
这并不意味着迁移到公共云服务是一个错误。公共云服务在敏捷性、响应性、简化操作和提高创新方面提供了巨大的优势。 这方面的错误在于:假设在不实施管理和自动化的情况下迁移到公共云服务,也能带来成本的节约。为了应对不断上涨的云基础设施成本,我们建议您企业组织不妨参考和借鉴本文中所介绍的这些最佳实践方案,以减低和优化成本,并实现您企业环境的价值最大化。

优化控制计算成本
1、通过计费提醒估算计算成本
1.1 使用DataWorks 估算费用
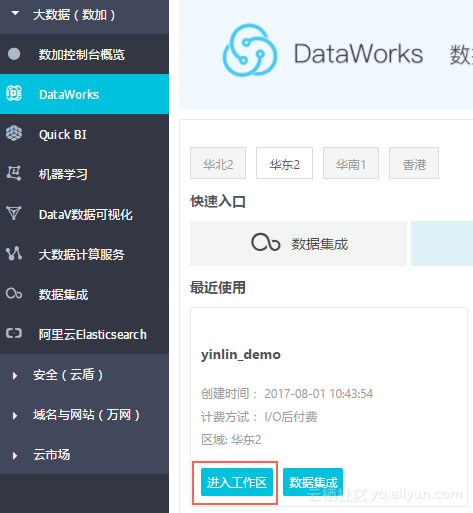
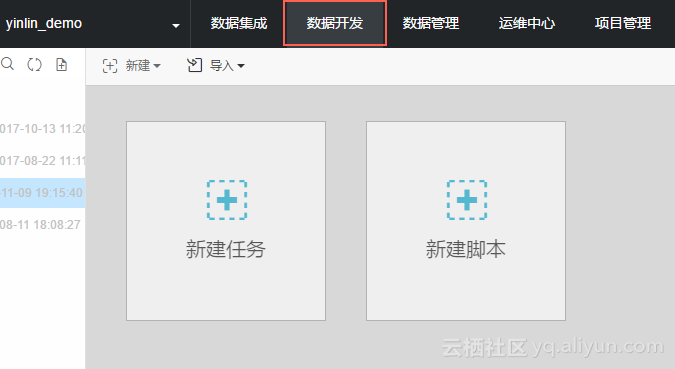
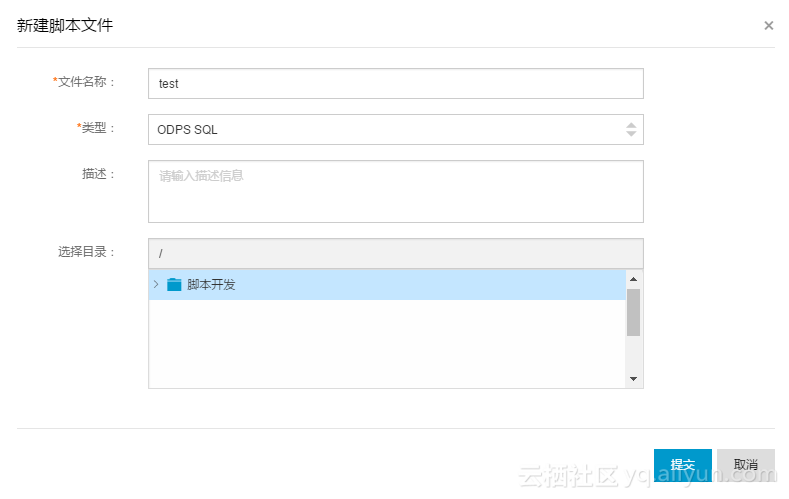
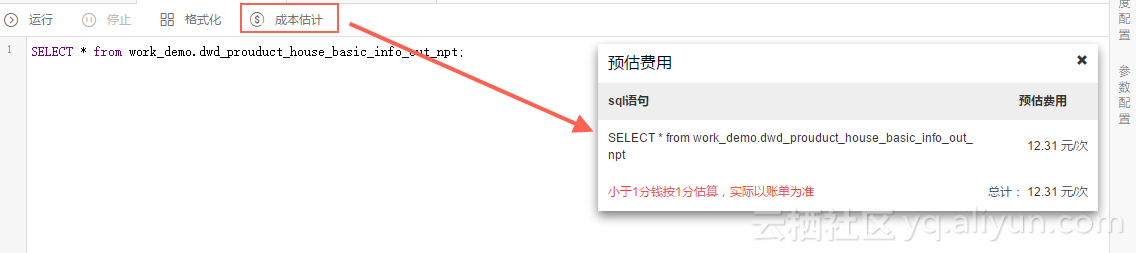
1.2 使用Cost SQL估算费用
Cost SQL SELECT * from work_demo.dwd_prouduct_house_basic_info_out_npt;1.3 使用MaxCompute Stuido估算费用
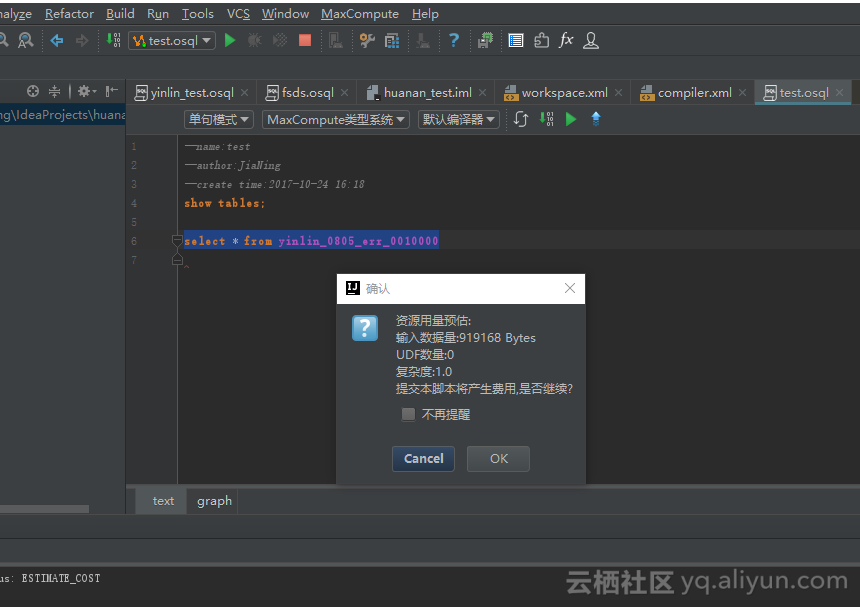
1.4 使用产品价格计算器估算费用
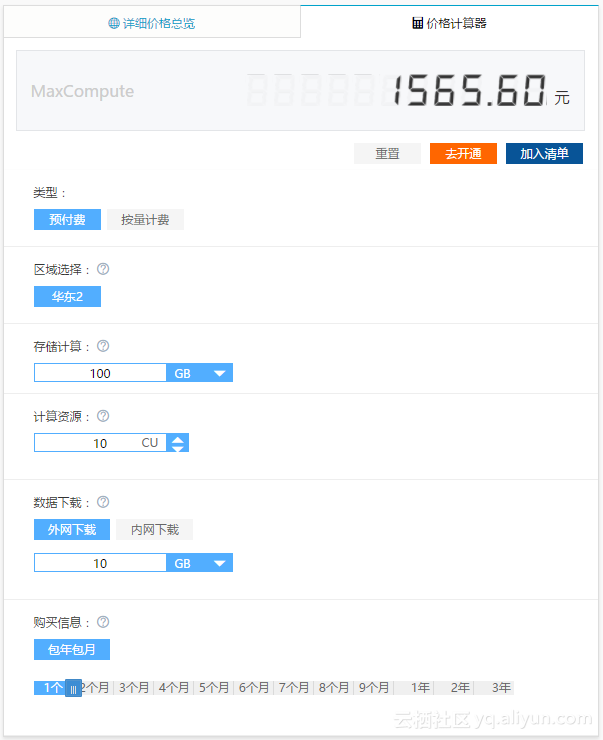
1.5 使用MaxCompute JAVA SDK估算费用
工程示例:
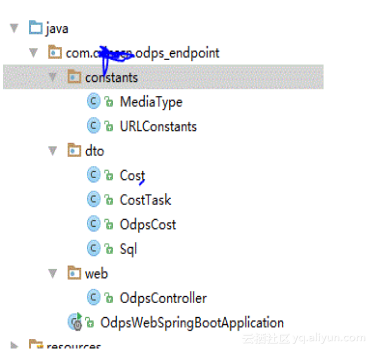
其中最核心的API调用如下,SqlCostTask 这个函数就能获取(计算输入数据量 * SQL复杂度 * SQL价格)这三个变量了,文档参考:http://repo.aliyun.com/java-sdk-doc/com/aliyun/odps/task/SQLCostTask.html
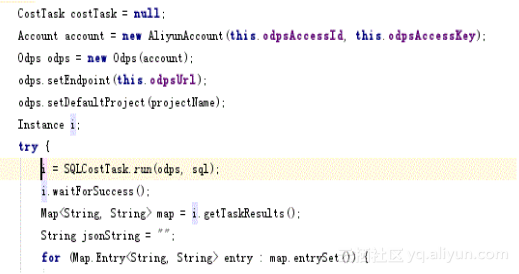
估算界面:
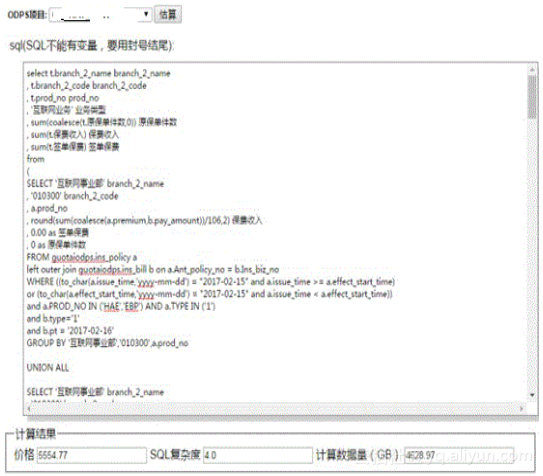
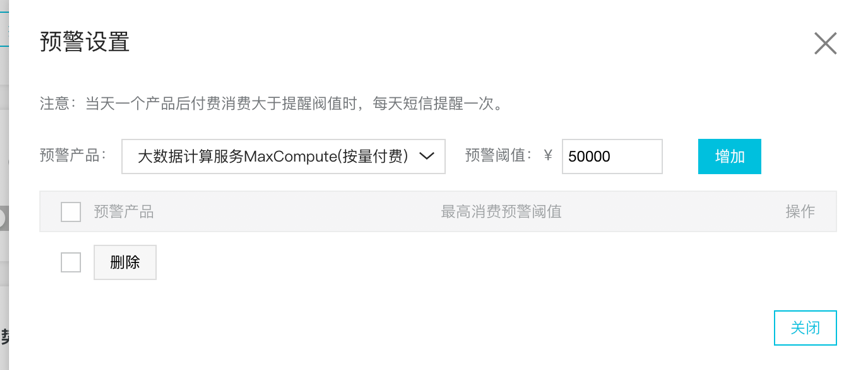
2、通过账单预警控制计算成本
使用阿里云账单中心配置高额预警,当天产品后付费消费大于提醒阀值时,每天早上9点左右短信提醒一次。
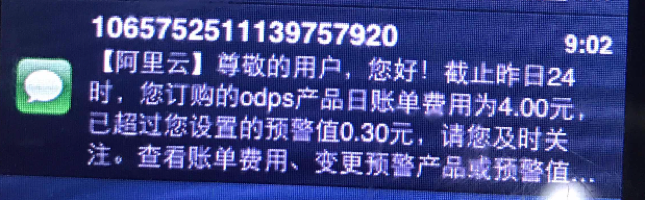
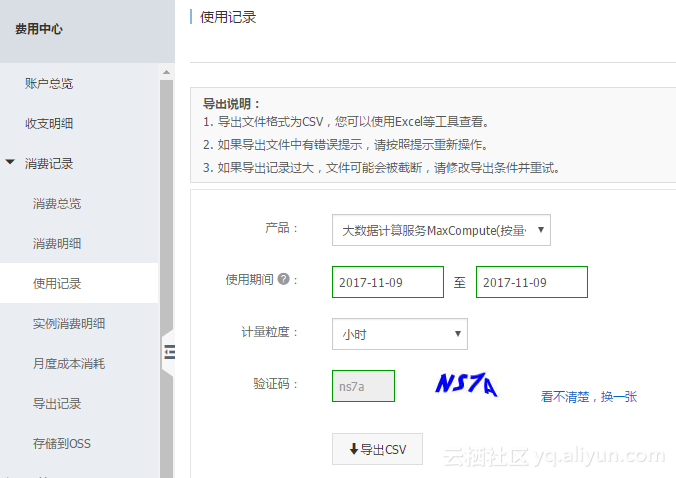
第一步,进入账单中心https://usercenter2.aliyun.com,点击按钮开启高额预警;
第二步,选择MaxCompute产品(目前仅支持后付费);
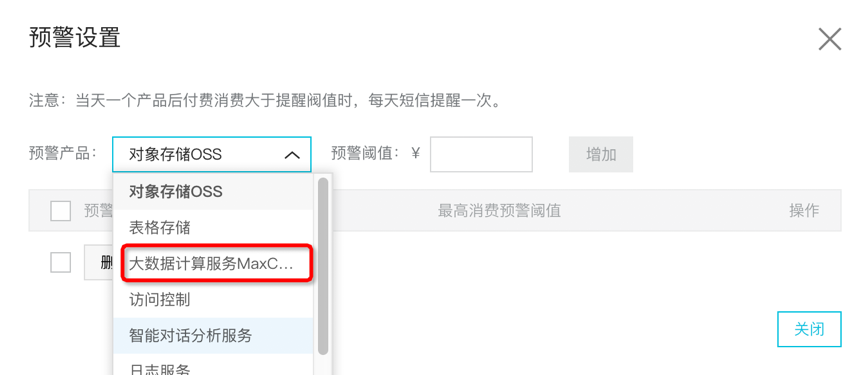
第三步,填写预警阀值,输入按“天”消费上限;
3、通过优化SQL来控制计算成本
3.1 列裁剪
SELECT a,b FROM T WHERE e < 10;3.2 分区裁剪
SELECT a,b FROM T WHERE partitiondate='2017-10-01';3.3 SQL关键字的优化
例如------------------------------------
SELECT COALESCE(t1.id, t2.id) AS id, SUM(t1.col1) AS col1
, SUM(t2.col2) AS col2
FROM (
SELECT id, col1
FROM table1
) t1
FULL OUTER JOIN (
SELECT id, col2
FROM table2
) t2
ON t1.id = t2.id
GROUP BY COALESCE(t1.id, t2.id);
可以优化为---------------------------
SELECT t.id, SUM(t.col1) AS col1, SUM(t.col2) AS col2
FROM (
SELECT id, col1, 0 AS col2
FROM table1
UNION ALL
SELECT id, 0 AS col1, col2
FROM table2
) t
GROUP BY t.id;在union all内部尽可能不使用group by,改为在外层统一group by;
例如--------------------------------------
SELECT t.id, SUM(t.val) AS val
FROM (
SELECT id, SUM(col3) AS val
FROM table3
GROUP BY id
UNION ALL
SELECT id, SUM(col4) AS val
FROM table4
GROUP BY id
) t
GROUP BY t.id;
可以优化为---------------------------
SELECT t.id, SUM(t.val) AS val
FROM (
SELECT id, col3 AS val
FROM table3
UNION ALL
SELECT id, col4 AS val
FROM table4
) t
GROUP BY t.id;例如--------------------------------------
SELECT COUNT(DISTINCT id) AS cnt
FROM table1;
可以优化为---------------------------
SELECT COUNT(1) AS cnt
FROM (
SELECT id
FROM table1
GROUP BY id
) t;3.4 禁止全表扫描
set odps.sql.allow.fullscan=false;
select count(*) from work_demo.house_test; 说明:限制扫描全表。默认情况下true,允许扫描全表;否则为false,如果扫描全表,则抛异常。
Project级别控制
SetProject odps.sql.allow.fullscan详细参考: https://help.aliyun.com/document_detail/27834.html
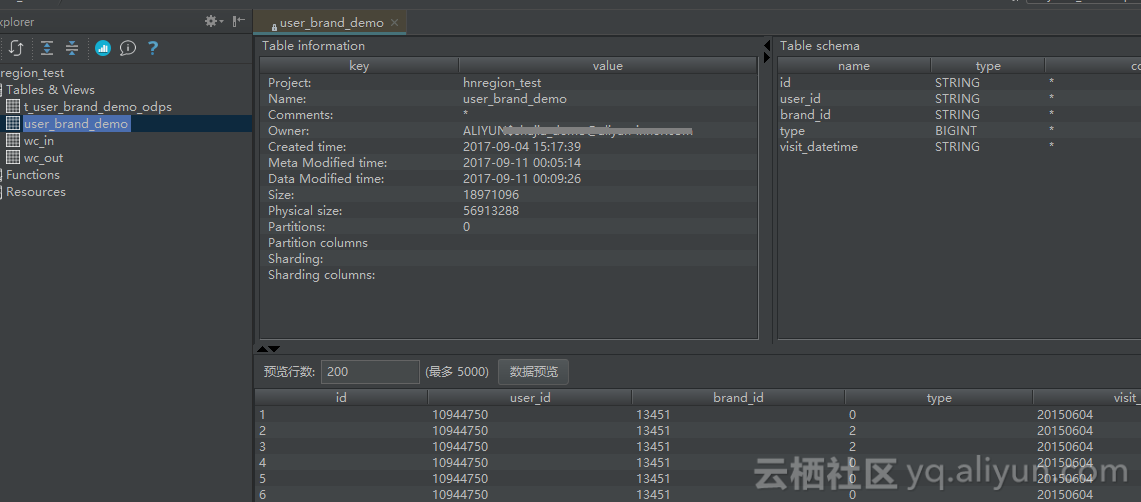
3.5 不要运行查询来探索或预览表数据 如果您想预览表数据,可以使用表预览选项查看数据,而不会产生费用。
在CLT使用read命令并指定预览的行数。
odps@ yinlin_demo>read mc2_ots.demo_dplus_summary 10;
3.6 在通过MaxCompute计算和通过RDS计算中寻找平衡
4、MR作业计算控制成本
4.1 设置合理的参数
4.2 MR减少中间环节
4.3 输入表的列裁剪
对于列数特别多的输入表,Map阶段处理只需要其中的某几列, 可以通过在添加输入表时明确指定输入的列,减少输入量; 例如只需要c1,c2俩列,可以这样设置:InputUtils.addTable(TableInfo.builder().tableName("wc_in").cols(new String[]{"c1","c2"}).build(), job);4.4 避免资源重复读取
4.5 减少对象构造开销
对于Map/Reduce阶段每次都会用到的一些java对象,避免在map/reduce函数里构造,可以放到setup阶段,避免多次构造产生的开销;{
...
Record word;
Record one;
public void setup(TaskContext context) throws IOException {
// 创建一次就可以,避免在map中每次重复创建
word = context.createMapOutputKeyRecord();
one = context.createMapOutputValueRecord();
one.set(new Object[]{1L});
}
...
}4.6 合理选择partition column或自定义partitioner
合理选择partition columns,可以使用JobConf#setPartitionColumns这个方法进行设置(默认是key schema定义的column),设置后数据将按照指定的列计算hash值分发到reduce中去, 避免数据倾斜导致作业长尾现象,如有必要也可以选择自定义partitioner,自定义partitioner的使用方法如下:import com.aliyun.odps.mapred.Partitioner;
public static class MyPartitioner extends Partitioner {
@Override
public int getPartition(Record key, Record value, int numPartitions) {
// numPartitions即对应reducer的个数
// 通过该函数决定map输出的key value去往哪个reducer
String k = key.get(0).toString();
return k.length() % numPartitions;
}
}jobconf.setPartitionerClass(MyPartitioner.class)jobconf.setNumReduceTasks(num)4.7 合理使用combiner
/**
* A combiner class that combines map output by sum them.
*/
public static class SumCombiner extends ReducerBase {
private Record count;
@Override
public void setup(TaskContext context) throws IOException {
count = context.createMapOutputValueRecord();
}
@Override
public void reduce(Record key, Iterator<Record> values, TaskContext context)
throws IOException {
long c = 0;
while (values.hasNext()) {
Record val = values.next();
c += (Long) val.get(0);
}
count.set(0, c);
context.write(key, count);
}
}5、计费模式转换
5.1 后付费转预付费
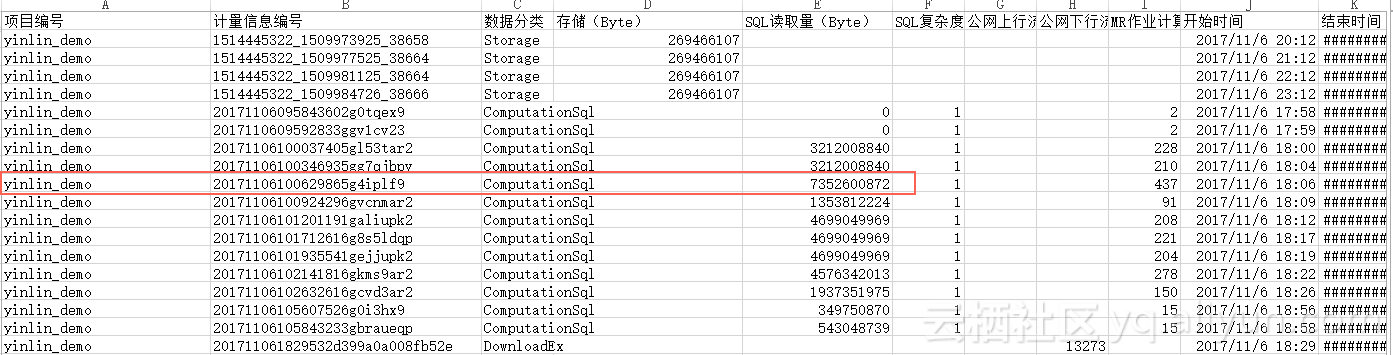
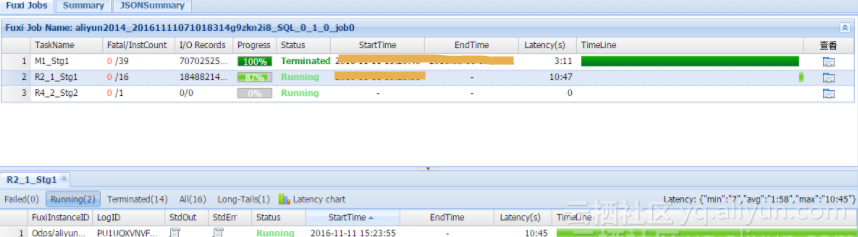
show p;--查看所有instance_id,例如20171106100629865g4iplf9
wait 20171106100629865g4iplf9;--查看每个instance_id的logview5.2 预付费+后付费混合模式
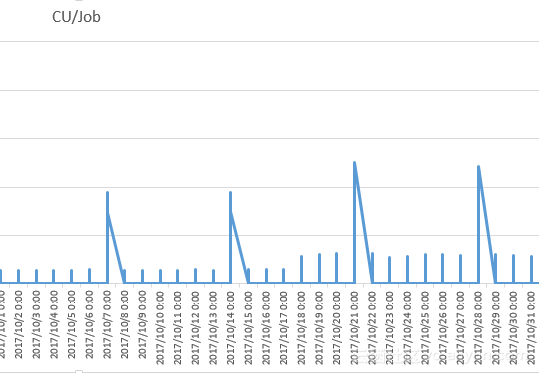
混合模式二,预付费做非周期任务或即席查询Adhoc+后付费生产业务(天级ETL)。企业为了控制日常数据探索带来的SQL健康度下降及费用不可控,可以把数据探索和非周期任务放在固定资源组,通过CU管家为开发组和BI组配置不同的二级资源,生产作业如果只是每天处理一次,可以通过弹性的方式跑在后付费资源组。
优化控制存储成本
1、设置合理的表生命周期
create table test3 (key boolean) partitioned by (pt string, ds string) lifecycle 100;alter table table_name set lifecycle days;2、合理设置数据分区
优化控制数据同步成本
1、尽可能使用经典网络和VPC网络
通过使用内部网络(经典网络、VPC)实现零成本数据导入、导出。2、合理利用ECS的公共下载资源
3、Tunnl文件上传优化
4、合理预估VPC专线
当数据在IDC机房,需要通过专线同步到MaxCompute的时候,我们需要做好带宽预估,平衡数据同步与带宽之间的成本。
举个例子,企业有50T数据上云,如果我们需要1天同步完成,我们需要多少带宽, 50T*1024(GB)* 8(小b)*/24小时*3600秒=4.7Gb/s,大约需要5G带宽;
分析账单与明细
1、账单及时查看

2、案例分析
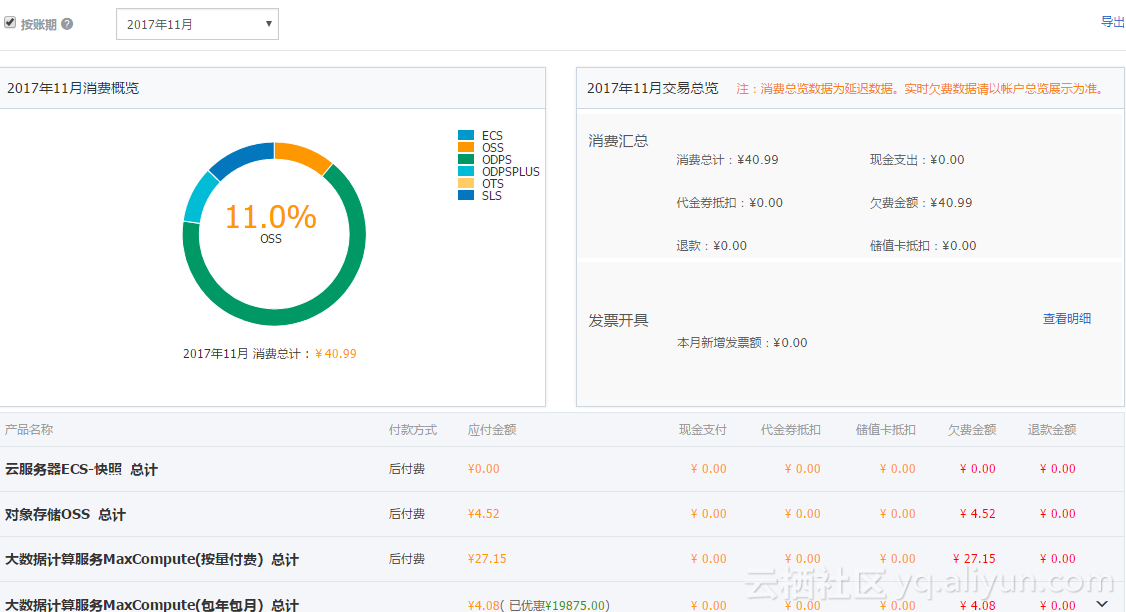
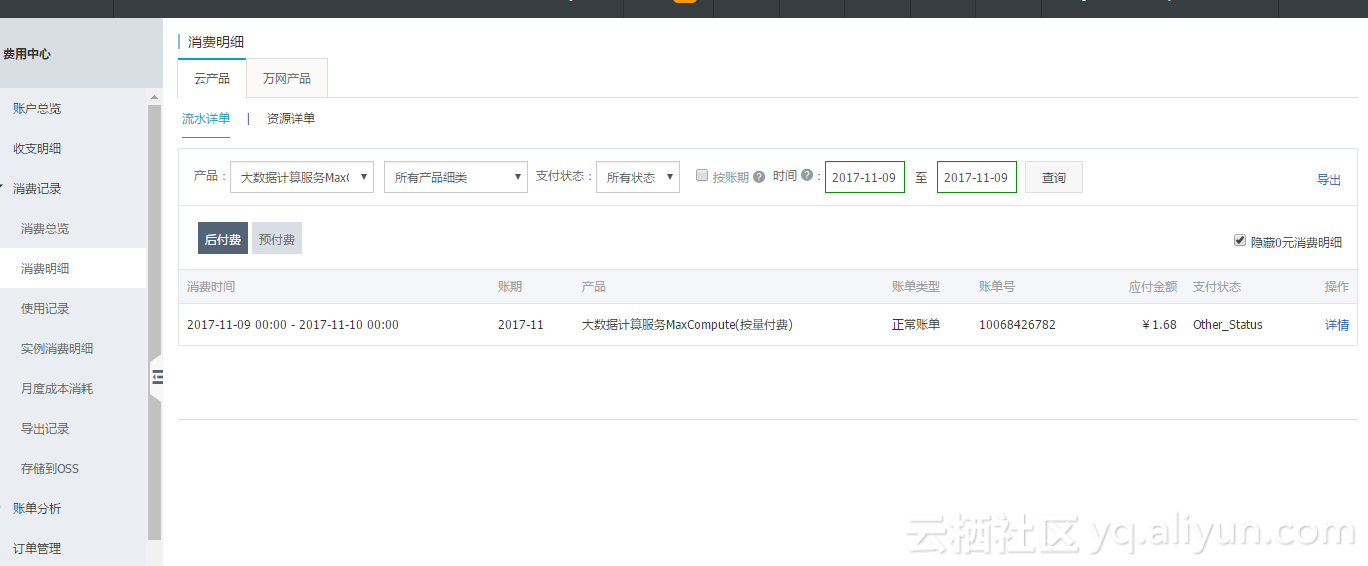
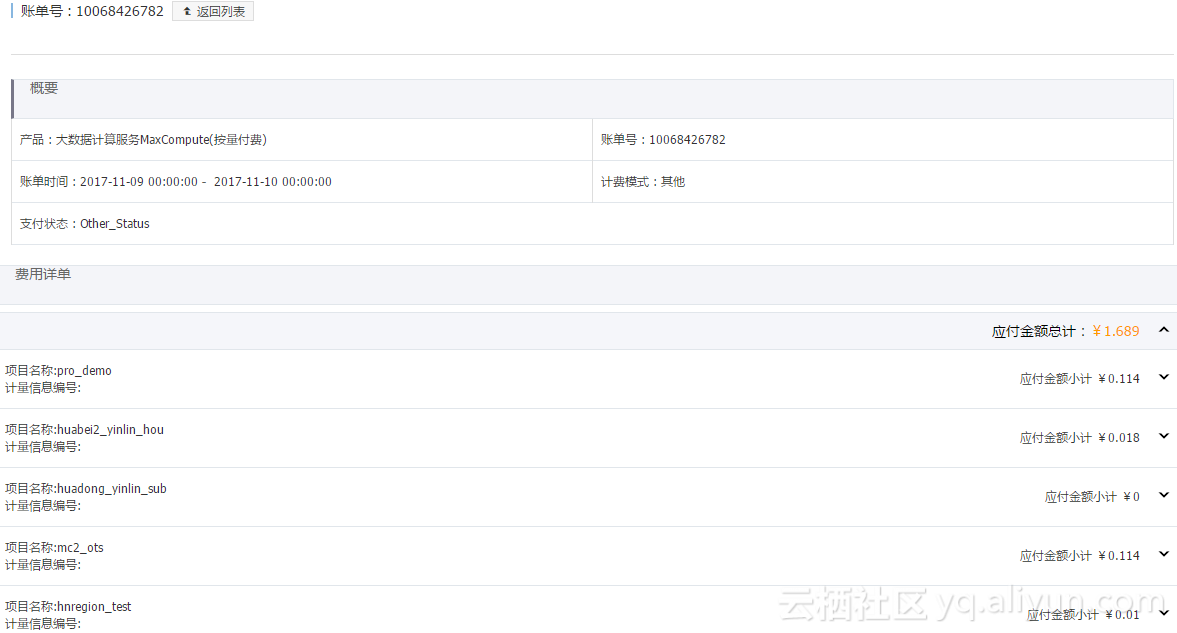
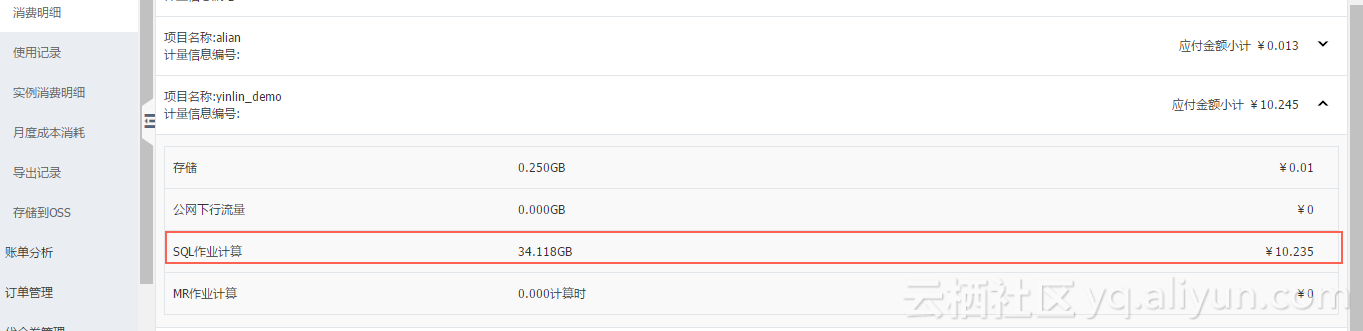



MaxCompute计费命令详解
客户非常关心收费细节,经常会问哪些命令是收费的。比如删除命令收不收费,更新数据收不收费。整理了一个表格,方便大家查阅MaxCompute 计算收费的命令;
| 语法表达式 |
用途 |
是否收费 |
样例 |
| Tunnel Download |
下载数据(经典网络) |
否 |
tunnel download Table_name e:/Table_name.txt;配置经典网络endpoint:http://dt.cn-shanghai.maxcompute.aliyun-inc.com |
| Tunnel Download |
下载数据(公网) |
收费 |
tunnel download Table_name e:/Table_name.txt;配置外网网络endpoint:http://dt.cn-shanghai.maxcompute.aliyun.com |
| Tunnel Upload |
上传数据 |
否 |
Tunnel upload e:/Table_name.txt Table_name; |
| Cost SQL |
费用预估 |
否 |
Cost SQL SELECT * from Table_name; |
| Read Table |
数据预览 |
否 |
read Table_name 10; |
| Insert Overwrite …Select |
数据更新 |
收费 |
insert overwrite table Table_name partition (sale_date='20180122') select shop_name, customer_id, total_price from sale_detail; |
| Desc Table |
查看表信息 |
否 |
desc Table_name; |
| Drop Table |
删除非分区表及数据 |
否 |
drop table if exists Table_name; |
| Create Table |
创建分区表 |
否 |
create table if not exists Table_name (key string ,value bigint) partitioned by (p string); |
| Create Table …Select |
创建分区表 |
收费 |
create table if not exists Table_name as select * from A_Tab; |
| Insert Into Table |
指定列插入数据 |
否 |
insert into table Table_name partition (p)(key,p) values ('d','20170101'),('e','20170101'),('f','20170101'); |
| Insert Into Table...Select |
插入数据 |
收费 |
insert into table Table_name select shop_name, customer_id, total_price from sale_detail; |
| Select UDF [not Count or All] from Table |
查询表数据 |
收费 |
Select sum(a) from Table_name; |
| Set Flag |
会话设置 |
否 |
set odps.sql.allow.fullscan=true; |
| Jar MR |
运行MapReduce作业 |
收费 |
jar -l com.aliyun.odps.mapred.example.WordCount wc_in wc_out |
| Add Jar/file/archive/table |
注册资源 |
否 |
add jar data\resources\mapreduce-examples.jar -f; |
| Drop Jar/file/archive/table |
删除资源 |
否 |
DROP RESOURCE sale.res |
| List Resources |
查看资源列表 |
否 |
list resources; |
| Get Resources |
下载资源 |
否 |
get resource odps-udf-examples.jar d:\; |
| Create Functions |
注册函数 |
否 |
CREATE FUNCTION test_lower |
| Drop Functions |
删除函数 |
否 |
DROP FUNCTION test_lower; |
| List Functions |
查看函数列表 |
否 |
list functions; |
| Alter Table |
删除分区表 |
否 |
Alter table user drop if exists partition(region='hangzhou',dt='20150923'); |
| TRUNCATE TABLE |
删除非分区表 |
否 |
TRUNCATE TABLE table_name; |
| CREATE EXTERNAL TABLE |
创建外表 |
否(公测) |
CREATE EXTERNAL TABLE IF NOT EXISTS ambulance_data_csv_external…LOCATION 'oss://oss-cn-shanghai-internal.aliyuncs.com/oss-odps-test/Demo/' |
| Select [EXTERNAL] TABLE |
读取外表 |
否(公测) |
select recordId, patientId, direction from ambulance_data_csv_external where patientId > 25; |
| Show Tables |
列出当前项目空间下所有的表 |
否 |
SHOW TABLES; |
| Show Partitions Tables |
列出一张表中的所有分区 |
否 |
SHOW PARTITIONS <table_name> |
| Show Instances/Show P |
返回由当前用户创建的实例信息 |
否 |
Show Instances/Show P |
| Wait Instance |
返回指定实例Logview |
否 |
Wait 20131225123302267gk3u6k4y2 |
| Status Instance |
返回指定实例的状态 |
否 |
Status 20131225123302267gk3u6k4y2 |
| Kill Instance |
停止您指定的实例 |
否 |
Kill 20131225123302267gk3u6k4y2 |
现在的企业数据资产繁杂众多,成本也会相应的提升,特别是建设大数据平台的企业,数据的类型、分布、实现技术、所属部门等都很繁杂,通过数据资产治理降低企业数据使用的成本,提高以数据指导管理决策的效率,已然成为大数据时代中企业竞争力的重要来源。
搜索钉钉群号:11782920,或扫码加入
 阿里巴巴大数据-玩家社区 https://yq.aliyun.com/teams/6/
阿里巴巴大数据-玩家社区 https://yq.aliyun.com/teams/6/
---阿里大数据博文,问答,社群,实践,有朋自远方来,不亦说乎……




