热门
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
使用 Java 进行桌面应用开发
Java 中文官方教程 2022 版(二十一)(4)
Java 中的单元测试和集成测试策略
Java 中文官方教程 2022 版(二十一)(3)
Java 中文官方教程 2022 版(二十一)(2)
探索Java的未来发展趋势和新技术
Java 中文官方教程 2022 版(二十一)(1)
Java 中文官方教程 2022 版(二十)(4)
Java 中文官方教程 2022 版(二十)(3)
Java 中文官方教程 2022 版(二十)(2)
Java 中文官方教程 2022 版(二十)(1)
Java 中文官方教程 2022 版(十九)(4)
平台设计-联系信息的存储
Java 中文官方教程 2022 版(十九)(3)
平台设计-用户数据来源
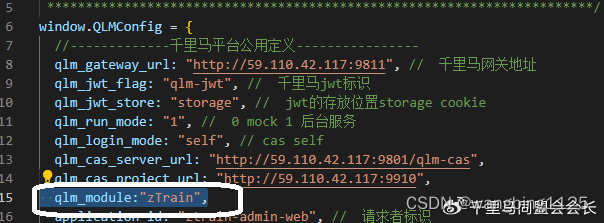
平台设计-moduleID的使用
Java 中文官方教程 2022 版(十九)(2)
前端场景的代码部署方式都有那些?
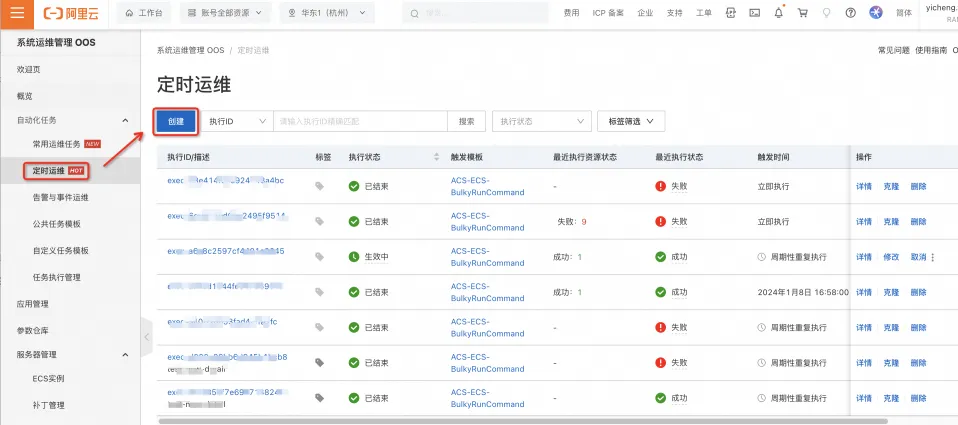
通过OOS实现定时备份Redis实例转储到OSS
Java 中文官方教程 2022 版(十九)(1)
前端目前的发展状况有哪些挑战和机遇呢
前端发展史
Oracle数据守卫(DG):数据的“守护者”与“时光机”
平台设计-字典缓存
平台设计-部署模式
深入了解API:详解应用程序接口的作用和原理
平台设计-功能权限
平台设计-数据相关类
平台设计-系统配置
平台设计-字典管理
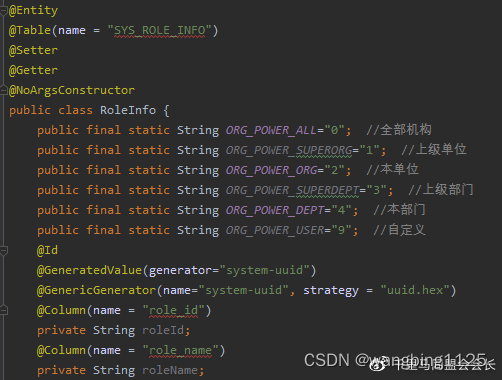
平台设计-用户权限体系
Oracle 12c的TOP N语句:数据排名的“快速通道”
Oracle 12c的临时UNDO:数据的“临时保镖”
Java 中文官方教程 2022 版(十八)(4)
Java 中文官方教程 2022 版(十八)(3)
Oracle 12c的Adaptive执行计划:数据的“聪明导航员”
Oracle 12c的内存列存储:数据的“闪电侠”
Java 中文官方教程 2022 版(十八)(2)
Oracle 12c的多重索引:数据的“多维导航仪”
开发指南021-swagger的使用
Oracle 12c的不可见字段:数据的“隐形斗篷”
开发指南020-banner
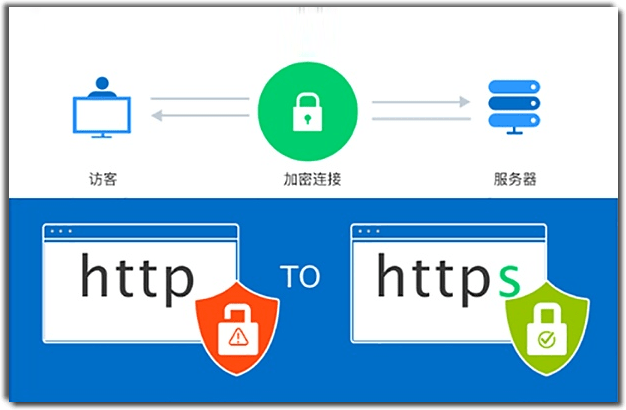
深入理解SSL数字证书:定义、工作原理与网络安全的重要性
Java 中文官方教程 2022 版(十八)(1)
Oracle 12c的自动数据优化(ADO)与热图:数据管理的“瘦身”与“透视”艺术
开发指南019-版本标识
开发指南018-前端存储
开发指南017- 移动前端结构