1、修改core-site.xml,配置hdfs
1 <configuration> 2 <property> 3 <name>fs.default.name</name> 4 <value>hdfs://localhost:9000</value> 5 </property> 6 <property> 7 <name>hadoop.tmp.dir</name> 8 <value>/home/jimmy/Desktop/tmp</value> 9 </property> 10 </configuration>
注:
a) fs.default.name对应的value是hdfs的ip和端口,只要端口不被占用即可
b) hadoop.tmp.dir对应的value是hadoop临时文件的保存目录(根据需要修改成实际目录)
2、修改hdfs-site.xml,配置数据备份
1 <configuration> 2 <property> 3 <name>dfs.replication</name> 4 <value>1</value> 5 </property> 6 </configuration>
注:这是配置写数据时,数据同时写几份(出于学习目的,这里只写一个副本,实际应用中,至少配置成3)
3、修改mapred-site.xml
1 <configuration> 2 <property> 3 <name>mapred.job.tracker</name> 4 <value>localhost:9001</value> 5 </property> 6 </configuration>
注:这是配置map/reduce服务器ip和端口
4、配置ssh
注:因为伪分布模式下,即使所有节点都在一台机器上,hadoop也需要通过ssh登录,这一步的目的是配置本机无密码ssh登录
命令行:ssh-keygen -t rsa
然后一路回车
cd ~/.ssh
cat id_rsa.pub>>authorized.keys
测试:ssh localhost
首次运行会提示是否继续,输入yes,回车,如果不要求输入密码,就表示成功了
5、首次运行,格式化hdfs
<HADOOP_HOME>/bin/hadoop namenode -format
6、启动单节点集群
<HADOOP_HOME>/bin/hadoop start-all.sh
如果没问题的话,命令行输入jps,可以看到5个进程:
jimmy@ubuntu:~/Desktop/soft/hadoop-1.2.1$ jps
13299 TaskTracker
13071 SecondaryNameNode
13363 Jps
13160 JobTracker
12786 NameNode
12926 DataNode
停止的话,类似的 bin/hadoop stop-all.sh
7、查看状态
http://localhost:50030/ 这是Hadoop管理界面
http://localhost:50060/ 这是Hadoop Task Tracker 状态
http://localhost:50070/ 这是Hadoop DFS 状态
8、伪分布模式下运行Hadoop自带的wordcount
注:以下命令的当前目录都是hadoop根目录
a) 先随便准备一个txt文件,比如hadoop下自带的README.txt
b) hdfs中创建一个输入目录input
bin/hadoop fs -mkdir input (注:hdfs中的命令跟linux终端中的文件操作命令基本类似,但是前面要加fs)
c) 将README.txt放到hdfs的input目录中
bin/hadoop fs -put ./README.txt input
这时,如果在浏览器里用http://localhost:50070/ 浏览hdfs文件列表的话,可以看到刚才放进去的文件
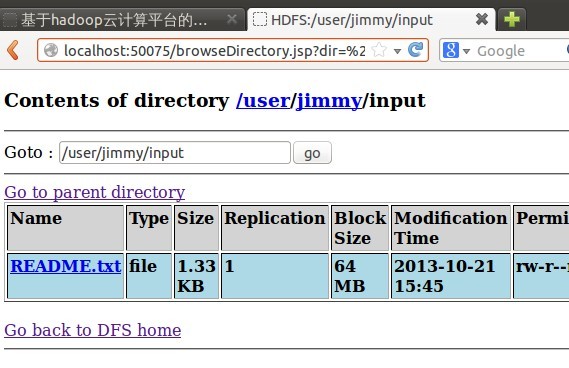
d)执行wordcount示例程序
bin/hadoop jar hadoop-examples-1.2.1.jar wordcount /user/jimmy/input/README.txt /user/jimmy/output (注:这里的jimmy为hadoop运行时的用户名,根据需要换成自己的实际用户名)
e)从hdfs中取回文件到本地
bin/hadoop fs -get /user/jimmy/output ~/Desktop/ (这样,就把运算结果output中的文件,取到本地桌面了)
