1. 简介
Presto 是一个运行在集群之上的分布式系统。一个完全的安装报考一个 coordinator 进程和多个 workers 进程。查询通过一个客户端例如 Presto CLI 提交到 coordinator 进程。这个 coordinator 进程解析、分析并且生成查询的执行计划,然后将执行过程分发到 workers 进程。
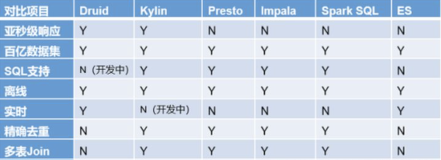
下面是一个架构图(图来自 http://www.dw4e.com/?p=141,此图将官网的架构图稍微修改了一下,增加了 Discovery 的服务,这样可能看起来会更清楚一些):

Presto 查询引擎是一个 Master-Slave 的架构,由一个 Coordinato r节点,一个 Discovery Server 节点,多个 Worker 节点组成,Discovery Server 通常内嵌于 Coordinator 节点中。Coordinator 负责解析 SQL 语句,生成执行计划,分发执行任务给 Worker 节点执行。Worker 节点负责实际执行查询任务。Worker 节点启动后向 Discovery Server 服务注册,Coordinator 从 Discovery Server 获得可以正常工作的 Worker 节点。如果配置了 Hive Connector,需要配置一个 Hive MetaStore 服务为 Presto 提供 Hive 元信息,Worker 节点与 HDFS 交互读取数据。
2. 要求
Presto 有以下几个基本要求:
- Linux 或者 Mac OS X 系统
- Java 8,64位
- Python 2.4++
2.1 连接器
Presto 支持可插拔的连接器用于提供数据查询。不同连接器的要求不一样。
HADOOP/HIVE
Presto 支持读以下版本的 hive 数据:
- Apache Hadoop 1.x,使用
hive-hadoop1连接器 - Apache Hadoop 2.x,使用
hive-hadoop2连接器 - Cloudera CDH 4,
使用 hive-cdh4连接器 - Cloudera CDH 5,
使用 hive-cdh5连接器
支持以下格式:Text、SequenceFile、RCFile、ORC。
另外,还需要一个远程的 Hive metastore 服务。本地的或者嵌入式模式是不支持的。Presto 不使用 MapReduce 并且只需要 HDFS。
CASSANDRA
Cassandra 2.x 是需要的。这个连接器是完全独立于 Hive 连接器的并且仅仅需要一个安装好的 Cassandra 集群。
TPC-H
TPC-H 连接器动态地生成数据用于实验和测试 Presto。这个连接器没有额外的要求。
当然,Presto 还支持一些其他的连接器,包括:
- JMX
- Kafka
- MySQL
- PostgreSQL
3. 使用场景
3.1 What Presto Is Not
Presto 支持 SQL 并提供了一个标准数据库的语法特性,但其不是一个通常意义上的关系数据库,他不是关系数据库,如 MySQL、PostgreSQL 或者 Oracle 的替代品。Presto 不是设计用来解决在线事物处理(OLTP)。
3.2 What Presto Is
Presto 是一个工具,被用来通过分布式查询来有效的查询大量的数据。Presto 是一个可选的工具,可以用来查询 HDFS,通过使用 MapReduce 的作业的流水线,例如 hive,pig,但是又不限于查询 HDFS 数据,它还能查询其他的不同数据源的数据,包括关系数据库以及其他的数据源,比如 cassandra。
Presto 被设计为处理数据仓库和分析:分析数据,聚合大量的数据并产生报表,这些场景通常被定义为 OLAP。
3.3 Who uses Presto?
国外:
- Facebook,Presto 的开发者
国内:
- 腾讯,待考证
- 美团,Presto实现原理和美团的使用实践
- 窝窝团,#数据技术选型#即席查询Shib+Presto,集群任务调度HUE+Oozie
4. 资料
以下是一些资料,希望对你了解 Presto 有所帮助:
- Presto官方文档:http://prestodb.io/
-
Shib:Shib is a web-client written in Node.js designed to query Presto and Hive.
-
Facebook Presto团队介绍Presto的文章: https://www.facebook.com/notes/facebook-engineering/presto-interacting-with-petabytes-of-data-at-facebook/10151786197628920
-
SlideShare两个分享Presto 的PPT: http://www.slideshare.net/zhusx/presto-overview?from_search=1 和 http://www.slideshare.net/frsyuki/hadoop-source-code-reading-15-in-japan-presto
- Presto的单节点和多节点配置
- Impala Presto wiki 主要介绍了 Presto 的架构、原理和工作流程,以及和 impala 的对比。
- 记录Presto数据查询引擎的配置过程