目标代码文件、可执行文件和库
C编程的基本策略是使用程序将源代码文件转换为可执行文件,此文件包含可以运行的机器语言代码。C分两步完成这一工作:编译和链接。编译器将源代码转换为中间代码,链接器将此中间代码与其他代码相结合来生成可执行文件。C使用被划分为两部分的这一方法使程序便于模块化。我们可以分别编译各个模块,然后使用链接器将编译过的模块结合起来。这样,如果需要改变一个模块,则不必重新编译所有其他模块。同时,链接器将自己的程序与预编译的库代码结合起来。
中间文件的形式有多种选择。最一般的选这,同时也是大部分C程序员的选择,是将源代码转换为机器语言代码,将结果放置在一个目标代码文件(简称为目标文件)中。虽然目标文件包含机器语言代码,但该文件还不能运行。目标文件包含源代码的转换结果,但该转换结果并不是一个完整的程序。
目标代码文件中的所缺少的第一个元素的一种叫做启动代码(start-up code)的东东,此代码相当于自己程序和操作系统之间的接口。
目标代码中缺少的第二个元素是库函数的代码。几乎所有C程序都利用标准C库中包含的库函数。比如printf()函数,目标代码文件不包含这一函数的代码,它只包含声明使用printf()函数的指令。实际代码存储在库中。库文件中包含许多函数的目标代码。
链接器的作用是将这3个元素(目标代码、系统的标准启动代码和库代码)结合在一起,并将它们存放在单个文件,即可执行文件中。对库代码来说,链接器只从库中提取我们编写代码中使用函数所需要的代码。
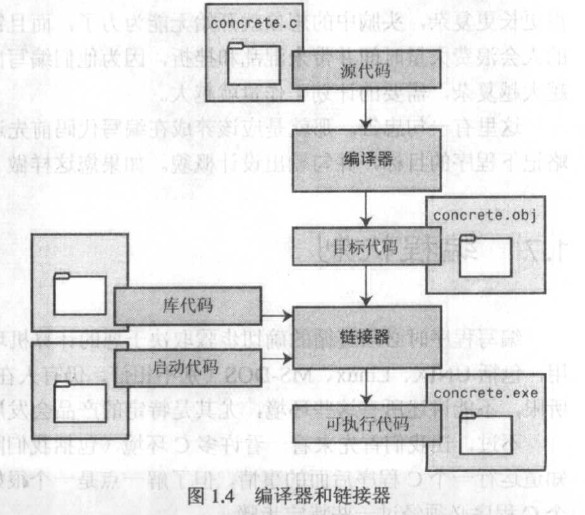
简而言之,目标文件和可执行文件都是由机器语言指令组成的。但目标文件只包含自己编写的代码转换成机器语言,而可执行文件还包含我们编写代码中使用的库例程以及启动代码的机器代码。
变量:
int num;//declaraion statement 声明语句
这个特殊的例子声明两件事情。第一,在函数中有一个名为num的变量。第二,int说明num是一个整数,也就是说,这个数没有小数点或者小数部分。编译器使用这个信息为变量num在内存中分配一个合适的存储空间。句末的分号指明这一行是C语言的一个语句和指令。分号是语句的一部分,否则该语句被认为是不完整的;
例子中的单词num是一个标识符(idfentifier),也就是你为一个变量、函数或者其他实体所选的名字。这样该声明把一个特殊的标识符和计算机内存中的一个特殊的位置联系起来,同时确定了该位置存储的信息类型(也即数据类型)。
变量与常量的区别在于,变量的值可以在程序执行过程中变化与指定,而常量则不可以;
浮点数的在内存的中的存储:
浮点数(floating-point)差不多可以和数学中的实数概念相对应。实数包含了整数之间的那些数。2.75、3.16E7、 7.00和2e-8都是浮点数。
最重要的一点是浮点数与整数的存储方案不同。浮点数表示法将一个数分为小数部分和指数部分并分别存储。因此尽管7.00和整数7有相同的值,但它们的存储方式不同。与机器中的二进制存储方式相似,在十进制中的7.0可表示0.7E1;
declaration statement 声明语句
identifier 标识符
assignment statement 赋值语句
argument 参数
actual argument 实际参数
newline character 换行符
Escape Sequence转义字符
reserved identifier 保留标识符
format specifier 格式说明符
%0 %x
想要显示C语言前缀,可以使用说明符%#o、%#x、%#X分别生成0、0x、0X前缀;
%d 是一个占位符
%告诉程序把一个变量在这个位置输出,d告诉程序将输出一个十进制整形变量;
printf()中的f暗示着这是一种格式化(formating)的输出函数;
编译器的一个常见毛病是发现的错误位置比真正的错误要滞后一行,例如,编译器
要编译下一行时才发现上一行缺少一个分号。因此,如果编译器指出来某个具有分号
的行少了分号,那么请检查上一行;
字(word)是自然的存储单位,8位机,一个字8位,16位机,一个字16位,32位机,一个
字32位;
int类型存储在计算机的一个字中;
为什么说long和short类型“可能”占用比int类型更多或者更少的存储空间呢?因为C仅保证
short类型不会比int类型长,并且long类型不会比int类型短,这样做是为了适应不同的机器;
(涉及到不用厂商生产芯片不同)
