这两天,我拜读了 Dennis Byrne 写的一片博文Memory Barriers and JVM Concurrency (中译文内存屏障与JVM并发)。
文中提到:
对主存的一次访问一般花费硬件的数百次时钟周期。处理器通过缓存(caching)能够从数量级上降低内存延迟的成本这些缓存为了性能重新排列待定内存操作的顺序。也就是说,程序的读写操作不一定会按照它要求处理器的顺序执行。
这段话是作者对内存屏障重要性的定义。通过cache降低内存延迟,这句话很好理解。但后面那句“为了性能重排序内存操作顺序”,让没学好微机原理的我倍感疑惑。
CPU为何要重排序内存访问指令?在哪种场景下会触发重排序?作者在文中并未提及。
为了解答疑问,我在网上查阅了一些资料,在这里跟大家分享一下。
重排序的背景
我们知道现代CPU的主频越来越高,与cache的交互次数也越来越多。当CPU的计算速度远远超过访问cache时,会产生cache wait,过多的cache ?wait就会造成性能瓶颈。
针对这种情况,多数架构(包括X86)采用了一种将cache分片的解决方案,即将一块cache划分成互不关联地多个 slots (逻辑存储单元,又名 Memory Bank 或 Cache Bank),CPU可以自行选择在多个 idle bank 中进行存取。这种 SMP 的设计,显著提高了CPU的并行处理能力,也回避了cache访问瓶颈。
Memory Bank的划分
一般 Memory bank 是按cache address来划分的。比如 偶数adress 0×12345000?分到 bank 0, 奇数address 0×12345100?分到 bank1。
重排序的种类
编译期重排。编译源代码时,编译器依据对上下文的分析,对指令进行重排序,以之更适合于CPU的并行执行。
运行期重排,CPU在执行过程中,动态分析依赖部件的效能,对指令做重排序优化。
实例讲解指令重排序原理
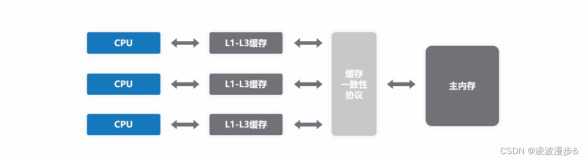
为了方便理解,我们先来看一张CPU内部结构图。

从图中可以看到,这是一台配备双CPU的计算机,cache 按地址被分成了两块 cache banks,分别是?cache bank0 和 cache bank1。
理想的内存访问指令顺序:
1,CPU0往?cache address 0×12345000 写入一个数字 1。因为address 0×12345000是偶数,所以值被写入 bank0.
2,CPU1读取 bank0 address 0×12345000 的值,即数字1。
3,CPU0往 cache 地址 0×12345100 ?写入一个数字 2。因为address 0×12345100是奇数,所以值被写入 bank1.
4,CPU1读取 bank1 address ?0×12345100 的值,即数字2。
重排序后的内存访问指令顺序:
1,CPU0 准备往 bank0 address 0×12345000 写入数字 1。
2,CPU0检查 bank0 的可用性。发现 bank0 处于 busy 状态。
3, CPU0 为了防止 cache等待,发挥最大效能,将内存访问指令重排序。即先执行后面的 bank1 address 0×12345100 数字2的写入请求。
4,CPU0检查 bank1 可用性,发现bank1处于 idle 状态。
5,CPU0 将数字2写入 bank 1 address 0×12345100。
6,CPU1来读取 ?0×12345000,未读到 数字1,出错。
7, CPU0 继续检查 bank0 的可用性,发现这次?bank0 可用了,然后将数字1写入 0×12345000。
8, CPU1 读取 0×12345100,读到数字2,正确。
从上述触发步骤中,可以看到第 3 步发生了指令重排序,并导致第 6步读到错误的数据。
通过对指令重排,CPU可以获得更快地响应速度,但也给编写并发程序的程序员带来了诸多挑战。
内存屏障是用来防止CPU出现指令重排序的利器之一。
通过这个实例,不知道你对指令重排理解了没有?
不同架构下的指令重排优化
X86仅在 Stores after loads 和 Incoherent instruction cache pipeline 中会触发重排。
Stores after loads的含义是在对同一个地址进行读写操作时,写入在读取后面,允许重排序。即满足弱一致性(Weak Consistency),这是最可被接受的类型,不会造成太大的影响。
Incoherent instruction cache pipeline是跟JIT相关的类型,作用是在执行self-modifying code 时预防JIT没有flush指令缓存。我不知道该类型跟指令排序有什么关系,既然不在本文涉及范围内,就不做深入探讨了。