之浅谈MVVM的架构设计与团队协作》。
今天博客中的该部分是分层的微观的东西,也就是具体如何将业务逻辑从GUI中进行剥离。所以在接下来的实例中是和UI实现有关的,会根据一个比较简单的Demo来一步步的将UI中的业务逻辑进行分离。进入该部分的主题。复制“被监测数据”简单的说,就是将UI提供的数据复制一份到我们的业务逻辑层,然后与UI相应的数据进行关联,UI数据变化,被复制的业务逻辑中的数据也会随之变化。这一点也就是所谓的"响应式编程"吧,关于响应式编程,iOS开发中会经常用到ReactiveCocoa这个框架,关于ReactiveCocoa的内容,请参见之前的博客《iOS开发之ReactiveCocoa下的MVVM》。今天的示例中,使用了一个比较简单的方式来同步这些数据,使用了"事件监听机制"。下方就创建一个比较简单的Demo。
1.创建示例
要创建的示例比较简单,在UI方面,只有三个输入框用来接收加数与被加数,以及用来显示两数之和。然后使用两个UILabel来显示+号与=号。我们要实现的功能就是改变其中一个加数与被加数时,自动计算两个数的和并显示。

要实现上述功能的代码也是比较简单的,总共没有几行,下方这个类就是实现该功能的全部代码。代码的核心功能就是“获取加数与被加数的和,然后在加数与被加数的值有一个改变时,就会计算两者之和,并将和赋值给最后一个输入框进行显示”。具体代码如下所示。
class AddViewControllerBack: UIViewController {
//三个输入框对应的字段
@IBOutlet var firstNumberTextField: UITextField!
@IBOutlet var secondNumberTextField: UITextField!
@IBOutlet var resultTextField: UITextField!
override func viewDidLoad() {
super.viewDidLoad()
}
//获取第一个输入框的值
func getFirstNumber() -> String {
return firstNumberTextField.text!
}
//获取第二个输入框的值
func getSecondNumber() -> String {
return secondNumberTextField.text!
}
//加数与被加数中的值改变时会调用的方法
@IBAction func textFieldChange(sender: AnyObject) {
self.resultTextField.text = calculate(getFirstNumber(), second: getSecondNumber())
}
//计算两个数的值
func calculate(first: String, second: String) -> String {
return String(stringToInt(first) + stringToInt(second))
}
//将字符串安全的转变成整数的函数
func stringToInt(str: String) -> Int {
guard let result = Int(str) else {
return 0
}
return result
}
}2.对上述代码进行分析并重构
因为代码比较简单,所以很容易进行分析。在上述UI代码中,我们很清楚的看到后两个函数,也就是calculate()与stringToInt()函数是数据处理的部分,只依赖于数据,与UI关系不是很大,所以我们可以使用复制“被监测数据”规则将该段业务逻辑代码进行提取重构。重构后UI以及UI对外的工作方式不变。
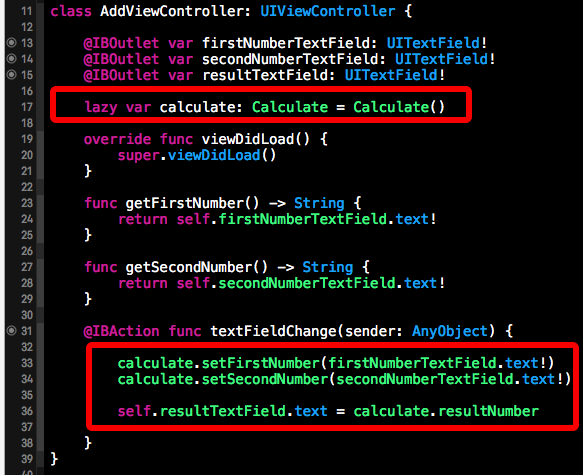
下方的Calculate类就是我们提取的数据业务类,负责处理数据。在该类中我们创建了三个属性来与UI中的输入框进行对应,这也就是所说的复制“被监测的数据”。因为和也就是resultNumber是由firstNumber和SecondNumber计算而来的,所以我们就把resultNumber定义成了计算属性,而firstNumber和secondNumber为存储属性。并为存储属性提供setter方法。在Calculate类的构造函数中,我们为两个值指定了初始化数据也就是“0”。最下方的那两个函数就是我们从UI中直接拷贝过来的数据,一点没有修改,也是可以工作的,因为这部分代码只依赖于数据,而不依赖于UI。

创建为相应的业务逻辑处理类并提取完业务逻辑后,我们需要将业务逻辑中的数据,也就是复制过来的数据与UI中的数据提供者进行绑定,并返回计算结果。下方红框中就是我们要修改的部分,在UI中我们删除掉处理业务数据的代码,然后创建也给Calculate对象,并在相应的事件监听的方法中更新Calculate对象中的数据。如下所示
七、Change Unidirectional Association to Bidirectional(将单向关联改为双向关联)
要介绍本部分呢,我想引用本篇博文中第(三)部分是实例。因为在第三部分的实例中Customer与Order的关系是单向关联的,也就是说Order引用了Customer, 而Customer没有引用Order。换句话说,我们知道这个订单是谁的,但你不知道只通过用户你是无法知道他有多少订单的。为了只通过用户我们就能知道该用户有多少订单,那么我们需要使用到“将单向关联改为双向关联”这条规则。
1. 在Customer类中添加上指向Order类的链
因为Customer没有指向Order类的链,所以我们不能获取到该用户有多少订单,现在我们就要添加上这条链。将单向关联改为双向关联,具体做法是在Customer中添加一个数组,该数组中存储的就是该用户所拥有的订单。这个数组就是我们添加的链。数组如下:
1 //添加与Order关联的链,一个用户有多个订单
2 private var orders:Array<Order> = []在Customer中值只添加数组也是不行的呢,根据之前提到的重构规则,我们要为数组封装相应的操作方法的,下方就是我们要在Customer中添加的操作数组的方法。具体代码如下所示:
//====================添加==================
func addOrder(order: Order) {
self.orders.append(order)
}
func getOrders() -> Array<Order> {
return self.orders
}在Order类关联Customer时,建立Customer到Order的关联。也就是将当前订单添加进该用户对应的订单数组中,具体做法如下:

与之对应的规则是Change Bidirectional Association to Unidirectional(将双向关联改为单向关联),就是根据特定需求删去一个链。就是说,原来需要双向链,可如今由于需求变更单向关联即可,那么你就应该将双向关联改为单向关联。
八、Replace Magic Number with Synbolic Constant(以字面常量取代魔法数)
这一点说白了就是不要在你的应用程序中直接出现字数值。这一点很好理解,在使用字面数值时,我们要使用定义好的常量来定义。因为这样更易于维护,如果同一个字面数值写的到处都是,维护起来及其困难。当使用字面常量时维护起来就容易许多。该规则比较容易理解,在此不做过多的赘述。看下方实例即可。对于下方的实例而言,如果在版本迭代中所需的PI的精度有所改变,那么对于替换后的程序而言,我们只需修改这个常量的值即可。
func test(height: Double) -> Double {
return 3.141592654 * height
}
//替换
let PI = 3.141592654
func test1(height: Double) -> Double {
return PI * height
}
九、Encapsulate Field(封装字段)
当你的类中有对外开放字段时,最好将其进行封装,不要直接使用对象来访问该字段,该优缺点与上述的“自封装字段”的优缺点类似。因为直接访问类的字段,会降低程序的模块化,不利于程序的扩充和功能的添加。再者封装是面向对象的特征之一,所以我们需要将字段变成私有的,然后对外提供相应的setter和getter方法。具体做法如下所示。
//重构前
class Person {
var name: String = ""
init(name: String) {
self.name = name
}
}
//重构后
class Person {
private var name: String = ""
init(name: String) {
self.name = name
}
func getName() -> String {
return name
}
func setName(name: String) {
self.name = "China:" + name
}
}
十、Encapsulate Collection(封装集合)
“封装集合”这一重构规则应该来说并不难理解。当你的类中有集合时,为了对该集合进行封装,你需要为集合创建相应的操作方法,例如增删改查等等。下方就通过一个不封装集合的实例,看一下缺点。然后将其重构。关于“封装集合”具体的细节参见下方实例。
1.未封装集合的实例
下方我们先创建一个图书馆图书类,为了简化示例,该图书类只有一个书名。下方代码段就是这个图书类,如下所示:
class LibraryBook {
private var name: String
init(name: String) {
self.name = name
}
func getName() -> String {
return self.name
}
}
紧接着要创建一个借书者,借书者中有两个字段,一个是借书者的名字,另一个是所借书籍的数组。在Lender中我们没有为lendBooks数组封装相应的方法,只为其提供了getter/setter方法,具体代码如下所示。
class Lender {
private var name: String
private var lendBooks: Array<LibraryBook> = []
init(name: String) {
self.name = name
}
func getName() -> String {
return self.name
}
func setLendBooks(books: Array<LibraryBook>) {
self.lendBooks = books
}
func getLendBooks() -> Array<LibraryBook> {
return self.lendBooks
}
}
紧接着我们要创建一个测试用例,观察这两个类的使用方式。由下面程序的注释可知,首先我们需要创建一个books的数组,该数组就像一个篮子似的,它可以存储我们要借的书籍。让后将创建的书籍添加到该数组中,最后将books赋值给借书人中的lendBooks。如果要对书籍进行修改,那么只有先获取借书人的lendBooks, 然后进行修改,最后再将修改后的值赋值回去。
//先创建一个书籍数组
var books: Array<LibraryBook> = []
//添加要借的书籍
books.append(LibraryBook(name: "《雪碧加盐》"))
books.append(LibraryBook(name: "《格林童话》"))
books.append(LibraryBook(name: "《智慧意林》"))
//创建借书人
let lender: Lender = Lender(name: "ZeluLi")
lender.setLendBooks(books)
//获取所借书籍
var myBooks = lender.getLendBooks()
//对书籍数组修改后再赋值回去
myBooks.removeFirst()
lender.setLendBooks(myBooks)2.为上面的Lender类添加相应的集合操作的方法
由上面的测试用例可以看出,Lender类封装的不好。因为其使用方式以及调用流程太麻烦,所以我们得重新对其进行封装。所以就会用到“Encapsulate Collection”原则。下面我们就会为Lender添加上相应的集合操作的方法。说白了,就是讲上面测试用例做的一部分工作放到Lender类中。下方是为Lender添加的对lendBooks相应的操作方法。下方代码中的Lender类与上面的Lender类中的lendBooks不同,我们使用了另一个集合类型,也就是字典,而字典的key就是书名,字典的值就是书的对象。具体代码如下所示:

经过上面这样一封装的话,使用起来就更为合理与顺手了。用大白话讲,就是好用。下方是我们重新封装后的测试用例,简单了不少,而且组织也更为合理。具体请看下方代码段:

十一、Replace Subclass with Fields(以字段取代子类)
什么叫“以字段取代子类”呢?就是当你的各个子类中唯一的差别只在“返回常量数据”的函数上。当遇到这种情况时,你就可以将这个返回的数据放到父类中,并在父类中创建相应的工厂方法,然后将子类删除即可。直接这样说也许有些抽象,接下来,我们会通过一个小的Demo来看一下这个规则具体如何应用。1.创建多个子类,并每个子类只有一个函数的返回值不同
接下来我们就要创建重构前的代码了。首先我们创建一个PersonType协议(也就是一个抽象类),该协议有两个方法,一个是isMale(),如果是子类是男性就返回true,如果子类是女性就返回false。还有一个是getCode()函数,如果子类是男性就返回“M”,如果是子类是女性就返回“F”。 这两个子类的差别就在于各个函数返回的值不同。下方是PersonType的具体代码。
1 protocol PersonType {
2 func isMale() -> Bool
3 func getCode() -> String
4 }然后我们基于PersonType创建两个子类,一个是Male表示男性,一个是Female表示女性。具体代码如下:
class Male: PersonType {
func isMale() -> Bool {
return true
}
func getCode() -> String {
return SenderCode.Male.rawValue
}
}
class Female: PersonType {
func isMale() -> Bool {
return false
}
func getCode() -> String {
return SenderCode.Female.rawValue
}
}上述代码的SenderCode是我们自定义的枚举类型,用来表示"M"与“F”,枚举的代码如下:
1 enum SenderCode: String {
2 case Male = "M"
3 case Female = "F"
4 }2.以字段取代子类
从上面的代码容易看出,Male与Female类实现相同的接口,但接口函数在两个类中的返回值是不同的。这时候我们就可以使用“以字段取代子类”的方式来进行重构,下方截图就是重构后的代码片段。
下方代码中,将PersonType声明了一个类,在类中添加了两个字段,一个是isMale,另一个是code,这两个字段恰好是上述两个子类函数中返回的不同值。这也就是使用字段来取代子类,因为有了这两个字段,我们就可以不用去创建子类了,而是直接在PersonType中通过工厂方法根据不同的性别分别给这两个新加的字段赋上不同的值。具体做法如下。

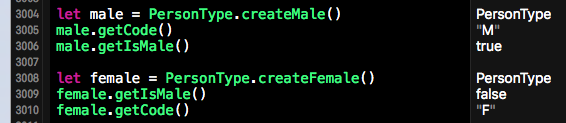
经过上面这段代码重构后,我们就可以调用PersonType的不同的工厂方法来创建不同的性别了。测试用例如下所示:
OK~今天博客的内容也够多的了,那就先到这儿。关于重构的其他规则,还会在后期的博客中继续更新。