编者:今年的INTERSPEECH于8月20日至24日在瑞典的斯德哥尔摩顺利召开,众多的高校研究机构和著名的公司纷纷在本次会议上介绍了各自最新的技术、系统和相关产品,而阿里巴巴集团作为钻石赞助商也派出了强大的阵容前往现场。从10月25日开始,阿里iDST语音团队和云栖社区将共同打造一系列语音技术分享会,旨在为大家分享INTERSPEECH2017会议上语音技术各个方面的进展。本期分享的主题是语音合成技术,以下是本次分享的主要内容:
1.语音合成技术简介
1.1 什么是语音合成?
语音合成技术是将任意文本转换成语音的技术。是人与计算机语音交互必不可少的模块。如果说语音识别技术是让计算机学会“听”人的话,将输入的语音信号转换成文字,那么语音合成技术就是让计算机程序把我们输入的文字“说”出来,将任意输入的文本转换成语音输出。

1.2 语音合成的应用场景和研究范围
语音合成技术是人与计算机语音交互中必不可少的模块。从地图导航(例如高德地图高晓松语音导航),语音助手(Apple Siri, Google Assistant,微软 Cortana, Nuance Nina), 小说、新闻朗读(书旗、百度小说), 智能音箱(Amazon Alexa, 天猫精灵, Google Home,Apple Pod Home 等 ),语音实时翻译,到各种大大小小的客服,呼叫中心,甚至机场广播,地铁公交车报站都少不了语音合成技术的身影。
而且不仅仅是文字转语音,语音合成技术研究范围还包括且不限于:说话人转换(看过007么), 语音频带拓展, 歌唱语音合成(例如:日本很火的初音未来),耳语语音合成(whisper), 方言合成(四川话,粤语, 甚至古代汉语发音),动物叫声合成,等等等等。
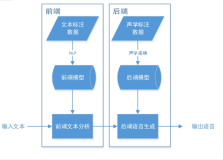
1.3 一个典型的语音合成系统流程图
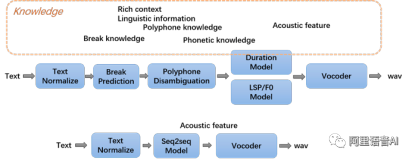
如下图所示,一个典型的语音合成系统主要包括前端和后端两个部分。前端部分主要是对输入文本的分析,从输入的文本提取后端建模需要的信息。例如:分词(判断句子中的单词边界),词性标注(名词,动词,形容词等),韵律结构预测(是否韵律短语边界),多音字消岐等等。后端的部分读入前端文本分析结果,并且对语音部分结合文本信息进行建模。在合成过程中,后端会利用输入的文本信息和训练好的声学模型,生成出语音信号,进行输出。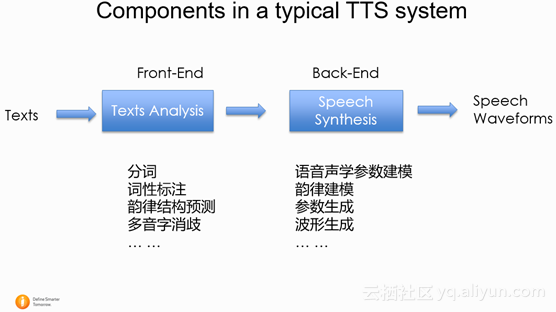
1.4 语音产生的过程
一个人发声的过程可以看成肺部气流通过人的声带,并经过口腔形状调制,最后从嘴唇发出的过程。当人发轻声时,肺部气流通过声带时,声带不会振动,因此我们可以将通过的气流用白噪声信号来表示。相对的,当人发元音或者浊辅音时,当气流通过声带时,声带会有节奏地振动,这时,我们将通过的气流用冲激串表示。同时,我们把声带振动的频率叫做基频(f0)。人的音色和具体发什么音是和发音时的口腔形状相关。因此我们可以将人发生的过程简单的看成一个激励信号(气流)通过滤波器(口腔形状)调制,最后通过嘴唇发射出去的过程。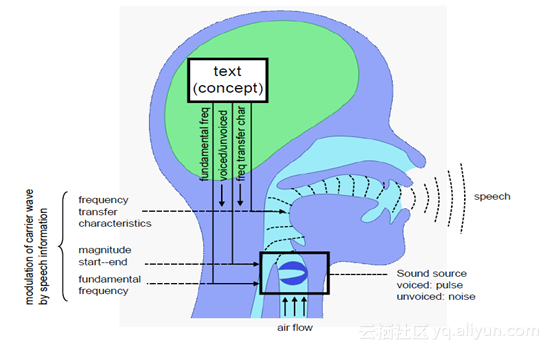
1.5 三种现阶段主要的语音合成系统
现阶段的语音合成系统,根据所采用的方法和框架不同,主要可以分为三种: A. 参数语音合成系统。B. 拼接语音合成系统。C. 基于波形的统计合成系统(WaveNet) 。其中A, B 是现阶段各大公司线上主流的合成系统,C WaveNet 的方法还在研究阶段,是现阶段研究的热门。
A. 参数语音合成系统的特点是,在语音分析阶段,需要根据语音生成的特点,将语音波形(speech waves) 通过声码器转换成频谱,基频,时长等语音或者韵律参数。在建模阶段对语音参数进行建模。并且在语音合成阶段,通过声码器从预测出来的语音参数还原出时域语音信号。参数语音合成系统的优势在于模型大小较小,模型参数调整方便(说话人转换,升降掉),而且合成语音比较稳定。缺点在于合成语音音质由于经过参数化,所以和原始录音相比有一定的损失。
B. 拼接语音合成系统的特点是,不会对原始录音进行参数化,而会将原始录音剪切成一个一个基本单元存储下来。在合成过程中,通过一些算法或者模型计算每个单元的目标代价和连接代价,最后通过Viterbi算法并且通过PSOLA(Pitch Synchronized Overlap-Add)或者WSOLA(Waveform Similarity based Overlap-Add)等信号处理的方法“拼接”出合成语音。因此,拼接语音合成的优势在于,音质好,不受语音单元参数化的音质损失。但是在数据库小的情况下,由于有时挑选不到合适的语音单元,导致合成语音会有Glitch 或者韵律、发音不够稳定。而且需要的存储空间大。
C. WaveNet 波形统计语音合成是Deep Mind 首先提出的一种结构,主要的单元是 Dilated CNN (卷积神经网络)。这种方法的特点是不会对语音信号进行参数化,而是用神经网络直接在时域预测合成语音波形的每一个采样点。优势是音质比参数合成系统好,略差于拼接合成。但是较拼接合成系统更稳定。缺点在于,由于需要预测每一个采样点,需要很大的运算量,合成时间慢。WaveNet 证明了语音信号可以在时域上进行预测,这一点以前没有方法做到。现阶段WaveNet是一个研究热点。
1.6 合成语音的评价标准
声音的好听与难听是一个相对主观的概念,因此合成语音的好坏主要通过找很多测听人员对合成语音进行打MOS(Mean Opinion Score)分,其中MOS的范围是 1-5 分,分别代表 1: Bad, 2: Poor, 3: Fair, 4: Good, 5: Excellent 。MOS打分可以对合成语音的音质,可懂度,相似度,或者其他的分项进行评价,也可以对语音的整体自然度进行评价。
2. INTERSPEECH 2017 语音合成论文介绍
下面介绍一些INTERSPEEECH 2017 语音合成方面的论文。本次INTERSPEECH会议WaveNet是很火的一个题目,专门有一个部分是讲WaveNet的各种应用。另外,本次会议里,各大公司也发表了介绍自己线上语音合成系统的文章,特别是苹果的Siri, 这也是Siri第一次发表介绍系统结构的论文。
2.1 WaveNet and Novel Paradigms
这个 Section都是以WaveNet为结构来做一些事情。主要介绍一下几篇论文。
2.1.1 PAPER Tue-O-4-1-1 — Speaker-Dependent WaveNet Vocoder
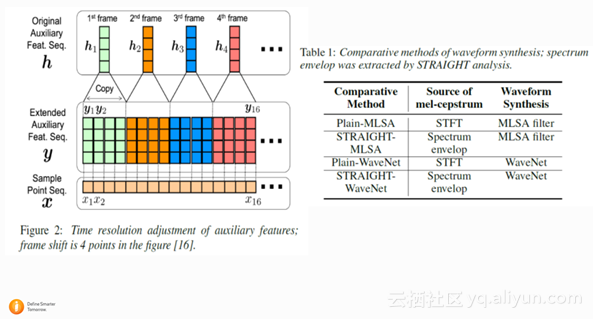
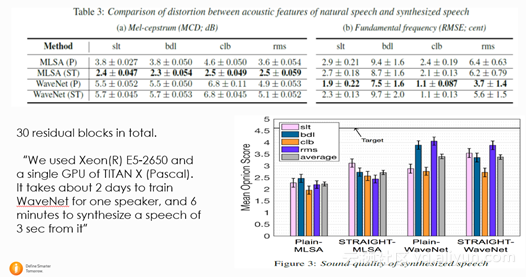
这篇文章是日本名古屋大学的文章,主要是用WaveNet来做声码器,不同于基本的WaveNet,这篇文章不再condition on 每一帧的 linguistic feature, 而是condition on acoustic feature(声学参数,比如频谱参数 ,基频参数)。通过给定每一帧的acoustic feature,通过WaveNet, 而不是传统的声码器,就能得到合成语音。实验证明了,对于不同的说话人集合,WaveNet声码器都好于传统的 MLSA (Mel-Log S)声码器。
但作者也提到训练和WaveNet预测的过程非常慢,用单GPU TITAN X, 对每一个说话人训练需要2天时间,并且合成仅仅2秒钟的语音需要6分钟的时间。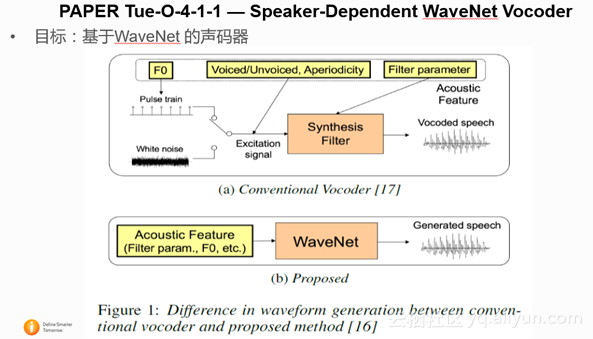
2.1.2 PAPER Tue-O-4-1-2 — Waveform Modeling Using Stacked Dilated Convolutional Neural Networks for Speech Bandwidth Extension
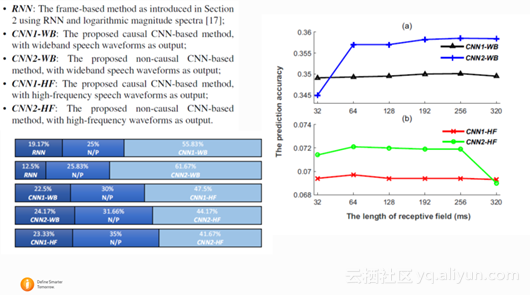
这篇文章是中科大讯飞实验室发表的文章,文章的目标是用WaveNet的结构,从窄带语音信号预测出相应的宽带语音信号。和基础的WaveNet相比,文章将auto-regressive的生成方式换成了直接mapping 的方式,同时尝试了用non-casual CNN 和 casual CNN作比较。结论是用non-casual CNN先只预测高频信号,然后再跟原始低频信号相加生成宽带信号能得到最好的结果。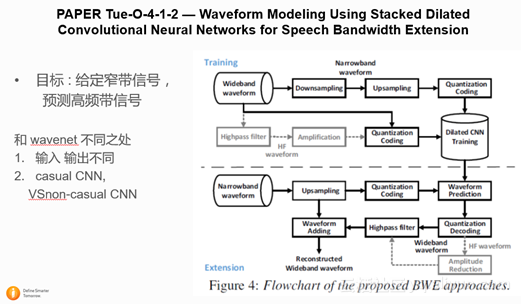
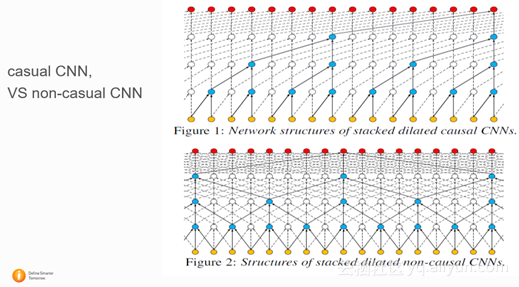
2.1.3 PAPER Tue-O-4-1-5 — Statistical Voice Conversion with WaveNet-Based Waveform Generation
这篇文章也是名古屋大学的文章,文章用WaveNet的结构实现说话人语音转换(Voice Conversion),结论是好于传统的GMM说话人转换的方法。这篇文章其实也是将WaveNet作为一个声码器,在合成的时候,将转换以后的语音参数作为condition生成speech wave。下图是基于WaveNet语音转换的结构框图。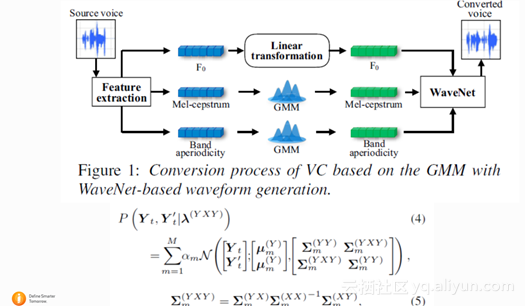
2.2 公司发表的介绍自己合成系统的文章
2.2.1 Apple : Siri On-Device Deep Learning-Guided Unit Selection Text-to-Speech System
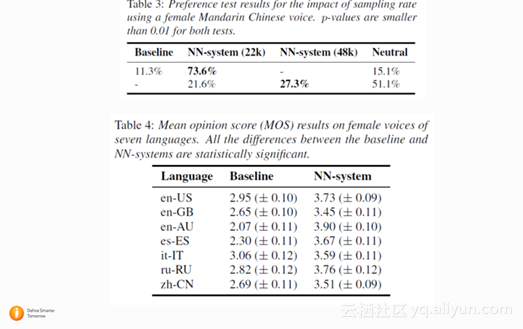
这是 Siri 系统第一次发文章,主要介绍了apple最近 TTS 方面的 deep learning 方面的进展, TTS 的性能提升。从实验结果来看,在各种不同的语种上,基于Mix density network (MDN)的拼接语音合成系统明显优于之前的传统的Siri拼接合成系统。以下是具体结果。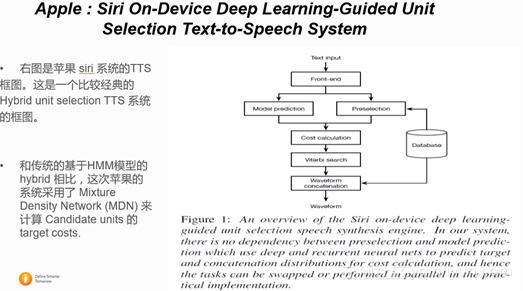
2.2.2 Google’s Next-Generation Real-Time Unit-Selection Synthesizer using Sequence-To-Sequence LSTM-based Autoencoders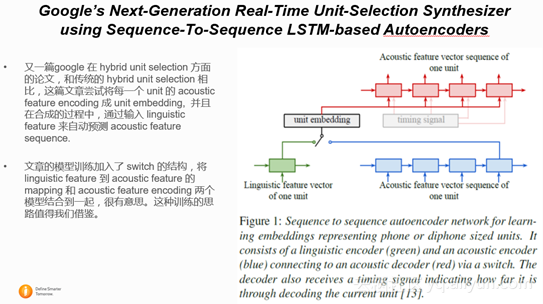
2.2.3 Nuance : Unit selection with Hierarchical Cascaded Long Short Term Memory Bidirectional Recurrent Neural Nets
Nuance 公司也发表了介绍自己合成系统的文章。是一个基于Hierarchical LSTM 的拼接合成系统。结果证明Hierarchical LSTM结构在合成语音韵律上好于非Hierarchical LSTM。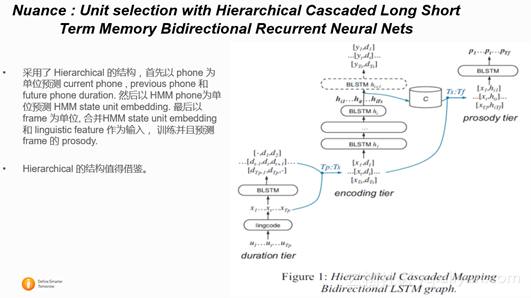
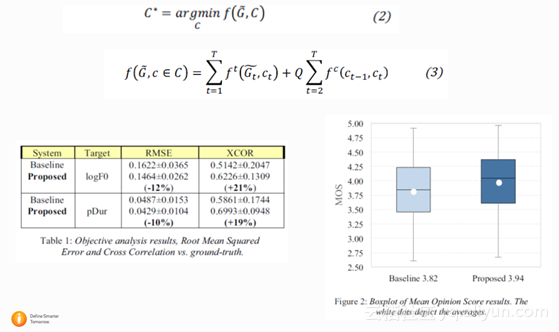
2.2.4 Google : Tacotron: Towards End-to-End Speech Synthesis
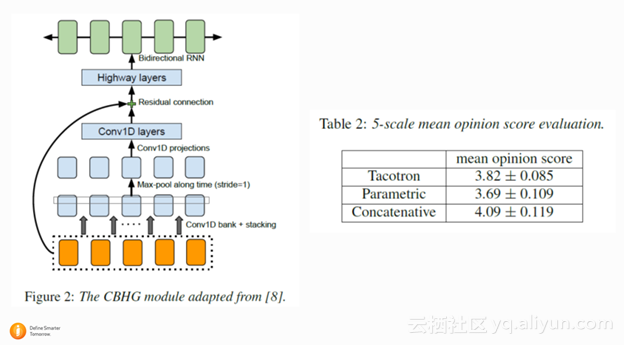
这篇 google 的文章早前在 arxiv 上放出,和 WaveNet 相比 Tacotron 系统是以 frame 而不是每一个 sample 点为单位进行模型训练和预测,所以速度上会更快。Tacotron 是在 Spectrogram 上建模,不像 WaveNet 是在波形上建模。所以和 WaveNet 相比, Tacotron 还是损失了frame 相位的信息。最后Tacotron 通过 Griffin-Lim 算法直接从 Spectrogram 还原出wave。 在 acoustic model 上面, Tacotron 用了 pre-net 对每一个字的 embedding 进行了进一步的非线性编码, 并且通过 CBHG 结构来增加模型的鲁棒性。在建模过程中,作者使用了 Attention 的机制来控制每一帧的 condition。 模型也是通过 feed in 上一帧的输出来得到当前帧的输入。总的来说,这是一篇非常值得借鉴的文章。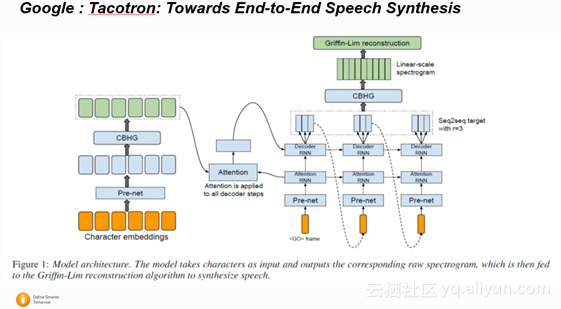
2.3一些其他的论文

PS
下期主题:语音识别技术之远场语音识别
时间:11月22日晚7:30
嘉宾:阿里巴巴iDST算法专家,坤承
报名链接:https://yq.aliyun.com/webinar/play/338