分区概述:
1、范围分区:范围分区(range partitioning)依据用户创建分区时设定的分区键值(partition key value)范围将数据映射到不同分区。范围分区是较常用的分区方式,通常针对日期数据使用。例如,用户可以将销售数据按月存储到相应的分区中。 在采用范围分区时,应注意以下规则:
- 定义分区时必须使用 VALUES LESS THAN 子句定义分区的开区间上限(noninclusive upper bound)。分区键大于等于此修饰符(literal)的数据将被存储到下一个分区中。
- 除了第一个分区之外,其他所有分区都有一个隐式的下限(lower bound),此下限是由上一个分区的 VALUES LESS THAN 子句指定的。
- 用户可以为最大分区定义一个 MAXVALUE 修饰符。MAXVALUE 代表一个无穷大值,用于识别大于所有可能分区键的数据(包括 null)。
CREATE TABLE sales_range (
salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
sales_date DATE)
PARTITION BY RANGE(sales_date)(
PARTITION sales_jan2000 VALUES LESS THAN(TO_DATE('02/01/2000','MM/DD/YYYY')),
PARTITION sales_feb2000 VALUES LESS THAN(TO_DATE('03/01/2000','MM/DD/YYYY')),
PARTITION sales_mar2000 VALUES LESS THAN(TO_DATE('04/01/2000','MM/DD/YYYY')),
PARTITION sales_apr2000 VALUES LESS THAN(TO_DATE('05/01/2000','MM/DD/YYYY'))
);
很容易理解的哦,哈哈。。
2、列表分区:用户可以采用列表分区(list partitioning)显示地控制如何将数据行映射到各个分区。用户在各分区的定义中指定一个分区键(partitioning key)离散值的列表,从而实现列表分区。列表分区与范围分区(range partitioning)有所不同,在范围分区中是为每个分区设定一个分区键值的范围;列表分区与哈希分区也有区别,哈希分区是通过一个哈希函数(hash function)控制数据行与分区间的映射关系。用户可以采用列表分区,将无序(unordered)或互不相关(unrelated)的数据进行分组整理。
来看个列表分区的例子:
CREATE TABLE sales_list(
salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_state VARCHAR2(20),
sales_amount NUMBER(10),
sales_date DATE)
PARTITION BY LIST(sales_state)(
PARTITION sales_west VALUES('California', 'Hawaii'),
PARTITION sales_east VALUES ('New York', 'Virginia', 'Florida'),
PARTITION sales_central VALUES('Texas', 'Illinois'),
PARTITION sales_other VALUES(DEFAULT)
);
在将数据行映射到分区的过程中,Oracle 检查数据行的分区键值是否包含于某分区定义的值列中。以下面的数据为例:
- (10,'Jones','Hawaii',100,'05-JAN-2000') 映射到 sales_west 分区
- (21,'Smith','Florida',150,'15-JAN-2000') 映射到 sales_east 分区
- (32,'Lee','Colorado',130,'21-JAN-2000') 映射到 sales_other 分区
3、哈希分区:用户可以采用哈希分区(hash partitioning)将不适于采用范围分区(range partitioning)或列表分区(list partitioning)的数据进行分区。哈希分区的语法(syntax)简单且易于实现。在以下情况时哈希分区比范围分区更适用:
- 用户无法事先确定一个分区可能存储的数据量
- 各范围分区的容量可能相差很大,或很难通过人工进行平衡
- 采用范围分区可能导致数据不正常的集中
- 应用系统对并行 DML(parallel DML),分区剪除(partition pruning),及基于分区的关联(partition-wise joins)等与性能有关的分区特性要求较高
CREATE TABLE sales_hash(
salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
week_no NUMBER(2))
PARTITION BY HASH(salesman_id)
PARTITIONS 4
STORE IN (ts1, ts2, ts3, ts4);
上述语句创建了依据 salesman_id 字段进行哈希分区(hash partitioning)的分区表sales_hash。此表使用的表空间分别为 ts1,ts2,ts3,及 ts4。上述语句表明,将数据以循环(round-robin)的方式存储到语句中指定的各个表空间中。
4、复合分区:复合分区(composite partitioning)首先根据范围(range)进行分区,再使用哈希或列表方式创建子分区。复合范围-哈希分区既能够发挥范围分区的可管理性优势,也能够发挥哈希分区的数据分布(data placement),条带化(striping),及并行化(parallelism)优势。复合范围-列表分区能够发挥范围分区的可管理性优势,也能利用列表分区的显示控制能力。复合分区(composite partitioning)便于用户进行与时间相关的维护操作(historical operation),例如添加新的范围分区等。同时复合分区还能够利用子分区(subpartitioning)实现高度的并行 DML 操作,并对数据分布进行精细的控制。
CREATE TABLE sales_composite (
salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
sales_date DATE)
PARTITION BY RANGE(sales_date)
SUBPARTITION BY HASH(salesman_id)
SUBPARTITION TEMPLATE(
SUBPARTITION sp1 TABLESPACE ts1,
SUBPARTITION sp2 TABLESPACE ts2,
SUBPARTITION sp3 TABLESPACE ts3,
SUBPARTITION sp4 TABLESPACE ts4)
(PARTITION sales_jan2000 VALUES LESS THAN(TO_DATE('02/01/2000','MM/DD/YYYY'))
PARTITION sales_feb2000 VALUES LESS THAN(TO_DATE('03/01/2000','MM/DD/YYYY'))
PARTITION sales_mar2000 VALUES LESS THAN(TO_DATE('04/01/2000','MM/DD/YYYY'))
PARTITION sales_apr2000 VALUES LESS THAN(TO_DATE('05/01/2000','MM/DD/YYYY'))
PARTITION sales_may2000 VALUES LESS THAN(TO_DATE('06/01/2000','MM/DD/YYYY')));
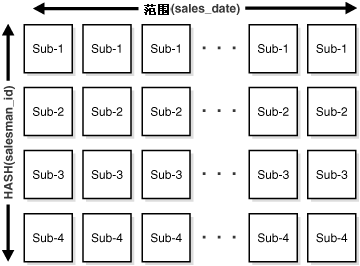
上述语句创建了 sales_composite 表,首先依据 sales_date 字段创建范围分区(range partitioned),再依据 salesman_id 字段创建哈希子分区。如果用户在语句中使用了模板(template),Oracle 命名子分区的模式为“分区名”加“下划线”再加模板中设定的“子分区名”。同样,Oracle 将子分区存储在模板中指定的表空间中。在上述语句中,子分区 sales_jan2000_sp1 存储在表空间 ts1 中,而子分区 sales_jan2000_sp4 存储在表空间 ts4 中。同样,子分区 sales_apr2000_sp1 存储在表空间 ts1 中,而子分区sales_apr2000_sp4 存储在表空间 ts4 中。图 18-4 为上述语句的图形化描述。图 18-4 复合范围-哈希分区
CREATE TABLE bimonthly_regional_sales(
deptno NUMBER,
item_no VARCHAR2(20),
txn_date DATE,
txn_amount NUMBER,
state VARCHAR2(2))
PARTITION BY RANGE (txn_date)
SUBPARTITION BY LIST (state)
SUBPARTITION TEMPLATE(
SUBPARTITION east VALUES('NY', 'VA', 'FL') TABLESPACE ts1,
SUBPARTITION west VALUES('CA', 'OR', 'HI') TABLESPACE ts2,
SUBPARTITION central VALUES('IL', 'TX', 'MO') TABLESPACE ts3)
(
PARTITION janfeb_2000 VALUES LESS THAN (TO_DATE('1-MAR-2000','DD-MON-YYYY')),
PARTITION marapr_2000 VALUES LESS THAN (TO_DATE('1-MAY-2000','DD-MON-YYYY')),
PARTITION mayjun_2000 VALUES LESS THAN (TO_DATE('1-JUL-2000','DD-MON-YYYY'))
);
上述语句创建了 bimonthly_regional_sales 表,首先依据 txn_date 字段创建范围分区(range partitioned),再依据 state 字段创建子分区。如果用户在语句中使用了模板(template),Oracle 命名子分区的模式为“分区名”加“下划线”再加模板中设定的“子分区名”。同样,Oracle 将子分区存储在模板中指定的表空间中。在上述语句中,子分区 janfeb_2000_east 存储在表空间 ts1 中,而子分区 janfeb_2000_central 存储在表空间 ts3 中。同样,子分区 mayjun_2000_east 存储在表空间 ts1 中,而子分区mayjun_2000_central 存储在表空间 ts3 中。图 18-5 显示了表bimonthly_regional_sales 的 9 个子分区。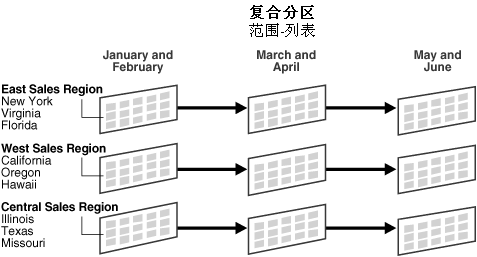
以下是关于何时应该对表进行分区的一些建议:
- 如果表数据量超过 2GB,就应该考虑进行分区。
- 如果表中包含历史数据,且新数据会被添加到最新的表空间中。典型的例子是一种历史表,其中只有当前月份的数据可以被修改,而其他十一个月的数据为只读。
与分区表类似(partitioned table),分区索引(partitioned index)也能够提高系统的可管理性,可用性,可伸缩性,及系统性能。分区索引既可以与分区表相对独立(全局索引(global index)),也可以采用与分区表相同的分区方式(本地索引(local index))。一般来说,OLTP 系统适合采用全局索引,而数据仓库系统或 DSS 系统适合采用本地索引。此外,用户应尽可能地使用本地索引,因为此种索引更易管理。在选择索引类型时,可以参考以下经验:
- 如果表的分区键(partitioning column)是索引键(index key)的子集,应使用本地索引。否则继续参考经验 2。
- 如果索引为唯一索引(unique),应使用全局索引。否则继续参考经验 3。
- 如果用户对可管理性的要求更高,应使用本地索引。否则继续参考经验 4。
- 如果应用系统为 OLTP,且对系统的响应时间要求较高,应使用全局索引。如果应用系统为 DSS,且对系统的数据吞吐量要求较高,应使用本地索引。
本地分区索引(local partitioned index)与其他类型分区索引相比较更易管理。本地分区索引适用于 DSS 系统,且具有较高的可用性。这是因为本地分区索引与其所在的分区表采用相同的分区方式:本地分区索引的每个分区都与分区表的一个分区相对应。因此,Oracle 能够自动地确保各个索引分区与相应的表分区同步,且使各个表-索引分区对(table-index pair)相互独立。当一个表分区内的数据发生变化时,只会影响一个索引分区。
当对表的分区及子分区进行维护操作时,本地分区索引与全局索引相比具备更高的可用性。有一种索引被称为本地非前缀分区索引(local nonprefixed index)非常适合用于存取历史数据。此类索引的特点是,不对索引键的左前缀进行分区。
2、全局分区索引:
Oracle 支持两种全局分区索引(global partitioned index):范围(range)分区索引,哈希(hash)分区索引。
全局范围分区索引:
(global range partitioned index)的灵活性在于其分区度(degree of partitioning)及分区键(partitioning key )都可以和表的分区方法相独立。此类索引主要用于 OLTP 系统,在存取独立记录时效率较高。
全局范围分区索引(global range partitioned index)的灵活性在于其分区度(degree of partitioning)及分区键(partitioning key )都可以和表的分区方法相独立。此类索引主要用于 OLTP 系统,在存取独立记录时效率较高。
用户不能向全局范围分区索引中添加分区,因为最后一个分区总是以 MAXVALUE 作为分区边界。如果用户需要添加最高分区,应使用 ALTER INDEX SPLIT PARTITION 语句。如果一个全局索引的某分区已空,用户可以使用 ALTER INDEX DROP PARTITION 显示地将其移除。如果全局索引的某个分区内含有数据,移除此分区将导致下一个分区被标识为不可用。用户不能移除全局索引中的最后一个分区。
在一般情况下,对全局索引所在的堆表(heap-organized table)进行以下操作将导致索引被标识为不可用:
全局哈希索引:
对于索引值单调增长的表,创建全局哈希分区索引(lobal hash partitioned index)有助于索引数据分布,从而提升系统性能。索引值单调增长指新索引数据只会在索引的右边界插入。
全局分区索引的维护:
用户可以在上述操作的 SQL 语句后添加 UPDATE INDEXES 子句,以便维护全局分区索引。这样对索引进行维护的好处有两个:ADD (HASH)
COALESCE (HASH)
DROP
EXCHANGE
MERGE
MOVE
SPLIT
TRUNCATE
- 在操作期间索引依然有效。因此其他应用程序不会受相关操作的影响。
- 在操作结束后索引不必重建。
3、 全局非分区索引:
全局非分区索引(global nonpartitioned index)与普通的非分区索引类似。此类索引主要用于 OLTP 系统,在存取独立记录时效率较高。图 18-8 展示了全局非分区索引。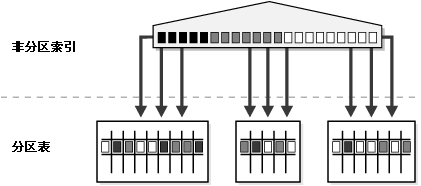
图 18-8 显示了全局非分区索引可以指向分区表的不同分区。
4 在分区表上创建索引的其他知识:
用户可以在分区表上创建位图索引(bitmap index),但必须是本地分区索引(local partitioned index),而不能是全局索引(global index)。全局索引(global index)可以是唯一的。如果分区键是索引键的子集,本地索引只能是唯一的。
5 在 OLTP 系统中使用分区索引
以下是在 OLTP 系统中使用分区索引的一些指导建议:
- 全局分区索引(global partitioned index)及唯一本地分区索引(unique local partitioned index)与非唯一本地分区索引(nonunique local partitioned index)相比能够提供更好的性能。前两者能够最小化需要被检索的索引分区。
- 在对表的分区或子分区进行维护时,本地分区索引具备更高的可用性。
- 全局哈希分区索引(global hash-partitioned index)在索引值单调增长的情况下能够 均匀分布索引数据,从而提升系统性能。索引值单调增长指新索引数据只会插入到索引的右边界外
6 在数据仓库及 DDS 系统中使用分区索引
以下是在数据仓库系统及 DSS 系统中使用分区索引的一些指导建议:- 应尽可能地使用本地分区索引(local partitioned index),因为此类索引在数据加载过程中及进行分区维护操作时更易管理(data load)
- 本地分区索引有助于提升系统性能,因为对一个范围内的索引键进行查询时,可以并行地扫描多个分区。
7 复合分区上的分区索引
以下是关于在复合分区(composite partition)上创建分区索引(partitioned index)的一些建议:- 子分区索引(subpartitioned index)必须是本地的,且默认与表的子分区存储在一起。
- 用户既可以为整个索引设定表空间,也可以分别为索引子分区设定表空间。
更多参考:http://blog.csdn.net/changyanmanman/article/details/8246519
