热门
万字长文:一文彻底搞懂Elasticsearch中Geo数据类型查询、聚合、排序
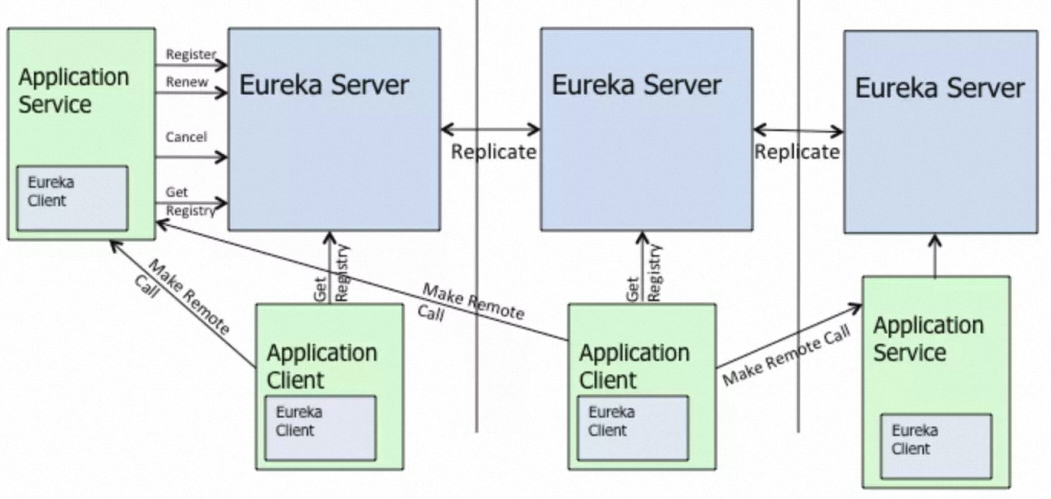
上一任留下的 Eureka,我该如何提升她的性能和稳定性(含数据比对)?
蚂蚁流场景状态演进和优化
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
探索未来智能手机操作系统的发展趋势
新兴科技的趋势与应用:探索未来发展之路
优化后端性能:提升Web应用响应速度的关键策略
跨界思维:技术与创新的奇妙交融
Linux下远程访问Jupyter Notebook 配置
阿里云中小企业上云特惠专场活动简介
现代化运维管理:挑战与机遇
【CSS进阶】使用CSS gradient制作绚丽渐变纹理背景效果(下)
【CSS进阶】使用CSS gradient制作绚丽渐变纹理背景效果(中)
【CSS进阶】使用CSS gradient制作绚丽渐变纹理背景效果(上)
JS数组reduce()方法详解及高级技巧
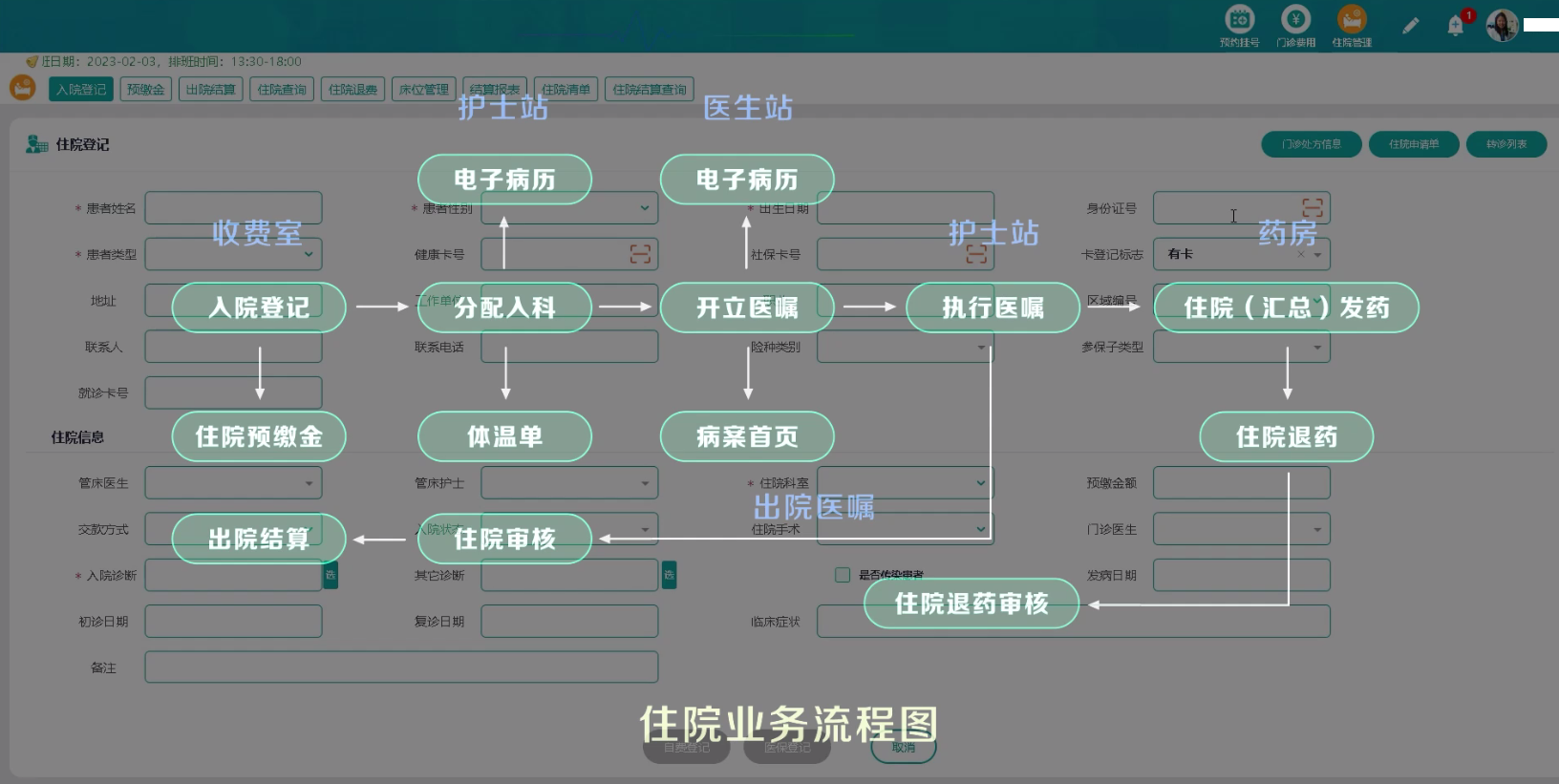
B/S架构,采用JAVA编程的医院云HIS系统源码,公立二甲医院应用案例
javascript数据处理和筛选
前端算法-最大三角形面积-鞋带公式&-海伦公式
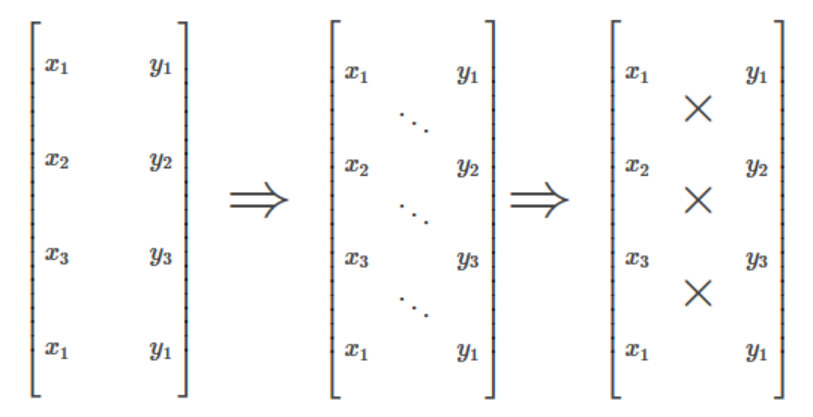
转置矩阵-暴力解法&一行代码
有多少小于当前数字的数字
Vue-实现点击空白处隐藏某节点
人工智能在当代社会中的应用与未来发展趋势 摘要:
Ip校验规则:以,分割IP字符串
ElementUi配置自定义校验规则-校验IP和IP段
287--寻找重复数-indexOf-&&-sort
计算机常用基础常识笔记分享
FastAI 之书(面向程序员的 FastAI)(四)
【leetcode】221--最大正方形-动态规划法
【leetcode】204--计数质数-暴力-&-埃拉托斯特尼法
Pandas与数据库交互:实现高效数据交换与存储
「一劳永逸」送你21道高频JavaScript手写面试题(下)
Pandas进阶学习:探索更多高级特性与技巧
Pandas常见问题与解决方案:避开数据处理中的坑
「一劳永逸」送你21道高频JavaScript手写面试题(上)
Pandas实战案例:电商数据分析的实践与挑战
实战案例:Pandas在金融数据分析中的应用
Pandas与其他库的集成:构建强大的数据处理生态
贪心算法】按要求补齐数组
【CSS进阶】巧用伪元素before和after制作绚丽效果(下)
Pandas性能优化与高级功能:让数据处理更高效
【CSS进阶】巧用伪元素before和after制作绚丽效果(中)
【CSS进阶】巧用伪元素before和after制作绚丽效果(上)
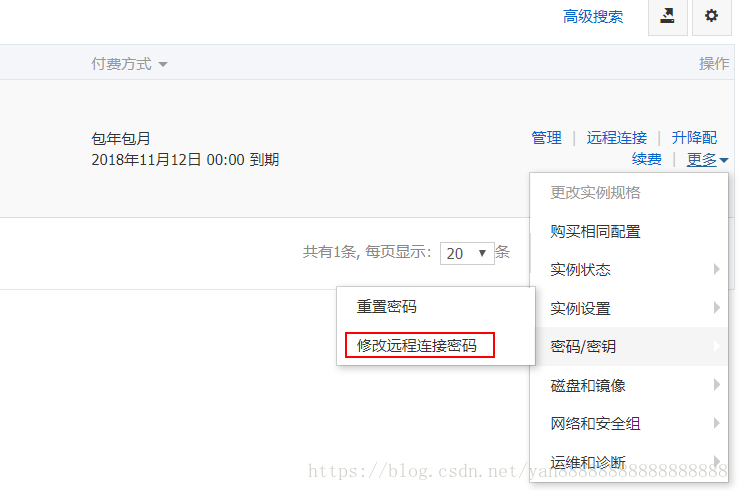
阿里云ecs使用体验
前端算法 岛屿的最大面积 DFS(深度优先搜索)
esc使用体验心得
【leetcode】221. 最大正方形 动态规划法