伴随互联网的高速发展,大数据成为炙手可热的时髦产物。随之而来的是关于大数据的存储与计算问题。作为能够对大量数据进行分布式处理的软件框架——Hadoop目前已经发展成为分析大数据的领先平台,它能够以一种可靠、高效、可伸缩的方式进行数据处理。

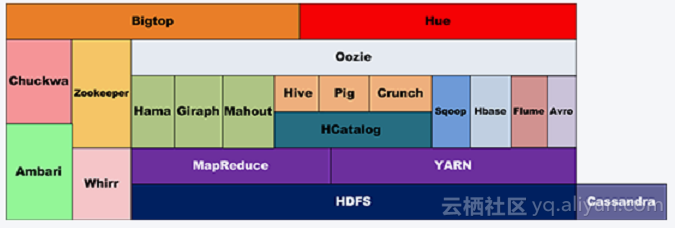
Hadoop生态圈的形成
大数据是个宽泛的问题,而Hadoop生态圈是最佳的大数据的解决方案。Hadoop生态圈的所有内容基本都是为了处理超过单机范畴的数据而产生的。
HDFS&MapReduce在最开始阶段Hadoop只包含HDFS(Hadoop Distributed FileSystem)和MapReduce两个组件。HDFS的设计本质是为解决大量数据分别存储于成百上千台机器上的问题,让客户看到的是一个文件系统而非很多文件系统,屏蔽复杂的底层调用。好比用户想要取/liusicheng/home/test1下的数据,只需要得到准确的路径即可获得数据,至于数据实际上被存放在不同的机器上这点用户根本不需要关心。HDFS帮助客户管理分散在不同机器上的PG级数据。这些数据如果都放在一台机器上处理,一定会导致恐怖的等待时间。于是,客户选择使用很多台机器处理数据。
Hadoop的第二个重要组件MapReduce被设计用来解决对多台机器实现工作分配,并完成机器之间的相互通信,最终完成客户部署的复杂计算。至此第一代hadoop已经具备了大数据管理和计算能力。
MapReduce计算模型虽然能用于很多模型,但过于简单粗暴,好用但笨重。为了解决MapReduce的这一缺陷,引入Tez和Spark使Map/Reduce模型更通用,让Map和Reduce之间的界限更模糊,数据交换更灵活,更少的磁盘读写以更方便描述复杂算法,取得更高吞吐量。
Pig&Hive解决完计算性能问题,就要往效率方面做努力,降低使用门槛。MapReduce的程序写起来非常麻烦,用更高层、更抽象的语言层来描述算法和数据处理流程可以有效降低使用门槛,提高工作效率。于是,利用Pig接近脚本方式描述MapReduce,利用Hive把脚本和SQL语言翻译成MapReduce程序,丢给计算引擎去计算。如此一来,一般客户也可以简单使用或维护hadoop了。
数据仓库hadoop生态圈完成的数据仓库架构为:底层HDFS;上面跑MapReduce/Tez/Spark;再往上跑Hive,Pig。这种数据仓库可以解决中低速数据处理的要求,多用于归档数据分析。客户有新的需求,需要数据仓库有更高的处理速度,来固定查询某些特定值,给网站实时动态变化提供数据。HBase、Cassandra和MongoDB等多种非关系型数据库,表现得比MapReduce要好很多,比如HBase会通过索引解决这个问题,而MapReduce很可能要扫描整个数据集。
除了这些基本组件属于hadoop生态外,分布式机器学习库Mahout,数据交换的编码库Protobuf和高一致性分布存取协同系统ZooKeeper等也在hadoop生态中发挥着作用。这么多工具在同一个集群上运转,调度系统Yarn就变得必不可少。上面组件仅是hadoop生态其中一部分,还有更多解决不同问题或处理不同场景的其他组件存在。
Hadoop的安全问题
回顾hadoop生态圈发展史,会发现hadoop中的所有产品都是根据不同用户需求开发。这就导致Hadoop生态圈中的产品缺乏共同的架构和整体的考虑,安全性会完全依赖hadoop框架来提供。而hadoop最初开发时并没有考虑安全因素,当时Hadoop的用例都是围绕着如何管理大量的公共web数据来考虑的,没有考虑数据的保密性和内部的复杂权限管理。按照Hadoop最初的设想,它假定集群总是处于可信的环境中,由可信用户使用的相互协作的可信计算机组成。这就导致整个Hadoop生态圈背后隐藏着种种“凶险”,具体的安全风险大致分为以下五大类:
-
缺乏安全认证
-
缺乏权限控制
-
缺乏关键行为审计
-
缺乏静态加密
-
缺乏动态加密
随着hadoop在云上的广泛运用,很多公司对hadoop提出了安全应对方案。如Yahoo提出的Kerberos体系解决安全认证问题、ACL解决访问控制问题。具体到每个产品会采用不同的解决手段。讨论解决方案之前,我们先详细了解一下hadoop的五种安全隐患。
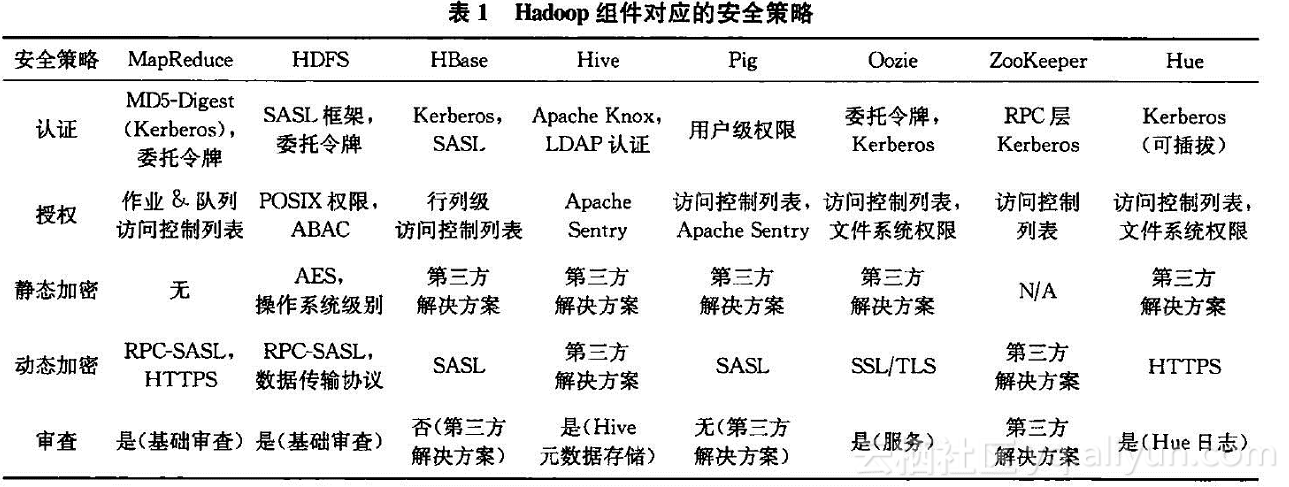
由于Hadoop中没有用户身份认证机制,所以任何用户都可以伪装成为其他合法用户,访问其在HDFS上的数据,获取MapReduce产生的结果,从而存在恶意攻击者假冒身份,篡改HDFS上他人的数据,提交恶意作业破坏系统、修改节点服务器的状态等隐患;由于集群缺乏对Hadoop服务器的认证,攻击者假冒成为DataNode或TaskTracker节点,加入集群,接受NameNode和JobTracker。一旦借助代码,任何用户都可以获取 root 权限,并非法访问 HDFS 或者 MapReduce 集群,恶意提交作业、修改 JonTracker 状态、篡改 HDFS 上的数据等。
身份验证基本可以认为是hadoop生态中最严重的安全问题。不解决“你是谁”的问题?会给hadoop带来冒充合法用户和冒充服务节点两大类问题。
较成熟的商业解决方法是通过Kerberos解决Hadoop身份认证。Kerberos通过相互认证的强认证方式,防止窃听的网络认证协议。每一位用户和服务都有一个主题属性和凭证来完成所有的RPC用户认证。但如果客户端和每个节点都要进行Kerberos认证,随着节点的扩展,KDC逐渐会成为整个系统的性能瓶颈。为了提高Kerberos的效率,加入委托令牌,利用对称加密的方式,共享密钥根据令牌的类型分布到成千上万个主机,利用Kerberos凭证从名字节点获得最初认证后,客户端获得1个委托令牌,并将它传递给下一个在名字节点上进行认证的作业。但委托令牌自身也存在一定问题。
hadoop推出了Kerberos+tokens的解决方式,但在实际使用中,由于不便利、不利于拓展性、降低效率等原因,并未广泛应用开来。
用户只要得知数据块的 Block ID 后,可以不经过 NameNode 的身份认证和服务授权,直接访问相应 DataNode,读取 DataNode 节点上的数据或者将文件写入 DataNode 节点,并可以随意启动假的 DataNode 和 TaskTracker。
对于 JobTracker,用户可以任意修改或者杀掉其他用户的作业,提高自身作业的优先级,JabTracker 对此不作任何控制。其中,无论是粗粒度的文件访问控制还是细粒度的ACL访问控制,都会或多或少强占hadoop集群内部的资源。可从外部在行为上进行额外的权限控制,尤其支持由hive的hadoop环境。只需要判hivesql语句的对象和当前用户的关键,就可以通过通讯阻断等方式达到权限控制的目的。
默认hadoop缺乏审计,可以通过hadoop系产品添加日志监控来完成一部分审计功能。通过日志的记录来判断整个流程中是否存在问题。这种日志的记录缺乏特征的判断和自动提示功能。完全可以利用进行改进后的审计产品来进行审计,只审计客户端的行为即可追查到恶意操作或误操作行为。
默认情况下Hadoop 在对集群HDFS 系统上的文件没有存储保护,所有数据均是明文存储在HDFS中,超级管理员可以不经过用户允许直接查看和修改用户在云端保存的文件,这就很容易造成数据泄露。采用静态加密的方式,对核心敏感数据进行加密处理,使得数据密文存储,防止泄露风险。
默认情况下Hadoop集群各节点之间,客户端与服务器之间数据明文传输,使得用户隐私数据、系统敏感信息极易在传输的过程被窃取。解决动态加密一般会提供一个附加的安全层。对于动态数据而言,即传输到或从hadoop生态系统传送出来的数据,利用简单认证与安全层(SASL)认证框架进行加密,通过添加一个安全层的方式,保证客户端和服务器传输数据的安全性,确保在中途不回被读。
结语
Hadoop生态的安全问题从2009年被众多厂商重视后,相继提出了很多解决方案。但大部分方案因为某些局限性并没有实际落地。能落地的主要是Yahoo提出的解决方案,此方案在实际落地中也存在诸多问题。目前,Hadoop安全问题已经成功引起广泛的关注,确保大型和复杂多样环境下的数据安全,将是非常具有市场前景的宏大课题。
分享完给自家产品打个广告,欢迎了解。
阿里云市场官方店铺:https://shop14d60793.market.aliyun.com/
云安全产品限时体验:http://www.dbscloud.cn/dbscloud1111.html







