创建一个Fork/Join池
在这个指南中,你将学习如何使用Fork/Join框架的基本元素。它包括:
- 创建一个ForkJoinPool对象来执行任务。
- 创建一个ForkJoinPool执行的ForkJoinTask类。
你将在这个示例中使用Fork/Join框架的主要特点,如下:
- 你将使用默认构造器创建ForkJoinPool。
- 在这个任务中,你将使用Java API文档推荐的结构:
1 |
If (problem size < default size){ |
5 |
resolve problem using another algorithm; |
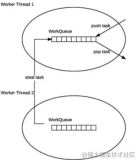
- 你将以一种同步方式执行任务。当一个任务执行2个或2个以上的子任务时,它将等待它们的结束。通过这种方式 ,正在执行这些任务的线程(工作线程)将会查找其他任务(尚未执行的任务)来执行,充分利用它们的执行时间。
- 你将要实现的任务将不会返回任何结果,所以你将使用RecursiveAction作为它们实现的基类。
准备工作
这个指南中的例子使用Eclipse IDE实现。如果你使用Eclipse或其他IDE,如NetBeans,打开它并创建一个新的Java项目。
如何做…
在这个指南中,你将继续实现一个任务来修改产品列表的价格。任务最初是负责更新一个队列中的所有元素。你将会使用10作为参考大小,如果一个任务必须更新超过10个元素,这些元素将被划分成两个部分,并创建两个任务来更新每个部分中的产品的价格。
按以下步骤来实现这个示例:
1.创建类Product,将用来存储产品的名称和价格。
2.声明一个私有的String类型的属性name和一个私有的double类型的属性price。
3.实现这些方法,用来设置和获取这两个属性的值。
01 |
public String getName() { |
04 |
public void setName(String name) { |
07 |
public double getPrice() { |
10 |
public void setPrice(double price) { |
4.创建ProductListGenerator类,用来产生随机产品的数列。
1 |
public class ProductListGenerator { |
5.实现generate()方法。它接收一个数列大小 的int类型参数,返回一个产生产品数列的List<Product>对象。
1 |
public List<Product> generate (int size) { |
6.创建返回产品数列的对象。
1 |
List<Product> ret=new ArrayList<Product>(); |
7.创建产品队列。给所有产品赋予相同值。比如,10用来检查程序是否工作得很好。
1 |
for (int i=0; i<size; i++){ |
2 |
Product product=new Product(); |
3 |
product.setName("Product"+i); |
8.创建Task类,指定它继承RecursiveAction类。
1 |
public class Task extends RecursiveAction { |
9.声明类的序列版本UID。这个元素是必需的,因为RecursiveAction类的父类ForkJoinTask实现了Serializable接口。
1 |
private static final long serialVersionUID = 1L; |
10.声明一个私有的、List<Product>类型的属性products。
1 |
private List<Product> products; |
11.声明两个私有的、int类型的属性first和last。这些属性将决定这个任务产品的阻塞过程。
12.声明一个私有的、double类型的属性increment,用来存储产品价格的增长。
1 |
private double increment; |
13.实现这个类的构造器,初始化所有属性。
1 |
public Task (List<Product> products, int first, int last, double increment) { |
2 |
this.products=products; |
5 |
this.increment=increment; |
14.实现compute()方法 ,该方法将实现任务的逻辑。
2 |
protected void compute() { |
15.如果last和first的差小于10(任务只能更新价格小于10的产品),使用updatePrices()方法递增的设置产品的价格。
16.如果last和first的差大于或等于10,则创建两个新的Task对象,一个处理产品的前半部分,另一个处理产品的后半部分,然后在ForkJoinPool中,使用invokeAll()方法执行它们。
2 |
int middle=(last+first)/2; |
3 |
System.out.printf("Task: Pending tasks: |
4 |
%s\n",getQueuedTaskCount()); |
5 |
Task t1=new Task(products, first,middle+1, increment); |
6 |
Task t2=new Task(products, middle+1,last, increment); |
17.实现updatePrices()方法。这个方法更新产品队列中位于first值和last值之间的产品。
1 |
private void updatePrices() { |
2 |
for (int i=first; i<last; i++){ |
3 |
Product product=products.get(i); |
4 |
product.setPrice(product.getPrice()*(1+increment)); |
18.实现这个示例的主类,通过创建Main类,并实现main()方法。
2 |
public static void main(String[] args) { |
19.使用ProductListGenerator类创建一个包括10000个产品的数列。
1 |
ProductListGenerator generator=new ProductListGenerator(); |
2 |
List<Product> products=generator.generate(10000); |
20.创建一个新的Task对象,用来更新产品队列中的产品。first参数使用值0,last参数使用值10000(产品数列的大小)。
1 |
Task task=new Task(products, 0, products.size(), 0.20); |
21.使用无参构造器创建ForkJoinPool对象。
1 |
ForkJoinPool pool=new ForkJoinPool(); |
22.在池中使用execute()方法执行这个任务 。
23.实现一个显示关于每隔5毫秒池中的变化信息的代码块。将池中的一些参数值写入到控制台,直到任务完成它的执行。
02 |
System.out.printf("Main: Thread Count: %d\n",pool.getActiveThreadCount()); |
03 |
System.out.printf("Main: Thread Steal: %d\n",pool.getStealCount()); |
04 |
System.out.printf("Main: Parallelism: %d\n",pool.getParallelism()); |
06 |
TimeUnit.MILLISECONDS.sleep(5); |
07 |
} catch (InterruptedException e) { |
10 |
} while (!task.isDone()); |
24.使用shutdown()方法关闭这个池。
25.使用isCompletedNormally()方法检查假设任务完成时没有出错,在这种情况下,写入一条信息到控制台。
1 |
if (task.isCompletedNormally()){ |
2 |
System.out.printf("Main: The process has completed |
26.在增长之后,所有产品的价格应该是12。将价格不是12的所有产品的名称和价格写入到控制台,用来检查它们错误地增长它们的价格。
1 |
for (int i=0; i<products.size(); i++){ |
2 |
Product product=products.get(i); |
3 |
if (product.getPrice()!=12) { |
4 |
System.out.printf("Product %s: %f\n",product.getName(),product.getPrice()); |
27.写入一条信息到控制台表明程序的结束。
1 |
System.out.println("Main: End of the program.\n"); |
它是如何工作的…
在这个示例中,你已经创建一个ForkJoinPool对象和一个在池中执行的ForkJoinTask类的子类。为了创建ForkJoinPool对象,你已经使用了无参构造器,所以它会以默认的配置来执行。它创建一个线程数等于计算机处理器数的池。当ForkJoinPool对象被创建时,这些线程被创建并且在池中等待,直到有任务到达让它们执行。
由于Task类没有返回结果,所以它继承RecursiveAction类。在这个指南中,你已经使用了推荐的结构来实现任务。如果这个任务更新超过10产品,它将被分解成两部分,并创建两个任务,一个任务执行一部分。你已经在Task类中使用first和last属性,用来了解这个任务要更新的产品队列的位置范围。你已经使用first和last属性,只复制产品数列一次,而不是为每个任务创建不同的数列。
它调用invokeAll()方法,执行每个任务所创建的子任务。这是一个同步调用,这个任务在继续(可能完成)它的执行之前,必须等待子任务的结束。当任务正在等待它的子任务(结束)时,正在执行它的工作线程执行其他正在等待的任务。在这种行为下,Fork/Join框架比Runnable和Callable对象本身提供一种更高效的任务管理。
ForkJoinTask类的invokeAll()方法是执行者(Executor)和Fork/Join框架的一个主要区别。在执行者框架中,所有任务被提交给执行者,而在这种情况下,这些任务包括执行和控制这些任务的方法都在池内。你已经在Task类中使用invokeAll()方法,它是继承了继承ForkJoinTask类的RecursiveAction类。
你使用execute()方法提交唯一的任务给这个池,用来所有产品数列。在这种情况下,它是一个异步调用,而主线程继续它的执行。
你已经使用ForkJoinPool类的一些方法,用来检查正在运行任务的状态和变化。基于这个目的,这个类包括更多的方法。参见有这些方法完整列表的监控一个Fork/Join池指南。
最后,与执行者框架一样,你应该使用shutdown()方法结束ForkJoinPool。
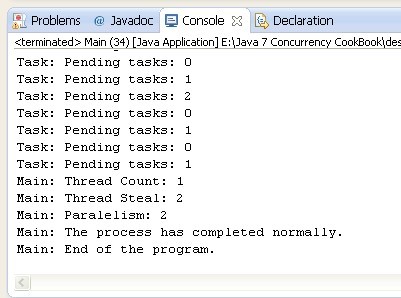
以下截图显示这个示例执行的一部分:
你可以看出任务正在完成它们的工作和产品价格的更新。
不止这些…
ForkJoinPool类提供其他的方法,用来执行一个任务。这些方法如下:
- execute (Runnable task):这是在这个示例中,使用的execute()方法的另一个版本。在这种情况下,你可以提交一个Runnable对象给ForkJoinPool类。注意:ForkJoinPool类不会对Runnable对象使用work-stealing算法。它(work-stealing算法)只用于ForkJoinTask对象。
- invoke(ForkJoinTask<T> task):当execute()方法使用一个异步调用ForkJoinPool类,正如你在本示例中所学的,invoke()方法使用同步调用ForkJoinPool类。这个调用不会(立即)返回,直到传递的参数任务完成它的执行。
- 你也可以使用在ExecutorService接口的invokeAll()和invokeAny()方法。这些方法接收一个Callable对象作为参数。ForkJoinPool类不会对Callable对象使用work-stealing算法,所以你最好使用执行者去执行它们。
ForkJoinTask类同样提供在示例中使用的invokeAll()的其他版本。这些版本如下:
- invokeAll(ForkJoinTask<?>… tasks):这个版本的方法使用一个可变参数列表。你可以传入许多你想要执行的ForkJoinTask对象作为参数。
- invokeAll(Collection<T> tasks):这个版本的方法接收一个泛型类型T对象的集合(如:一个ArrayList对象,一个LinkedList对象或者一个TreeSet对象)。这个泛型类型T必须是ForkJoinTask类或它的子类。
即使ForkJoinPool类被设计成用来执行一个ForkJoinTask,你也可以直接执行Runnable和Callable对象。你也可以使用ForkJoinTask类的adapt()方法来执行任务,它接收一个Callable对象或Runnable对象(作为参数)并返回一个ForkJoinTask对象。 参见
- 在第8章,测试并发应用程序中的监控一个Fork/Join池的指南


{kind=link}