1 背景知识
电力设备在线监测指在不停电的情况下,对电力设备状况进行连续或周期性地自动监视检测,使用的技术包括:传感器技术、广域通信技术和信息处理技术。电力设备在线监测是实现电力设备状态运行检修管理、提升生产运行管理精益化水平的重要手段,对提升电网智能化水平、实现电力设备状态运行管理具有积极而深远的意义。
随着智能电网建设的推进,电力设备在线监测得到了较大发展并成为趋势,监测数据变得日益庞大,逐渐构成电力设备监测大数据,这给电力设备在线监测系统在数据存储和处理方面带来非常大的技术挑战。
电力设备监测大数据具有体量大、类型多、价值密度低和处理速度快的特点。电网公司监测系统目前过于依赖集中式SAN存储,并基于SOA进行数据集成,主要采用“企业级关系型数据库”,受容量、扩展性以及访问速度的制约,目前只存储二次加工的“熟数据”,而所擅长的关联查询、事务处理在数据分析时又无用武之地,迫切需要新的大数据存储和处理技术来应对。
变压器的局部放电数据是一种典型的电力设备监测数据。局部放电相位分析(phase resolved partial discharge, PRPD)包含了从特征提取到模式识别的过程。本文将全面介绍利用MaxCompute实现局部放电监测数据特征提取的过程。
PD信号分析主要包括三个子过程:(1)基本参数n-q-φ的提取。扫描PD信号,统计信号中的放电峰值和相应的放电相位。(2)谱图构造和统计特征计算。划分相窗,统计平均放电量和放电次数的分布,计算平均放电量相位分布谱图qave-φ和放电次数相位分布谱图n-φ。基于qave-φ和n-φ,以φi为随机变量,计算谱图的偏斜度Sk、陡峭度Ku等统计特征,形成放电特征向量。(3)放电类型识别。本文将介绍,使用MapReduce实现第一个子过程的方法。
MaxCompute(原ODPS) 是阿里云提供的海量数据处理平台。主要服务于批量结构化数据的存储和计算,数据规模达EB级别。MaxCompute目前已在大型互联网企业的数据仓库和BI分析、网站的日志分析、电子商务网站的交易分析等领域得到大规模应用。
另外,本文还将使用odpscmd作为客户端完成对MaxCompute的各种操作。odpscmd是一个Java程序,可以以命令方式访问MaxCompute。应用该客户端,可以完成包括数据查询、数据上传、下载等各种任务。需要JRE环境才能运行,请下载并安装JRE 1.6+版本。
本文将使用MapReduce编程来完成特征分析的计算任务。MapReduce最早是由Google提出的分布式数据处理模型,随后受到了业内的广泛关注,并被大量应用到各种商业场景中。比如搜索、Web访问日志分析、文本统计分析、海量数据挖掘、机器学习、自然语言处理、广告推荐等。
2 分析过程
2.1 创建项目、建表和数据上传
(1)创建MaxCompute项目
打开阿里云官网:https://www.aliyun.com/
使用已有阿里云账号登录。
进入阿里云管理控制台,并从左侧导航栏选择“大数据(数加)à大数据计算服务”,进入MaxCompute管理控制台,创建一个MaxCompute项目。
(2)安装配置odpscmd
在本地准备好JRE环境,请下载并安装JRE 1.6+版本。
从阿里云官网下载odpscmd工具:http://repo.aliyun.com/download/odpscmd/latest/odpscmd_public.zip?spm=5176.doc27804.2.3.o2o8Rw&file=odpscmd_public.zip
解压缩,并配置<ODPS_CLIENT>/conf/odps_config.ini
project_name=[project_name]
access_id=******************
access_key=*********************
end_point=http://service.odps.aliyun.com/api
tunnel_endpoint=http://dt.odps.aliyun.com
log_view_host=http://logview.odps.aliyun.comhttps_check=true
配置完成后,运行<ODPS_CLIENT>/bin/odpscmd,进入交互模式。会出现项目名称作为提示符。
(3)建表并添加分区
1)Â Â 创建ODS_PD表,用于存放原始的变压器局部放电监测数据。
在odpscmd中,执行下面的SQL语句,建表,并添加分区。
create table if not exists ODS_PD(
Time string,
Phase bigint,
Value bigint)
partitioned by (DeviceID string, Date string);2) 创建目标特征表DW_NQF
在odpscmd中,执行下面的SQL语句,建表,并添加分区。
create table if not exists DW_NQF(
Time string,
Phase bigint,
MaxV bigint)
partitioned by (DeviceID string, Date string);(4)使用Tunnel进行数据上传
在odpscmd中运行tunnel命令,将本地数据文件monitor_data.csv上传至ODS_PD表。下面的命令中的路径,请在执行时根据实际路径进行修改。monitor_data.csv请从附件中下载。
2.2 MapReduce程序开发、本地调试和运行
(1)本地开发环境准备
本文使用Eclipse作为开发环境,请提前下载并安装。
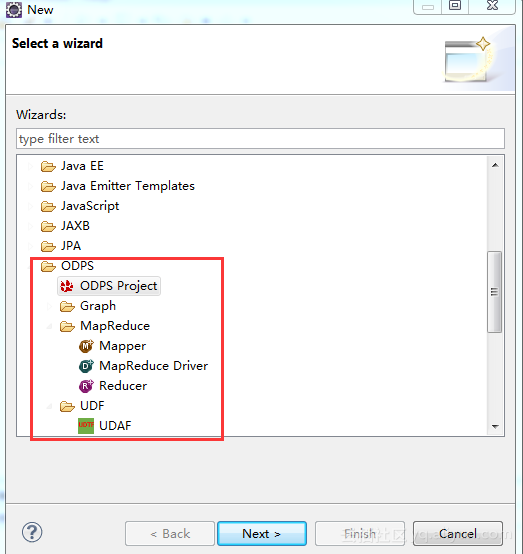
官网导航中找到并下载 ODPS for eclipse 插件,并将插件解压并复制到Eclipse安装目录下的plugins子目录下。启动Eclipse,检查Wizard选项里面是否有ODPS的目录。
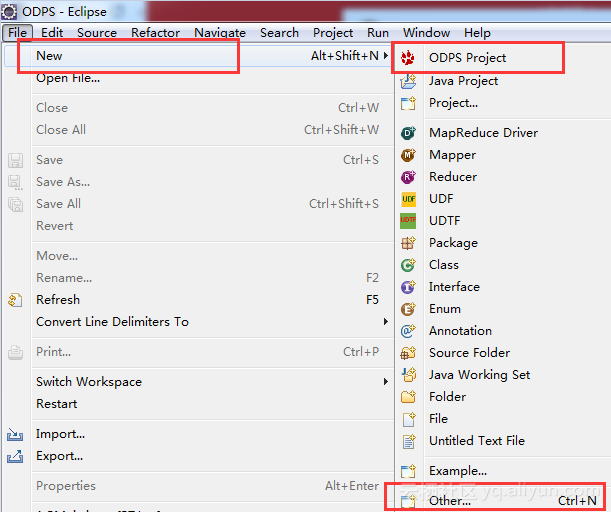
ODPS for eclipse 插件下载地址:
https://docs-aliyun.cn-hangzhou.oss.aliyun-inc.com/cn/odps/0.0.90/assets/download/odps-eclipse-plugin-bundle-0.16.0.zip?spm=5176.doc27981.2.3.cCapmQ&file=odps-eclipse-plugin-bundle-0.16.0.zip
当可以创建ODPS类型的项目时,表示本地开发环境已经准备好了。
(2)MapReduce程序开发
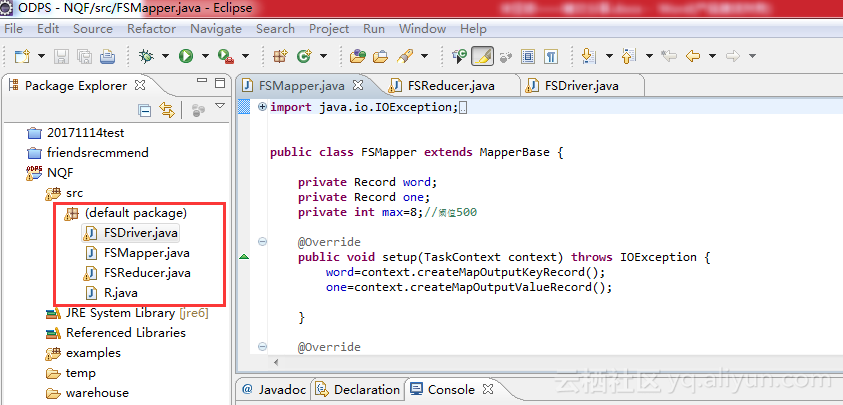
在Eclipse中创建ODPS项目,命名为NQF。为了让Eclipse能正确访问MaxCompute,需要在创建项目的时候正确配置odpscmd的本地路径。
依次添加Mapper类、Reducer类、MapReduce Driver类和R类。
(3)本地测试
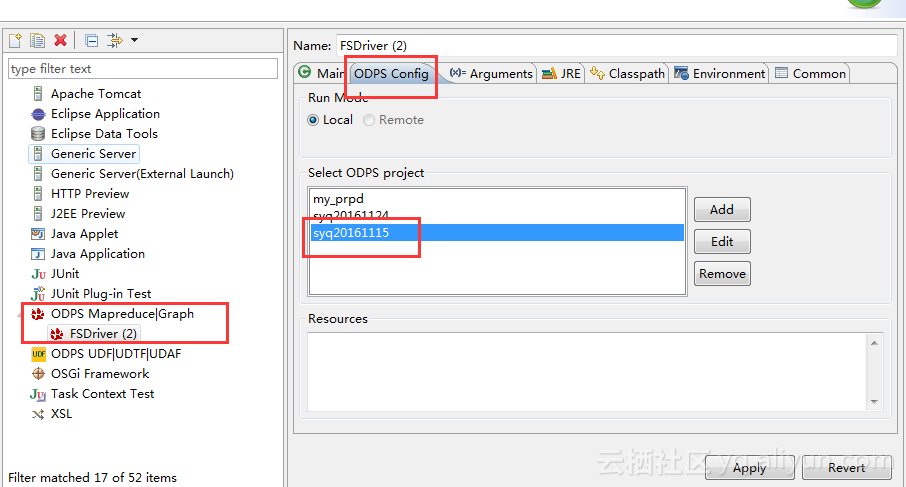
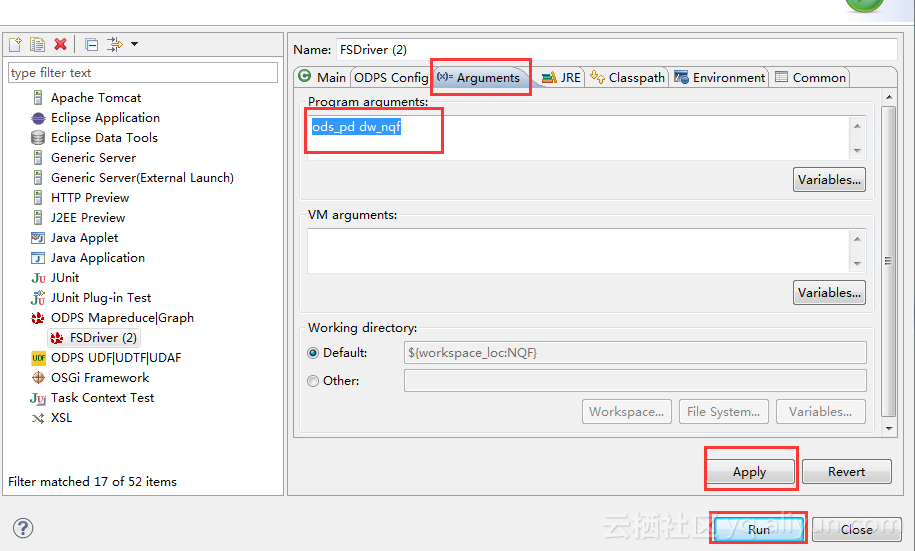
打开FSDriver.java,右击“Run as-àRun Configurations”

在ODPS Config选项卡,选择正确的ODPS项目。
在Arguments选项卡中,输入运行参数:ods_pd dw_nqf,并点击“Run”,执行本地测试运行。
在第一次运行时,Eclipse会从MaxCompute中下载少量的测试数据用于测试。运行完成后,可以在Warehouse中看到测试用的输入数据和产生的结果数据。
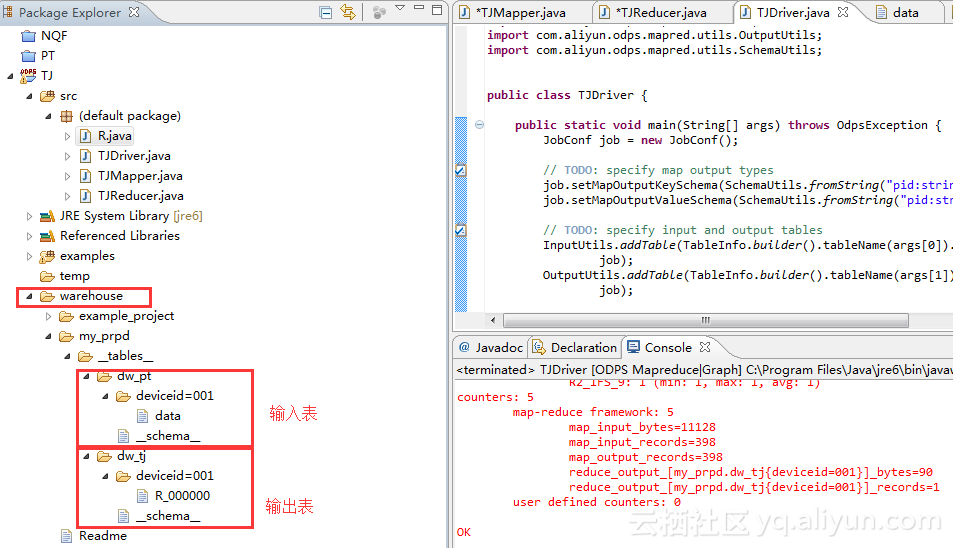
(4)打包并上传资源
在本地测试结果正确之后,就可以导出jar包了。在Eclipse下执行“FileàExport”,选择导出“JAR File”,导出至本地。
在odpscmd下,执行添加资源的命令,将jar上传至MaxCompute。
add jar d:/jar/NQF.jar;

(5)MaxCompute上执行程序
在odpscmd下,执行jar命令,运行程序。(请自行调整文件路径)
jar -resources NQF.jar -classpath d:\jar\NQF.jar FSDriver ods_pd dw_nqf;
实验的完整流程和代码详见阿里云Clouder认证课程:https://edu.aliyun.com/course/623?spm=5176.10731491.0.0.YnkJLj

