HDinsight Storm概述
什么是Storm?
Apache Storm是一个分布式,容错,开放源码的计算系统,让你来处理数据的实时。Storm解决方案还可以提供有保证的处理的数据,与重试未成功处理的第一次数据的能力。
什么是Azure HDInsight Storm?
HDInsightStorm被提供作为一个管理的集群集成到Azure环境,在那里它可以被用来作为一个更大的Azure溶液的一部分。例如,Storm可能会使用来自服务,如ServiceBus队列或事件中心,和使用网站或云服务的数据来提供数据可视化。 HDInsightStorm集群也可以在一个Azure虚拟网络,从而降低了延迟与其他通信资源相同的虚拟网络上,也可以允许在私人数据中心的资源安全的通信配置。
要使用Storm开始,请参阅入门Storm在HDInsight。
如何在HDInsightStorm数据处理?
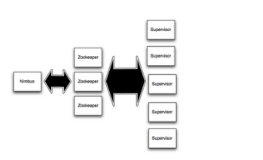
Storm集群拓扑的过程,而不是MapReduce工作,你可能很熟悉,从HDInsight或Hadoop的。Storm集群包含两种类型的节点,首节点运行Nimbus和工作节点的运行主管
• Nimbus - 类似于JobTracker的Hadoop中,它负责整个集群分发代码,将任务分配给机器,和监测故障。 HDInsight提供了两个雨云的节点,所以没有单点故障的集群Storm
• Supervisor管理程序 -监督员对每个工作节点负责启动和节点上停止工作进程
• 工作进程 - 一个工作进程运行的拓扑结构的一个子集。正在运行的拓扑结构分布在许多工作进程整个集群。
• 拓扑 - 定义计算的曲线图,其处理数据的流。与MapReduce工作,拓扑结构运行,直到你停止他们
• Streaming流 - 元组的绑定集合。流通过spouts 和bolts产生,并且通过bolts消耗
• Tuple元组 - 动态类型值的命名名单
• Spout - 从数据源耗用数据并发射一个或多个流
注意:
在很多情况下,数据被从一个队列如卡夫卡,AzureServiceBus队列或事件集线器读取。队列确保数据被持久在发生停电。
• Bolt - 消费流,对元组进行处理,并且可以发射流。Bolt还负责将数据写入到外部存储,如队列,HDInsight HBase的,一个blob,或其他数据存储
• Thrift - Apache Thrift 是可伸缩的跨语言服务开发一个软件框架。它允许你建立一个C ++,Java和Python和PHP,Ruby ,Erlang,Perl,Haskell,C#,Cocoa,JavaScript,Node.js,Smalltalk和其他语言之间的工作服务。
◦Nimbus是一个Thrift 的服务,并且一个拓扑是Thrift 的定义,所以,可以利用各种编程语言来开发拓扑
有关Storm组件的详细信息,请参阅Storm教程在apache.org。
场景:什么是用例Storm?
以下是你可能会使用Apache Storm的一些常见情况。对于真实世界的场景信息,请阅读公司如何使用Storm。
实时分析
因为Storm处理数据流中的实时,它是理想的数据分析涉及寻找和反应,在数据流的特定事件或模式,因为它们到达。例如,一个Storm拓扑可能监视传感器的数据以确定系统运行状况,并生成SMS消息时的特定模式出现提醒您。
提取转换加载(ETL)
ETL可以被认为几乎为Storm的处理的副作用。例如,如果你是通过实时分析进行欺诈检测,你摄入并已转换数据。你可能希望也有一个bolt存储在HBase的,Hive,或其他数据存储中的数据在未来的分析中使用。
分布式RPC
分布式RPC是可以使用Storm创建的图案。的请求被传递到Storm,然后跨多个节点分发的计算,最后返回一个结果流,以等待客户端。
对于分布式RPC和更多的信息提供Storm DRPCClient,请参阅分布式RPC。
在线学习机
Storm可以使用与先前已训练的批量处理,诸如基于Mahout的解决方案机器学习解决方案。但是它的通用,分布式计算模型也开启了大门基于流的机器学习的解决方案。例如,该可扩展的高级的大量在线分析(SAMOA)项目是使用流处理,并且可以与Storm工作机器学习库。
我可以使用什么编程语言?
在HDInsightStorm集群提供了.NET,Java和Python的支持开箱即用。而Storm支持其他语言,许多这些都需要你除了其他配置更改的HDInsight群集上安装额外的编程语言。
.NET
SCP是一个项目,使.NET开发人员能够设计和实施的拓扑结构(包括spouts和bolts)。支持SCP默认情况下,与HDInsightStorm集群提供。
有关使用SCP开发的更多信息,请参阅开发对Storm在HDInsight流与SCP.NET和C#的数据处理应用。
Java
你遇到的大多数的Java例子是plain Java或Trident。Trident是一种高层次的抽象,使得它更容易做的事情,如连接,聚合,分组和过滤。然而,Trident作用于元组,其中原始的Java解决方案将处理流中的一个元组在同一时间的批次。
有关Trident的更多信息,请参见教程Trident在apache.org。
对于这两种原料Java和Trident拓扑的示例,请参阅%storm_home%\contrib\Storm启动您的HDInsightStorm群集上目录。
什么是一些常见的发展模式?
保证邮件处理
Storm可以提供不同层次的有保证的消息处理。例如,一个基本的Storm应用可以保证在最少一次处理,同时三叉戟可以保证仅一次处理。
欲了解更多信息,请参阅数据处理担保在apache.org
BasicBolt
读取输入的元组,发射零个或多个元组,然后在执行方法的末尾立即ACKING输入元组的格局,是如此普遍,Storm提供了IBasicBolt接口来自动完成这个模式。
联接Joins
接合两个数据流将应用之间有所不同。例如,您可以加入多个流中的每个元组到一个新的数据流,或者你可能只参加元组批特定的窗口。无论哪种方式,接合可以通过使用fieldsGrouping,这是定义如何元组路由到螺栓的方法来实现。
在下面的Java示例,fieldsGrouping用于路由元组从组件“1”始发,“2”,“3”,以MyJoiner bolt。
builder.setBolt("join", new MyJoiner(), parallelism) .fieldsGrouping("1", new Fields("joinfield1", "joinfield2")) .fieldsGrouping("2", new Fields("joinfield1", "joinfield2")) .fieldsGrouping("3", new Fields("joinfield1", "joinfield2"));
批处理
批处理可实现几种方法。一个基本的JavaStorm拓扑结构,可以使用简单的计数器来元组的批量X数量发射之前,或使用被称为打勾tick元组的内部定时机制,发出的每一批X秒。
对于使用打勾tick元组的一个例子,看到Storm和HDInsight分析传感器数据
如果您使用的Trident,它是基于处理的元组的批次。
缓存
内存中的高速缓存通常被用作一种机制,用于加快处理,因为它使经常使用的资产在存储器中。由于拓扑结构分布在多个节点,多个进程的每个节点中,您应该考虑使用fieldsGrouping以确保包含了用于高速缓存查找的字段元组始终路由到相同的过程。这就避免了跨进程缓存条目的重复。
Streaming最前N个
当你的拓扑取决于计算'顶'N值,如前5名的趋势在Twitter上,你应该并行计算的前N值,然后合并从这些计算的输出成为一个全球性的价值。这可以通过使用fieldsGrouping路由来完成由字段向平行的bolts,其通过字段值,然后最终路由至一个bolt,全球确定顶端N值划分的数据。
对于这样的一个例子,请参见RollingTopWords例子。
接下来的步骤
• 制定关于Storm在HDInsight流与SCP.NET和C#的数据处理应用
本文翻译自Windows Azure官网:http://azure.microsoft.com/en-us/documentation/articles/hdinsight-storm-overview/
转载请注明出处:http://blog.csdn.net/yangzhenping, 谢谢!