BI项目中经常会有一些提取,转换,数据处理(ELT)的工作,其中最主要的是处理过赃数据。假设在项目中我们向数据库中注入了测试数据,但是通过一个外键从另外一个表中载入数据的时候没有对应的数据,那么这一行就是赃数据。这时候可以使用SQL中的Sound-Ex,full-text,相似度算法等方法查找。这种策略需要花费大量的时间和精力来设计算法,测试,维护,并且它们都是基于词汇的,复用的可能性很小。也可能你会放弃自己处理并把它抛给一些有经验的高手专家来做这些工作,也可能你会在表中添加一些新的数据已达到外健关联的目的,但是这种方法被称作Lazy-add(懒惰的做法)。因为是手工添加数据难免会带来拼写错误,例如将职务名称president错误地写成平parsedent,将further错误地写成future,将present错误地写成parent,等等。
模糊查找和模糊分组提供一种新的方法来处理这种赃数据。这种转换使得处理数据变得简单,可兼容,可伸缩,可复用,它可以明显地减少误差。如果你的表中有赃数据,或者你开始处理数据,你会使用模糊分组来找出冗余数据。模糊分组会对表中的一列数据进行分析归纳出相似的并假设他们是某一个单词的错误拼写,进而计算出他们之间的相似度,利用这个相似度的数据可以 清洗表中数据。
如果你使用模糊查找来校正数据,建议先使用关键词查找,这是因为模糊查找非常耗费资源。它会在数据表和参照表中建立索引。可以保存这些索引,但是这样做会耗费耗费掉磁盘空间,并在运行的时候耗费宝贵的内存资源。通过模糊查找得到一个关键词列表是一个很好的策略。通过关键词查找找出出现频率较高的关键词,模糊查找再使用内连接来超出匹配项。如果还是有些数据不能匹配,将会把它标记为unknow。
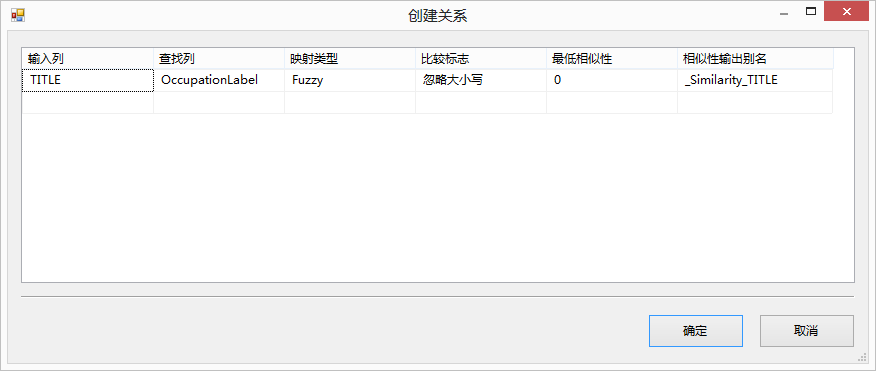
模糊查找要求输入流中至少有一列是字符串,这点和关键词提取有些不同,关键词提取要求是NULL-terminated Unicode 字符串。模糊查找还需要连接到一个外键表作为参照。模糊查找的输出列如下:
- 输入数据:这些数据包含输入流中的数据和需要从模糊查找中传递的数据
- 参照表数据:这些数据包含参照表中的数据
- 相似度:这一列数据是介于0和1之间的浮点数,用来描述相似程度,相似度是1表明匹配完全成功
- Confidence:这一列数据是介于0和1之间的浮点数,用来描述匹配的信任程度。Confidence是另外一种形式的相似度,他不是通过一对一的比较得来,而是通过一对多的比较得来。它可以获得更加准确的数据。
在模糊查找的编辑界面有3个标签
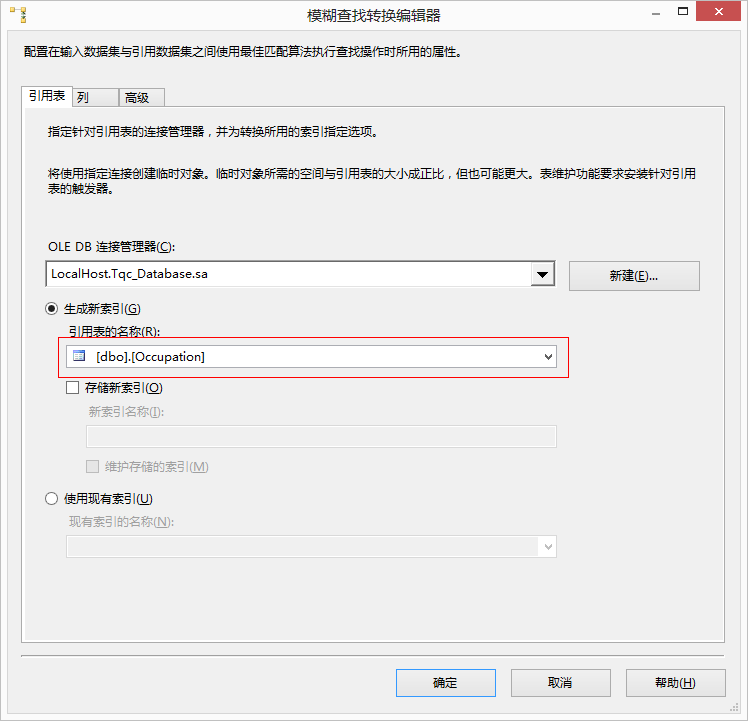
- 参照表:在这个标签内设置一个连接到参照表的OLE DB Connection。比较之前模糊查找参照这个表中的数据建立一个索引。在这个标签可以选择保存这个索引或者使用先前运行时保存的索引,还可以维护当前索引,这样会删除以前的索引保存本次运行时得到的索引。这里要提醒的是如果处理的数据量很大,索引也会变得很大。
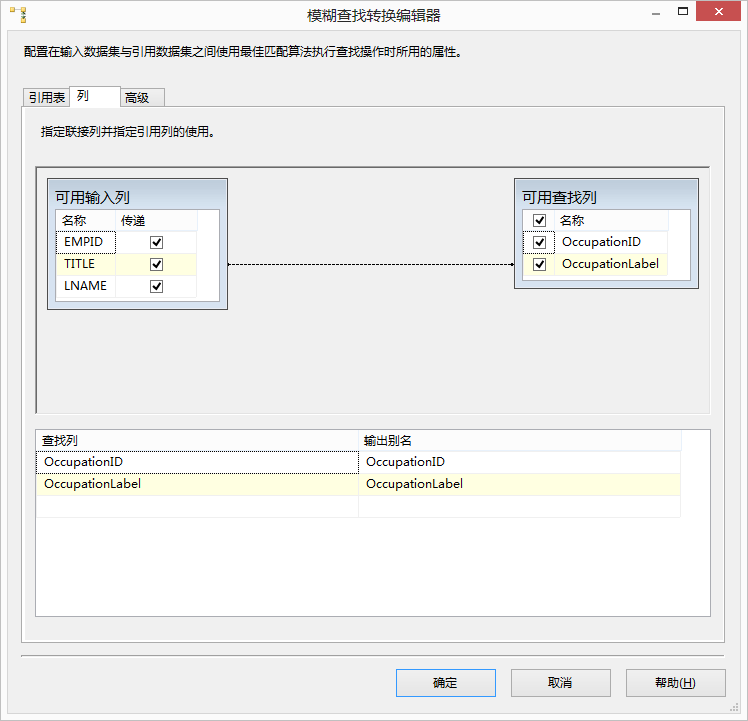
- 列:在这个标签内设置输入数据流中列和参照表中的一列的映射。用鼠标拖拽的方法将他们连接起来。还可以在输出数据流中添加一个外键列,只需要在Available Input Columns中选择这个列旧可以了。
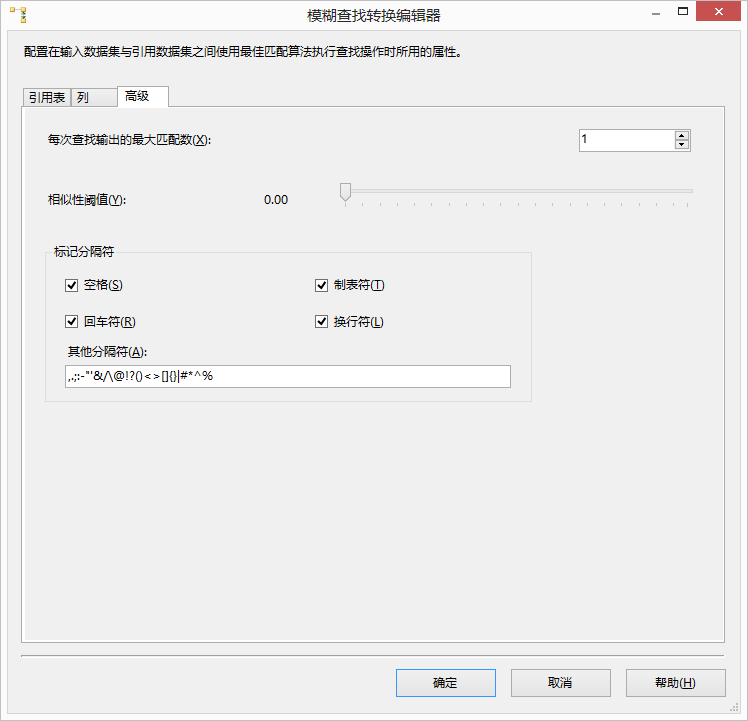
- 高级:这个标签内设置查找算法。Maximum number of matches to output per lookup设置每一行数据最多可以有多少个匹配。默认的值是1,如果设置大于这个值,结果中将产生更多的行,但是如果输入流数据中有很多类似的数据这种设置还是需要的。Similarity threshold用来设置相似度阀置。Token delimiters用来设置字符分割符,默认的分割符是常见字符串分割符。
尽管模糊查找通过一些简单的设置来实现复杂的逻辑,结果页并不是完美的。需要花费一些时间来观察不同设置产生的不同结果。
建立测试环境:
使用下面的内容创建一个文本文件并命名:empdata.txt,这个表包含的内容是个人信息。我们可以看到这个表中的数据参差不齐,这些是ETL过程中常见的情况。
EMPID TITLE LNAME
00001 EXECUTIVE VICE PRESIDENWASHINGTON
00002 EXEC VICE PRES PIZUR
00003 EXECUTIVE VP BROWN
00005 EXEC VP MILLER
00006 EXECUTIVE VICE PRASIDENSWAMI
00007 FIELDS OPERATION MGR SKY
00008 FLDS OPS MGR JEAN
00009 FIELDS OPS MGR GANDI
00010 FIELDS OPERATIONS MANAGHINSON
00011 BUSINESS OFFICE MANAGERBROWN
00012 BUS OFFICE MANAGER GREEN
00013 BUS OFF MANAGER GATES
00014 BUS OFF MGR HALE
00015 BUS OFFICE MNGR SMITH
00016 BUS OFFICE MGR AI
00017 X-RAY TECHNOLOGIST CHIN
00018 XRAY TECHNOLOGIST ABULA
00019 XRAY TECH HOGAN
00020 X-RAY TECH ROBERSON
在数据库中使用下面的语句创建一个参照表,创建Occupation表:
CREATE TABLE [Occupation] ( [OccupationID] [smallint] IDENTITY(1, 1) NOT NULL , [OccupationLabel] [varchar](50) NOT NULL CONSTRAINT [PK_Occupation_OccupationID] PRIMARY KEY CLUSTERED ( [OccupationID] ASC ) ON [PRIMARY] ) ON [PRIMARY] GO INSERT INTO [Occupation] SELECT 'EXEC VICE PRES' INSERT INTO [Occupation] SELECT 'FIELDS OPS MGR' INSERT INTO [Occupation] SELECT 'BUS OFFICE MGR' INSERT INTO [Occupation] SELECT 'X-RAY TECH' SELECT * FROM [Occupation]
模糊查找可以找出数据中可能重复的行,例如可以找出包含“Main St.”和“Main Street”的两行然后将他们合并成一行。模糊查找任务可以检查数据输入并清除脏数据。模糊查找任务通常放在查找任务之后,查找任务找到匹配数据,然后通过模糊查找没有匹配的数据。
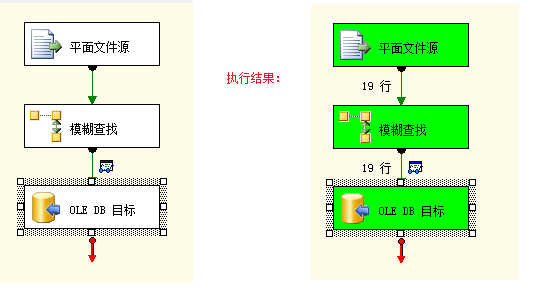
数据流任务步骤: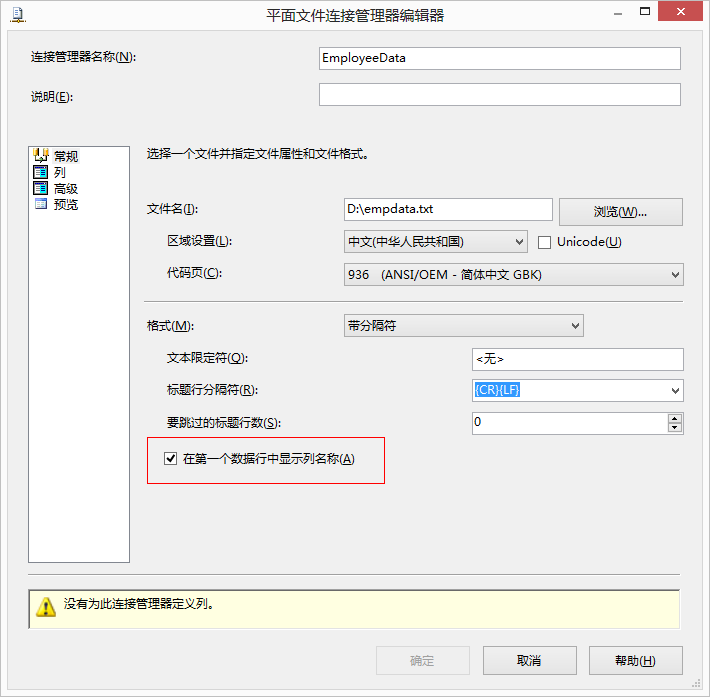
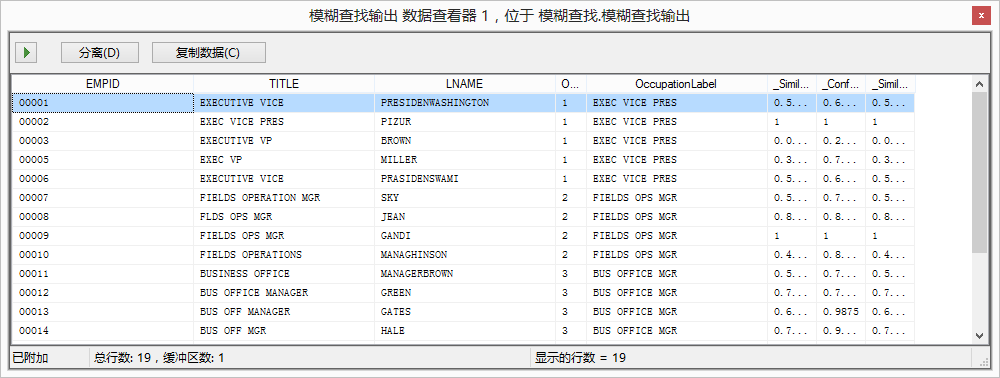
运行结果: