hadoop 2.6的“伪”分式安装与“全”分式安装相比,大部分操作是相同的,主要区别在于不用配置slaves文件,而且其它xxx-core.xml里的参数很多也可以省略,下面是几个关键的配置:
(安装JDK、创建用户、设置SSH免密码 这些准备工作,大家可参考hadoop 2.6全分布安装 一文,以下所有配置文件,均在$HADOOP_HOME/etc/hadoop目录下)
另外,如果之前用 yum install hadoop安装过低版本的hadoop,请先卸载干净(即:yum remove hadoop)
一、修改hadoop-env.sh
主要是设置JAVA_HOME的路径,另外按官网说法还要添加一个HADOOP_PREFIX的导出变量,参考下面的内容:
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.65.x86_64
export HADOOP_PREFIX=/home/hadoop/hadoop-2.6.0
二、修改core-site.xml
1 <configuration> 2 <property> 3 <name>fs.defaultFS</name> 4 <value>hdfs://172.xx.xx.xxx:9000</value> 5 </property> 6 <property> 7 <name>hadoop.tmp.dir</name> 8 <value>/home/hadoop/hadoop-2.6.0/tmp</value> 9 </property> 10 </configuration>
上面的IP,大家换成自己的IP即可, 另外注意:临时目录如果不存在,请先手动mkdir创建一个
三、修改hdfs-site.xml
1 <configuration> 2 <property> 3 <name>dfs.datanode.ipc.address</name> 4 <value>0.0.0.0:50020</value> 5 </property> 6 <property> 7 <name>dfs.datanode.http.address</name> 8 <value>0.0.0.0:50075</value> 9 </property> 10 <property> 11 <name>dfs.replication</name> 12 <value>1</value> 13 </property> 14 </configuration>
注:如果只需要跑起来即可,只需要配置dfs.replication即可,另外二个节点,是为了方便eclipse里,hadoop-eclipse-plugin配置时,方便通过ipc.address连接,http.address则是为了方便通过浏览器查看datanode
四、修改mapred-site.xml
伪分布模式下,这个可以不用配置
五、修改yarn-site.xml
1 <configuration> 2 <property> 3 <name>yarn.nodemanager.aux-services</name> 4 <value>mapreduce_shuffle</value> 5 </property> 6 </configuration>
可以开始测试了:
1.先格式化
bin/hdfs namenode –format
2、启动dfs、yarn
sbin/start-dfs.sh
sbin/start-yarn.sh
然后用jps查看java进程,应该能看到以下几个进程:
25361 NodeManager
24931 DataNode
25258 ResourceManager
24797 NameNode
25098 SecondaryNameNode
还可以用以下命令查看hdfs的报告:
bin/hdfs dfsadmin -report 正常情况下可以看到以下内容
Configured Capacity: 48228589568 (44.92 GB)
Present Capacity: 36589916160 (34.08 GB)
DFS Remaining: 36589867008 (34.08 GB)
DFS Used: 49152 (48 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Live datanodes (1):
Name: 127.0.0.1:50010 (localhost)
Hostname: dc191
Decommission Status : Normal
Configured Capacity: 48228589568 (44.92 GB)
DFS Used: 49152 (48 KB)
Non DFS Used: 11638673408 (10.84 GB)
DFS Remaining: 36589867008 (34.08 GB)
DFS Used%: 0.00%
DFS Remaining%: 75.87%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Tue May 05 17:42:54 CST 2015
3、web管理界面查看
http://localhost:50070/
http://localhost:8088/
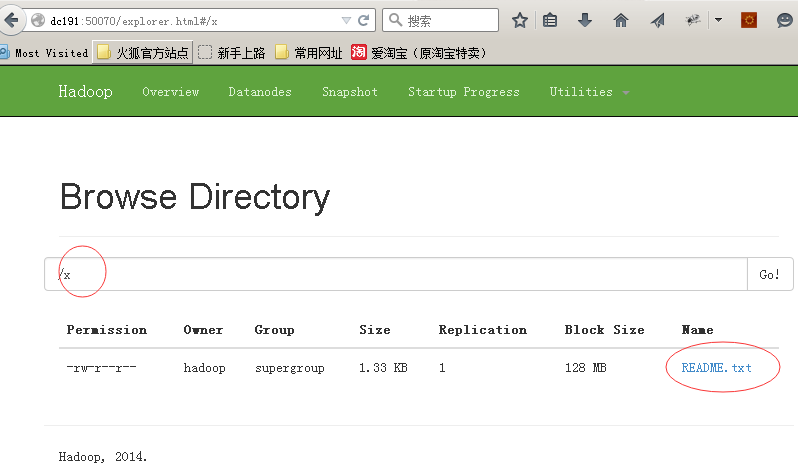
4、在hdfs中创建目录
bin/hdfs dfs -mkdir /x
这样就在hdfs中创建了一个目录x
5、向hdfs中放入文件
bin/hdfs dfs -put README.txt /x
上面的命令会把当前目录下的README.TXT放入hdfs的/x目录中,在web管理界面里也可以看到该文件
参考文档:Hadoop MapReduce Next Generation - Setting up a Single Node Cluster.