序言
本篇主要目的有二:
1、看懂t-sql的执行计划,明白执行计划中的一些常识。
2、能够分析执行计划,找到优化sql性能的思路或方案。
如果你对sql查询优化的理解或常识不是很深入,那么推荐几骗博文给你:SqlServer性能检测和优化工具使用详细 ,sql语句的优化分析,T-sql语句查询执行顺序。
执行计划简介
1、什么是执行计划?
大哥提交的sql语句,数据库查询优化器,经过分析生成多个数据库可以识别的高效执行查询方式。然后优化器会在众多执行计划中找出一个资源使用最少,而不是最快的执行方案,给你展示出来,可以是xml格式,文本格式,也可以是图形化的执行方案。
2、预估执行计划,实际执行计划

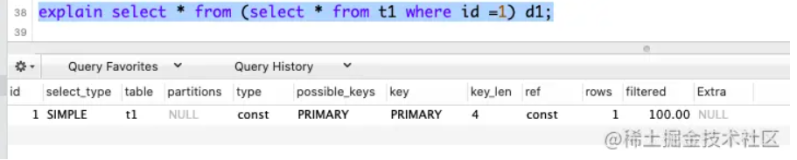
选择语句,点击上面其中一个执行计划,预估执行计划可以立即显示,而实际执行计划则需要执行sql语句后出现。预估执行计划不等于实际执行计划,但是绝大多数情况下实际的执行计划跟预估执行计划都是一致的。统计信息变更或者执行计划重编译等情况下,会造成不同。
3、为什么要读懂执行计划
首先执行计划让你知道你复杂的sql到底是怎么执行的,有没有按照你想的方案执行,有没有按照最高效的方式执行,使用啦众多索引的哪一个,怎么排序,怎么合并数据的,有没有造成不必要资源浪费等等。官方数据显示,执行t-sql存在问题,80%都可以在执行计划中找到答案。
4、针对图形化执行计划分析
执行计划,可以以文本,xml,图形化展示出来。本骗主要以图形化执行计划主导进行分析,然而执行计划中包含78个可用的操作符,本篇也只能对常用的进行分析,常用的几乎就包含你日常所有的了。Msdn上有图片介绍:https://msdn.microsoft.com/zh-cn/library/ms175913(v=sql.90).aspx
5、怎么看执行计划
图形化执行计划是从上到下从又到左看的。
6、清除缓存的执行计划
dbcc freeprocache
dbcc flushprocindb(db_id)
看懂图形化执行计划
1、连线
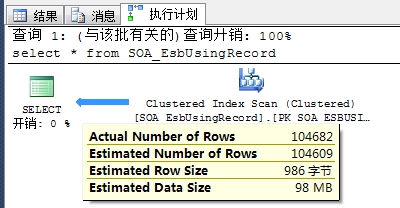
1、越粗表示扫描影响的行数愈多。
2、Actual Number of Rows 扫描中实际影响的的行数。
3、Estimated Number of Rows 预估扫描影响的行数。
4、Estimated row size 操作符生成的行的估计大小(字节)。
5、Estimated Data Size 预估影响的数据的大小。
2、Tooltips,当前步骤执行信息
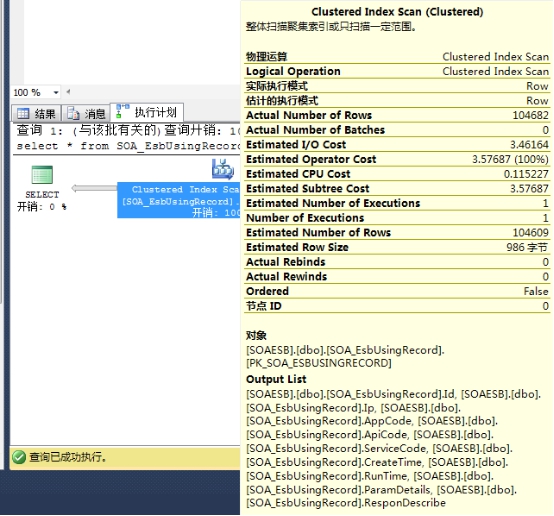
Note:这个tips的信息告诉我们执行的对象是什么,采用的操作操作是什么,查找的数据是什么,使用的索引是什么,排序与否,预估cpu、I/O、影响行数,实际行数等信息。具体参数清单参见msdn:https://msdn.microsoft.com/zh-cn/library/ms178071(v=sql.90).aspx
3、Table Scan(表扫描)

当表中没有聚集索引,又没有合适索引的情况下,会出现这个操作。这个操作是很耗性能的,他的出现也意味着优化器要遍历整张表去查找你所需要的数据。
4、Clustered Index Scan(聚集索引扫描)、Index Scan(非聚集索引扫描)

这个图标两个操作都可以使用,一个聚集索引扫描,一个是非聚集索引扫描。
聚集索引扫描:聚集索引的数据体积实际是就是表本身,也就是说表有多少行多少列,聚集所有就有多少行多少列,那么聚集索引扫描就跟表扫描差不多,也要进行全表扫描,遍历所有表数据,查找出你想要的数据。
非聚集索引扫描:非聚集索引的体积是根据你的索引创建情况而定的,可以只包含你要查询的列。那么进行非聚集索引扫描,便是你非聚集中包含的列的所有行进行遍历,查找出你想要的数据。
5、Key Lookup(键值查找)

首先需要说的是查找,查找与扫描在性能上完全不是一个级别的,扫描需要遍历整张表,而查找只需要通过键值直接提取数据,返回结果,性能要好。
当你查找的列没有完全被非聚集索引包含,就需要使用键值查找在聚集索引上查找非聚集索引不包含的列。
6、RID Lookoup(RID查找)

跟键值查找类似,只不过RID查找,是需要查找的列没有完全被非聚集索引包含,而剩余的列所在的表又不存在聚集索引,不能键值查找,只能根据行表示Rid来查询数据。
7、Clustered Index Seek(聚集索引查找)、Index Seek(非聚集索引查找)

聚集索引查找和非聚集索引查找都是使用该图标。
聚集索引查找:聚集索引包含整个表的数据,也就是在聚集索引的数据上根据键值取数据。
非聚集索引查找:非聚集索引包含创建索引时所包含列的数据,在这些非聚集索引的数据上根据键值取数据。
8、Hash Match

这个图标有两种地方用到,一种是表关联,一种是数据聚合运算时。
再分别说这两中运算的前面,我先说说Hashing(编码技术)和Hash Table(数据结构)。
Hashing:在数据库中根据每一行的数据内容,转换成唯一符号格式,存放到临时哈希表中,当需要原始数据时,可以给还原回来。类似加密解密技术,但是他能更有效的支持数据查询。
Hash Table:通过hashing处理,把数据以key/value的形式存储在表格中,在数据库中他被放在tempdb中。
接下来,来说说Hash Math的表关联跟行数据聚合是怎么操作运算的。
表关联:
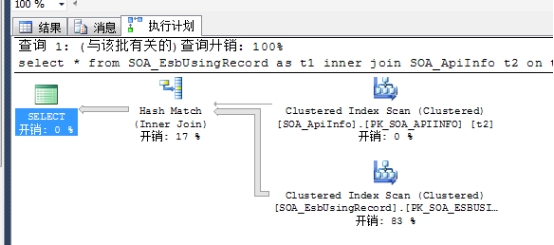
如上图,关联两个数据集时,Hash Match会把其中较小的数据集,通过Hashing运算放入HashTable中,然后一行一行的遍历较大的数据集与HashTable进行相应的匹配拉取数据。
数据聚合:当查询中需要进行Count/Sum/Avg/Max/Min时,数据可能会采用把数据先放在内存中的HashTable中然后进行运算。
9、Nested Loops
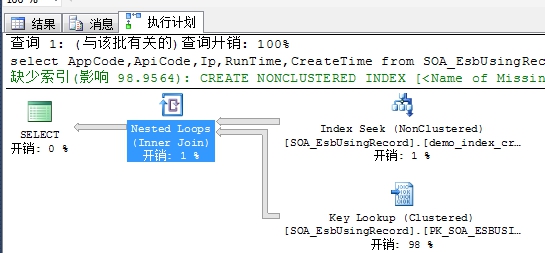
这个操作符号,把两个不同列的数据集汇总到一张表中。提示信息中的Output List中有两个数据集,下面的数据集(inner set)会一一扫描与上面的数据集(out set),知道扫描完为止,这个操作才算是完成。
10、Merge Join
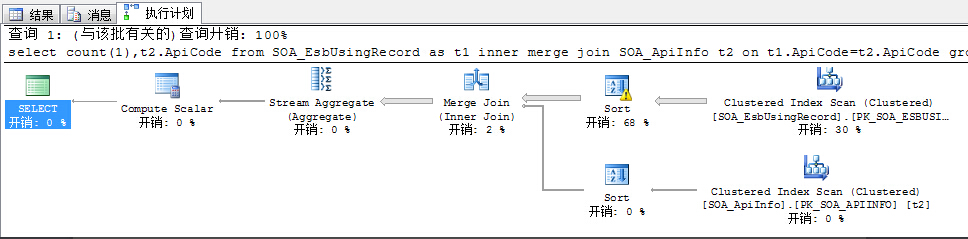
这种关联算法是对两个已经排过序的集合进行合并。如果两个聚合是无序的则将先给集合排序再进行一一合并,由于是排过序的集合,左右两个集合自上而下合并效率是相当快的。
11、Sort(排序)

对数据集合进行排序,需要注意的是,有些数据集合在索引扫描后是自带排序的。
12、Filter(筛选)

根据出现在having之后的操作运算符,进行筛选
13、Computer Scalar

在需要查询的列中需要自定义列,比如count(*) as cnt ,select name+''+age 等会出现此符号。
根据执行计划细节要做的优化操作
这里会有很多建议给出,我不一一举例了,给出几个示例,想做到优化行家,多的还需要大家去悟去理解。
1、如果select * 通常情况下聚集索引会比非聚集索引更优。
2、如果出现Nested Loops,需要查下是否需要聚集索引,非聚集索引是否可以包含所有需要的列。
3、Hash Match连接操作更适合于需要做Hashing算法集合很小的连接。
4、Merge Join时需要检查下原有的集合是否已经有排序,如果没有排序,使用索引能否解决。
5、出现表扫描,聚集索引扫描,非聚集索引扫描时,考虑语句是否可以加where限制,select * 是否可以去除不必要的列。
6、出现Rid查找时,是否可以加索引优化解决。
7、在计划中看到不是你想要的索引时,看能否在语句中强制使用你想用的索引解决问题,强制使用索引的办法Select CluName1,CluName2 from Table with(index=IndexName)。
8、看到不是你想要的连接算法时,尝试强制使用你想要的算法解决问题。强制使用连接算法的语句:select * from t1 left join t2 on t1.id=t2.id option(Hash/Loop/Merge Join)
9、看到不是你想要的聚合算法是,尝试强制使用你想要的聚合算法。强制使用聚合算法的语句示例:select age ,count(age) as cnt from t1 group by age option(order/hash group)
10、看到不是你想要的解析执行顺序是,或这解析顺序耗时过大时,尝试强制使用你定的执行顺序。option(force order)
11、看到有多个线程来合并执行你的sql语句而影响到性能时,尝试强制是不并行操作。option(maxdop 1)
12、在存储过程中,由于参数不同导致执行计划不同,也影响啦性能时尝试指定参数来优化。option(optiomize for(@name='zlh'))
13、不操作多余的列,多余的行,不做务必要的聚合,排序。
小结
已经到晚间2点半啦,查询优化没有做过于详细的分解,见谅,如果你在看到本文后有什么疑问,欢迎加入博客左上角群,一起交流学习,安。