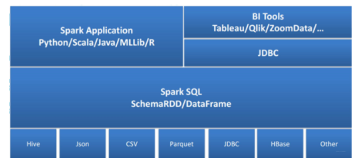
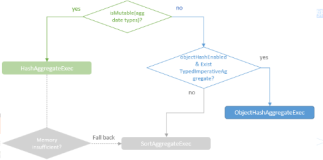
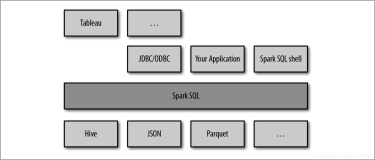
引入 hadoop 的core-site.xml
加入与之对应版本的Spark-client
和Spark-Sql 依赖 这是一个简单SparkSql 方式的Word-count 的例子
···
package com.xxx
import org.apache.spark.sql.SparkSession
object WordCount {
def main(args: Array[String]): Unit = {
val spark =SparkSession.builder().master("local[*]").appName("spark sql word count").getOrCreate()
//连接hdfs
//导入隐式转换
import spark.implicits._
import spark.sql//导入文件
val rdd=spark.sparkContext.textFile("/user_info.txt")
val ds =rdd toDS()
ds.printSchema()
ds.createOrReplaceTempView("line_str")
val wcResult =sql(
"""
|select word
| ,count(1) as count
| from(
| select explode(split(value,'')) as word
| from line_str
| )
| group by word
""".stripMargin)
wcResult.show()}
}
···