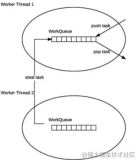
异步运行任务
当你在ForkJoinPool中执行ForkJoinTask时,你可以使用同步或异步方式来实现。当你使用同步方式时,提交任务给池的方法直到提交的任务完成它的执行,才会返回结果。当你使用异步方式时,提交任务给执行者的方法将立即返回,所以这个任务可以继续执行。
你应该意识到这两个方法有很大的区别,当你使用同步方法,调用这些方法(比如:invokeAll()方法)的任务将被阻塞,直到提交给池的任务完成它的执行。这允许ForkJoinPool类使用work-stealing算法,分配一个新的任务给正在执行睡眠任务的工作线程。反之,当你使用异步方法(比如:fork()方法),这个任务将继续它的执行,所以ForkJoinPool类不能使用work-stealing算法来提高应用程序的性能。在这种情况下,只有当你调用join()或get()方法来等待任务的完成时,ForkJoinPool才能使用work-stealing算法。
在这个指南中,你将学习如何使用ForkJoinPool和ForkJoinTask类提供的异步方法来管理任务。你将实现一个程序,在一个文件夹及其子文件夹内查找确定扩展名的文件。你将实现ForkJoinTask类来处理文件夹的内容。对于文件夹里的每个子文件夹,它将以异步的方式提交一个新的任务给ForkJoinPool类。对于文件夹里的每个文件,任务将检查文件的扩展名,如果它被处理,并把它添加到结果列表。
如何做…
按以下步骤来实现这个例子:
1.创建FolderProcessor类,指定它继承RecursiveTask类,并参数化为List<String>类型。
1 |
public class FolderProcessor extends RecursiveTask<List<String>> { |
2.声明这个类的序列号版本UID。这个元素是必需的,因为RecursiveTask类的父类,ForkJoinTask类实现了Serializable接口。
1 |
private static final long serialVersionUID = 1L; |
3.声明一个私有的、String类型的属性path。这个属性将存储任务将要处理的文件夹的全路径。
4.声明一个私有的、String类型的属性extension。这个属性将存储任务将要查找的文件的扩展名。
1 |
private String extension; |
5.实现这个类的构造器,初始化它的属性。
1 |
public FolderProcessor (String path, String extension) { |
3 |
this.extension=extension; |
6.实现compute()方法。正如你用List<String>类型参数化RecursiveTask类,这个方法将返回这个类型的一个对象。
2 |
protected List<String> compute() { |
7.声明一个String对象的数列,用来保存存储在文件夹中的文件。
1 |
List<String> list=new ArrayList<>(); |
8.声明一个FolderProcessor任务的数列,用来保存将要处理存储在文件夹内的子文件夹的子任务。
1 |
List<FolderProcessor> tasks=new ArrayList<>(); |
9.获取文件夹的内容。
1 |
File file=new File(path); |
2 |
File content[] = file.listFiles(); |
10.对于文件夹里的每个元素,如果是子文件夹,则创建一个新的FolderProcessor对象,并使用fork()方法异步地执行它。
2 |
for (int i = 0; i < content.length; i++) { |
3 |
if (content[i].isDirectory()) { |
4 |
FolderProcessor task=new FolderProcessor(content[i]. |
5 |
getAbsolutePath(), extension); |
11.否则,使用checkFile()方法比较这个文件的扩展名和你想要查找的扩展名,如果它们相等,在前面声明的字符串数列中存储这个文件的全路径。
2 |
if (checkFile(content[i].getName())){ |
3 |
list.add(content[i].getAbsolutePath()); |
12.如果FolderProcessor子任务的数列超过50个元素,写入一条信息到控制台表明这种情况。
2 |
System.out.printf("%s: %d tasks ran.\n",file. |
3 |
getAbsolutePath(),tasks.size()); |
13.调用辅助方法addResultsFromTask(),将由这个任务发起的子任务返回的结果添加到文件数列中。传入参数:字符串数列和FolderProcessor子任务数列。
1 |
addResultsFromTasks(list,tasks); |
14.返回字符串数列。
15.实现addResultsFromTasks()方法。对于保存在tasks数列中的每个任务,调用join()方法,这将等待任务执行的完成,并且返回任务的结果。使用addAll()方法将这个结果添加到字符串数列。
1 |
private void addResultsFromTasks(List<String> list, |
2 |
List<FolderProcessor> tasks) { |
3 |
for (FolderProcessor item: tasks) { |
4 |
list.addAll(item.join()); |
16.实现checkFile()方法。这个方法将比较传入参数的文件名的结束扩展是否是你想要查找的。如果是,这个方法返回true,否则,返回false。
1 |
private boolean checkFile(String name) { |
2 |
return name.endsWith(extension); |
17.实现这个例子的主类,通过创建Main类,并实现main()方法。
2 |
public static void main(String[] args) { |
18.使用默认构造器创建ForkJoinPool。
1 |
ForkJoinPool pool=new ForkJoinPool(); |
19.创建3个FolderProcessor任务。用不同的文件夹路径初始化每个任务。
1 |
FolderProcessor system=new FolderProcessor("C:\\Windows", |
3 |
FolderProcessor apps=new |
4 |
FolderProcessor("C:\\Program Files","log"); |
5 |
FolderProcessor documents=new FolderProcessor("C:\\Documents |
20.在池中使用execute()方法执行这3个任务。
3 |
pool.execute(documents); |
21.将关于池每秒的状态信息写入到控制台,直到这3个任务完成它们的执行。
02 |
System.out.printf("******************************************\n"); |
03 |
System.out.printf("Main: Parallelism: %d\n",pool. |
05 |
System.out.printf("Main: Active Threads: %d\n",pool. |
06 |
getActiveThreadCount()); |
07 |
System.out.printf("Main: Task Count: %d\n",pool. |
08 |
getQueuedTaskCount()); |
09 |
System.out.printf("Main: Steal Count: %d\n",pool. |
11 |
System.out.printf("***************************************** |
14 |
TimeUnit.SECONDS.sleep(1); |
15 |
} catch (InterruptedException e) { |
18 |
} while((!system.isDone())||(!apps.isDone())||(!documents. |
22.使用shutdown()方法关闭ForkJoinPool。
23.将每个任务产生的结果数量写入到控制台。
3 |
System.out.printf("System: %d files found.\n",results.size()); |
5 |
System.out.printf("Apps: %d files found.\n",results.size()); |
6 |
results=documents.join(); |
7 |
System.out.printf("Documents: %d files found.\n",results. |
它是如何工作的…
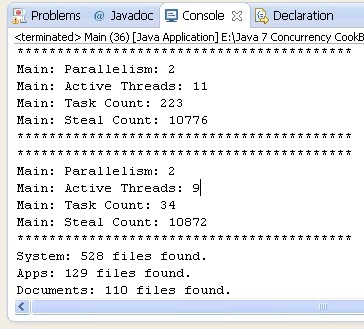
以下截图显示了这个例子执行的一部分:
这个例子的关键是FolderProcessor类。每个任务处理文件夹的内容。如你所知,这个内容有以下两种元素:
如果任务找到一个文件夹,它创建另一个Task对象来处理这个文件夹,并使用fork()方法把它(Task对象)提交给池。这个方法提交给池的任务将被执行,如果池中有空闲的工作线程或池可以创建一个新的工作线程。这个方法会立即返回,所以这个任务可以继续处理文件夹的内容。对于每个文件,任务将它的扩展与所想要查找的(扩展)进行比较,如果它们相等,将文件名添加到结果数列。
一旦这个任务处理完指定文件夹的所有内容,它将使用join()方法等待已提交到池的所有任务的结束。这个方法在一个任务等待其执行结束时调用,并返回compute()方法返回的值。这个任务将它自己发送的所有任务的结果和它自己的结果分组,并返回作为compute()方法的一个返回值的数组。
ForkJoinPool类同时允许任务的执行以异步的方式。你已经使用execute()方法,提交3个初始任务给池。在Main类中,你也使用shutdown()方法结束池,并打印关于正在池中运行任务的状态和变化的信息。ForkJoinPool类包含更多方法,可用于这个目的(异步执行任务)。参见监控一个Fork/Join池指南,看这些方法完整的列表。
不止这些…
在这个示例中,你已经使用了join()方法来等待任务的结束,并获得它们的结果。对于这个目的,你也可以使用get()方法的两个版本之一:
- get():这个版本的get()方法,如果ForkJoinTask已经结束它的执行,则返回compute()方法的返回值,否则,等待直到它完成。
- get(long timeout, TimeUnit unit):这个版本的get()方法,如果任务的结果不可用,则在指定的时间内等待它。如果超时并且任务的结果仍不可用,这个方法返回null值。TimeUnit类是一个枚举类,包含以下常量:DAYS,HOURS,MICROSECONDS, MILLISECONDS,MINUTES, NANOSECONDS 和 SECONDS。
get()和join()有两个主要的区别:
- join()方法不能被中断。如果你中断调用join()方法的线程,这个方法将抛出InterruptedException异常。
- 如果任务抛出任何未受检异常,get()方法将返回一个ExecutionException异常,而join()方法将返回一个RuntimeException异常。
参见
- 在第5章,Fork/Join框架中的创建一个Fork/Join池指南
- 在第8章,测试并发应用程序中的监控一个Fork/Join池指南