原文:
使用SQL语句创建SQL数据脚本(应对万网主机部分不支持导出备份数据)

 View Code
View Code
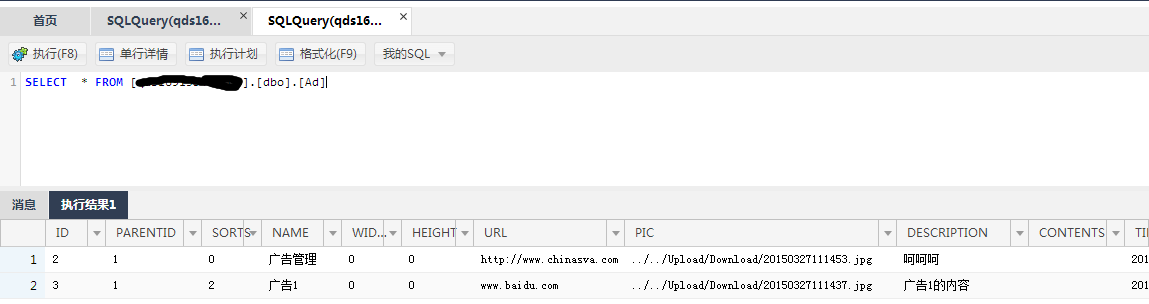
1、查询待导出表
Ad中的数据。
SELECT * FROM [DB_Temp].[dbo].[Ad]
2、编写存储过程。
1 --将表数据生成SQL脚本的存储过程 2 3 CREATE PROCEDURE dbo.UspOutputData 4 @tablename sysname 5 AS 6 declare @column varchar(1000) 7 declare @columndata varchar(1000) 8 declare @sql varchar(4000) 9 declare @xtype tinyint 10 declare @name sysname 11 declare @objectId int 12 declare @objectname sysname 13 declare @ident int 14 15 set nocount on 16 set @objectId=object_id(@tablename) 17 18 if @objectId is null -- 判断对象是否存在 19 begin 20 print 'The object not exists' 21 return 22 end 23 set @objectname=rtrim(object_name(@objectId)) 24 25 if @objectname is null or charindex(@objectname,@tablename)=0 --此判断不严密 26 begin 27 print 'object not in current database' 28 return 29 end 30 31 if OBJECTPROPERTY(@objectId,'IsTable') < > 1 -- 判断对象是否是table 32 begin 33 print 'The object is not table' 34 return 35 end 36 37 select @ident=status&0x80 from syscolumns where id=@objectid and status&0x80=0x80 38 39 if @ident is not null 40 print 'SET IDENTITY_INSERT '+@TableName+' ON' 41 42 declare syscolumns_cursor cursor 43 44 for select c.name,c.xtype from syscolumns c where c.id=@objectid order by c.colid 45 46 open syscolumns_cursor 47 set @column='' 48 set @columndata='' 49 fetch next from syscolumns_cursor into @name,@xtype 50 51 while @@fetch_status < >-1 52 begin 53 if @@fetch_status < >-2 54 begin 55 if @xtype not in(189,34,35,99,98) --timestamp不需处理,image,text,ntext,sql_variant 暂时不处理 56 57 begin 58 set @column=@column+case when len(@column)=0 then'' else ','end+@name 59 60 set @columndata=@columndata+case when len(@columndata)=0 then '' else ','','',' 61 end 62 63 +case when @xtype in(167,175) then '''''''''+'+@name+'+''''''''' --varchar,char 64 when @xtype in(231,239) then '''N''''''+'+@name+'+''''''''' --nvarchar,nchar 65 when @xtype=61 then '''''''''+convert(char(23),'+@name+',121)+''''''''' --datetime 66 when @xtype=58 then '''''''''+convert(char(16),'+@name+',120)+''''''''' --smalldatetime 67 when @xtype=36 then '''''''''+convert(char(36),'+@name+')+''''''''' --uniqueidentifier 68 else @name end 69 70 end 71 72 end 73 74 fetch next from syscolumns_cursor into @name,@xtype 75 76 end 77 78 close syscolumns_cursor 79 deallocate syscolumns_cursor 80 81 set @sql='set nocount on select ''insert '+@tablename+'('+@column+') values(''as ''--'','+@columndata+','')'' from '+@tablename 82 83 print '--'+@sql 84 exec(@sql) 85 86 if @ident is not null 87 print 'SET IDENTITY_INSERT '+@TableName+' OFF' 88 89 GO 90 91 exec UspOutputData 你的表名
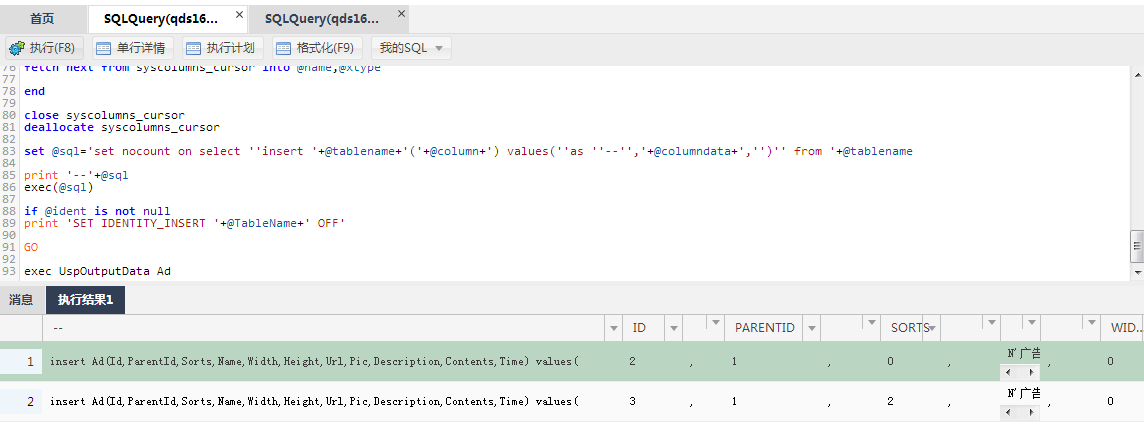
2、执行存储过程
复制第一行数据:
insert Ad(Id,ParentId,Sorts,Name,Width,Height,Url,Pic,Description,Contents,Time) values( 2,1,0,N'广告1',0,0,N'www.baidu.com',N'../../Upload/Download/20150327111437.jpg',N'广告1的内容',N'','2015-03-27 11:14:40.000')
Look!We got it!
存储过程摘自:http://bbs.csdn.net/topics/300135193





