前提:
kafka集群依赖于zk集群,没有zk集群环境的请先参考 http://www.cnblogs.com/yjmyzz/p/4587663.html .
假设搭建3个节点的kafka集群,下面是步骤:
一、下载
http://kafka.apache.org/downloads ,如果只是安装,直接down kafka_2.12-0.11.0.0.tgz 即可。
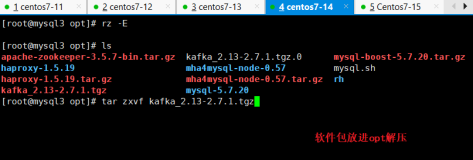
二、解压
假设$KAFKA_HOME为解压后的根目录,将tag包解压到该目录下(3台机器上都解压)
三、修改$KAFKA_HOME/config/service.properties
内容参考下面:
1 broker.id=1 #类似zk的myid一样,每个节点上的id都要唯一 2 host.name=192.168.29.60 #每个节点对应的机器IP 3 num.network.threads=3 4 num.io.threads=8 5 socket.send.buffer.bytes=102400 6 socket.receive.buffer.bytes=102400 7 socket.request.max.bytes=104857600 8 log.dirs=/data/application/kafka/data #日志保存目录 9 num.partitions=1 10 num.recovery.threads.per.data.dir=1 11 offsets.topic.replication.factor=1 12 transaction.state.log.replication.factor=1 13 transaction.state.log.min.isr=1 14 log.retention.hours=168 15 message.max.byte=5242880 16 default.replication.factor=2 17 replica.fetch.max.bytes=5242880 18 log.segment.bytes=1073741824 19 log.retention.check.interval.ms=300000 20 zookeeper.connect=192.168.29.11:2181,192.168.29.12:2181,192.168.29.13:2181 #zk集群的地址 21 zookeeper.connection.timeout.ms=6000 22 group.initial.rebalance.delay.ms=0
注:每台机器上都要修改这个文件,而且broker.id,host.name这二个很关键,弄错了将启动失败。
四、启动
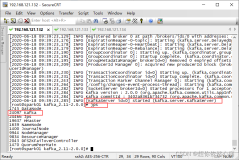
$KAFKA_HOME/bin/kafka-server-start.sh -daemon ../config/server.properties
(3台节点都要启动)
注:初次启动,可不加用-daemon参数,方便直接在控制台查看输出,启动成功后,可ctrl+C结束掉,再加-daemon后台启动。
五、验证
5.1 创建topic
$KAFKA_HOME/bin/kafka-topics.sh --create --zookeeper 192.168.29.11:2181 --replication-factor 2 --partitions 1 --topic mytopic
5.2 测试消息发布
$KAFKA_HOME/bin/kafka-console-producer.sh --broker-list 192.168.29.60:9092 --topic mytopic
这个命令会进入一个>提示符的终端,直接输入消息内容,回车就发出去了。
5.3 测试消息接收
保持5.2的窗口不要关,再加一个终端窗口
$KAFKA_HOME/bin/kafka-console-consumer.sh --zookeeper 192.168.29.11:2181 --topic mytopic --from-beginning
在刚才5.2的窗口里,输入些内容,顺利的话,消息接收窗口里,就能收到消息。
参考文章: