概述
最近这段时间在强化日志系统自身的稳定性和可靠性,一个稳定可靠的系统离不开监控,我们这里谈及的监控除了服务是否存活还有这些组件的核心metrics采集与抓取,为此我们将这些任务做成了定时任务来执行。由于大致的思路以及设计已经成型,所以今天来分享一下日志系统在定时任务这块的选型与设计。
组件运行时监控
从我之前分享的文章中不难看出我们日志系统的各个组件的选型:
- 采集agent : Flume-NG
- 消息系统 : Kafka
- 实时流处理 : Storm
- 分布式搜索/日志存储(暂时) : Elasticsearch
这也是很多互联网日志解决方案的通用选型。但是,我们在调研这些组件自身提供的监控方案以及他们支持的第三方监控工具时,却得到了不一致的结果:
- Flume-NG : 支持http/JMX metrics,支持的监控工具:Ganglia
- Kafka : 支持jmx metrics,支持的监控工具:Yahoo!
- Storm : 支持jmx metrics,自带Storm UI
- Elasticsearch : 支持http形式的status请求
从上面的结果来看,自身具备的监控能力以及跟第三方的监控系统的集成能力参差不齐。这显然不符合我们的期望,我们的几个关注点:
- 监控统一化,或者说去异构化
- 随着系统稳定后,能够自由配置我们认为非常重要、必须care的metrics
- 统一的可视化,我们期望能在我们自身的管控台上一目了然地看到我们希望看到的metrics
总结一下,如上的这些组件在被监控能力上虽然各有差异,不过还是有一些共同点,那就是对于:
- JMX
- http
这两种协议的metrics请求,各个组件都至少支持其中的一个。
其实,监控统一化这一点不难做到,我们可以选择当前主流的开源监控工具Zabbix(对于JMX的metrics获取,Zabbix自身已经提供了原生支持:Java Gateway)。但是对于个性化的监控,比如特定metrics的提取与展示,需要对Zabbix进行定制。出于各种原因,我们暂时没有采用基于Zabbix的定制方案。
JMX metrics收集
因为Zabbix 提供了JMX收集的原生支持,而且它自身又是开源软件,所以我们的JMX metrics收集是基于Zabbix Java Gateway进行定制的。
简单了解一下Zabbix Java Gateway,Zabbix是在2.0之后对JMX提供了原生支持。它的架构非常简单,如下图所示:

工作原理:
Zabbix server想知道一台主机上的特定的JMX值时,它向Zabbix Java gateway询问,而Zabbix Java gateway使用“JMXmanagementAPI”去查询特定的应用程序,而前提是应用程序这端在开启时需要-Dcom.sun.management.jmxremote参数来开启JMX查询就行了。
Zabbix server有一个特殊的进程用来连接Javagateway叫StartJavaPollers.Java gateway是一个独立运行的java daemon程序,类似于一个proxy来解耦Zabbix和那些提供JMX metrics的component。
我们主要利用了java gateway获取JMX的代码(JMXItemChecker.java类),然后将获取到的metrics转存到我们的数据库里,以供在日志系统的管控台进行展示。因为我们没有采用整套机制,所以无关的细节就不再多谈。
http metrics收集
http metrics主要用来对ElasticSearch进行监控(因为它不支持JMX),我们使用HttpClient来发送请求,然后同样将获取到的信息存储到我们的数据库里。
定时任务框架的选型——quartz
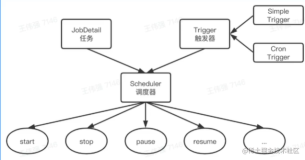
quartz是一个开源的、功能强大的主流定时任务执行框架。我们简单提一下它的几个核心概念:
- Job : 定义一个任务的具体处理逻辑
- JobDetail : 封装了Quartz框架在执行一个job时需要的必要信息
- Trigger : job执行的触发器
- JobDataMap : 封装了Job执行过程中需要的数据
当然quartz框架还有很多其他概念,但就这篇文章而言,这里我们只谈上面这些就够了。
定时任务执行引擎的整体设计
上面谈到了我们选择的开源定时任务框架quatrz,单有一个框架还不够,我们还需要对任务进行规划、分类以及如何去管理、分发这些任务进行设计。
定时任务种类
我们暂且将定时任务分为两种:
- 简单的离线计算:offlineCalc
- metrics收集:metricsPoller
- 日志系统其他的一些日常维护任务:比如日常索引的管理等
这里,对于metrics的收集是我们引入定时任务的主要需求,因此我们将以它为主线来介绍我们的定时任务执行引擎。
元数据存储与设计
基于上面介绍的quartz的几个概念,以及我们需要达到的通用化任务执行的目的,我们需要思考如何来让这个定时任务执行引擎变动更自动化,提高它的扩展性,这就牵扯到定时任务执行需要的元数据管理。
我们设计了一个层次化的组织结构,他们从上到下依次是:
- job category
- job type
- job
- job metadata
- job trigger
category对job进行广义上的划分,比如我们上面提到的offlineCalc,metricsPoller等。在Quartz里,Job有分组(group)的概念,我们也以此作为job分组的依据。
type定义了任务的类型,它归属于category。type不只起到组织job的作用,某种程度上它应对着一个job class,也就是某一组遵循相同处理逻辑的job的归类。比如,我们上面提到的,针对JMX 以及 http metrics的poller。
job对应于quartz中的Job,这里需要权衡好它的粒度。拿JMX metrics poller这种类型的job举例,如果只需要抓取某个component的metrics,那么一个job的粒度就可以是对一个metrics的一次获取。但如果你需要对多个component的很多metrics进行提取,那么你job的粒度就不能这么细,可能你一个job必须要负责一个component中的所有metrics的提取。这取决于你的任务量,以及合理控制一个定时任务框架中的job数。
job metadata存储job在运行时必须的元数据。上面提到job是一类相同业务逻辑的一个抽象执行单元。但他们并非完全一样,不一样的地方就区别在他们的执行时需要的元数据。job跟metadata的对应关系是一对多的关系。比如我们上面提到的JMX metrics poller,它存储了一个job需要提取的metrics的object attribute的集合。
job trigger对应于quartz中的Trigger。job跟trigger的对应关系是一对一。
上面的这些数据都提供了在管控台进行配置管理的功能。
生命周期自动化管理
为了提升定时任务执行引擎的可扩展性以及自管理性。我们选择用Zookeeper来存储如上的整个job的拓扑以及元数据信息。

Zookeeper除了是很好的元数据管理工具,还是很主流的分布式协同工具。它的Event机制,使得我们对Job生命周期的自动化管理成为可能。我们通过对各个ZNode的children ZNode进行监听,来动态感知Job的变化,感知到节点的变化之后,我们就可以动态创建或者删除某个job。
总结
本篇内容我们以对日志系统的各个component的metrics的监控为切实需求,谈论了我们在主流的定时任务执行框架quartz上进行的任务设计使得它更具扩展性,同时将其跟Zookeeper结合使得任务的管理具备自动化的能力。
原文发布时间为:2016-04-23
本文作者:vinoYang
本文来自云栖社区合作伙伴CSDN博客,了解相关信息可以关注CSDN博客。