Oracle 数据库中优化器(Optimizer)是SQL分析和执行的优化工具,它负责指定SQL的执行计划,也就是它负责保证SQL执行的效率最高,比如优化器决定Oracle 以什么样的方式来访问数据,是全表扫描(Full Table Scan),索引范围扫描(Index Range Scan)还是全索引快速扫描(INDEX Fast Full Scan:INDEX_FFS);对于表关联查询,它负责确定表之间以一种什么方式来关联,比如HASH_JOHN还是NESTED LOOPS 或者MERGE JOIN。 这些因素直接决定SQL的执行效率,所以优化器是SQL 执行的核心,它做出的执行计划好坏,直接决定着SQL的执行效率。
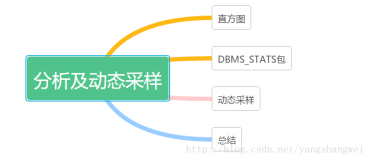
CBO(Cost Based Optimizer)是一种比RBO 更理性化的优化器。从10g开始,Oracle 已经彻底丢弃了RBO。 即使在表,索引没有被分析的时候,Oracle依然会使用CBO。此时,Oracle会使用一种叫做动态采样的技术,在分析SQL的时候,动态的收集表,索引上的一些数据块,使用这些数据块的信息及字典表中关于这些对象的信息来计算出执行计划的代价,从而挑出最优的执行计划。是CBO存在的基石,CBO的机制就是收集尽可能多的对象信息和系统信息,通过对这些信息进行计算,分析,评估,最终得出一个成本最低的执行计划。 所以对于CBO,数据段的分析就非常重要。
当表没有做分析的时候,Oracle 会使用动态采样来收集统计信息,这个动作只有在SQL执行的第一次,即硬分析阶段使用,后续的软分析将不在使用动态采样,直接使用第一次SQL 硬分析时生成的执行计划。
参考dave的博客,建立演示实例,跟着思路分析:
1.1创建表
SQL> create table t as select object_id,object_name from dba_objects where 1=2;
表已创建。
SQL> create index index_t on t(object_id);
索引已创建。
SQL> insert into t select object_id,object_name from dba_objects;
已创建72926行。
SQL> commit;
提交完成。
1.2查看分的分析及执行计划
SQL> select num_rows,avg_row_len,blocks,last_analyzed from user_tables where table_name='T';
NUM_ROWS AVG_ROW_LEN BLOCKS LAST_ANALYZED
---------- ----------- ---------- --------------
SQL> select blevel,leaf_blocks,distinct_keys,last_analyzed from user_indexes where table_name='T';
BLEVEL LEAF_BLOCKS DISTINCT_KEYS LAST_ANALYZED
---------- ----------- ------------- --------------
0 0 0 25-8月 -10
从查询结果看出,表的行数,行长,占用的数据块数及最后的分析时间都是空。 索引的相关信息也没有,说明这个表和索引都没有被分析,如果此时有一条SQL对表做查询,CBO 由于无法获取这些信息,很可能生成错误的执行计划,如:
SQL> set linesize 200
SQL> set autot trace exp;
SQL> select /*+dynamic_sampling(t 0) */ * from t where object_id>30;
执行计划
----------------------------------------------------------
Plan hash value: 80339723
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 316 | 0 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T | 4 | 316 | 0 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | INDEX_T | 1 | | 0 (0)| 00:00:01 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID">30)
SQL>
在Oracle 10g以后,如果一个表没有做分析,数据库将自动对它做动态采样分析,所以这里采用hint的方式将动态采样的级别设置为0,即不使用动态采样。从这个执行计划,看书CBO 估计出表中满足条件的记录为4条,索引使用了索引。 我们对表做一下分析,用结果比较一下。
1.3 分析表及查看分析之后的执行计划
分析可以通过两中方式:
一种是analyze 命令,如:
analyze table tablename compute statistics for all indexes;
还有一种就是通过DBMS_STATS包来分析,从9i 开始,Oracle 推荐使用DBMS_STATS包对表进行分析操作,因为DBMS_STATS 提供了更多的功能,以及灵活的操作方式。
SQL> exec dbms_stats.gather_table_stats('SYS','T');
PL/SQL 过程已成功完成。
SQL> select blevel,leaf_blocks,distinct_keys,last_analyzed from user_indexes where table_name='T';
BLEVEL LEAF_BLOCKS DISTINCT_KEYS LAST_ANALYZED
---------- ----------- ------------- --------------
1 263 72926 25-8月 -10
SQL> select num_rows,avg_row_len,blocks,last_analyzed from user_tables where table_name='T';
NUM_ROWS AVG_ROW_LEN BLOCKS LAST_ANALYZED
---------- ----------- ---------- --------------
72926 29 345 25-8月 -10
从上面的结果,可以看出DBMS_STATS.gather_table_stats已经对表和索引都做了分析。 现在我们在来看一下执行计划。
SQL> set autot trace exp;
SQL> select * from t where object_id>30;
执行计划
----------------------------------------------------------
Plan hash value: 1601196873
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 72899 | 2064K| 96 (2)| 00:00:02 |
|* 1 | TABLE ACCESS FULL| T | 72899 | 2064K| 96 (2)| 00:00:02 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
--------------------------------------------------
1 - filter("OBJECT_ID">30)
从这个计划,我们看出CBO 估算出的结果是72899 条记录,与实际的72926很近。 此时选择全表扫描更优。 通过这个例子,我们也看出了分析对执行计划的重要性。
DBMS_STATS 包对段表的分析有三个层次:
(1)表自身的分析: 包括表中的行数,数据块数,行长等信息。
(2)列的分析: 包括列值的重复数,列上的空值,数据在列上的分布情况。
(3)索引的分析: 包括索引叶块的数量,索引的深度,索引的聚合因子等。
直方图就是 列分析中 数据在列上的分布情况。当Oracle 做直方图分析时,会将要分析的列上的数据分成很多数量相同的部分,每一部分称为一个bucket,这样CBO就可以非常容易地知道这个列上的数的分布情况,这种数据的分布将作为一个非常重要的因素纳入到执行计划成本的计算当中。
对于数据分布非常倾斜的表,做直方图是非常有用的。 如: 1,10,20,30,40,50. 那么在一个数值范围(bucket)内,它的数据记录基本上一样。 如果是:1,5,5,5,5,10,10,20,50,100. 那么它在bucket内,数据分布就是严重的倾斜。
直方图有时对于CBO非常重要,特别是对于有字段数据非常倾斜的表,做直方图分析尤为重要。 可以用dbms_stats包来分析。 默认情况下,dbms_stats包会对所有的列做直方图分析。 如:
SQL> exec dbms_stats.gather_table_stats('SYS','T',cascade=>true);
PL/SQL 过程已成功完成。
然后从user_histograms视图上查看到相关的信息:
SQL> select table_name,column_name,endpoint_number,endpoint_value from user_histograms where table_name='T';
TABLE_NAME COLUMN_NAME ENDPOINT_NUMBER ENDPOINT_VALUE
------------------------------ -------------------- --------------- --------------
T OBJECT_ID 0 2
T OBJECT_NAME 0 2.4504E+35
T OBJECT_ID 1 76685
T OBJECT_NAME 1 1.0886E+36
如果一个列上的数据有比较严重的倾斜,对这个列做直方图是必要的,但是,Oracle 对数据分析是需要消耗资源的,特别是对于一些很大的段对象,分析的时间尤其长。对于OLAP系统,可能需要几个小时才能完成。
所以做不做分析就需要DBA 权衡好了。 但有一点要注意, 不要在生产环境中随便修改分析方案,除非你有十足的把握。 否则可能导致非常严重的后果。
关于如何看懂oracle的直方图信息,参考博客: http://blog.csdn.net/cymm_liu/article/details/8582112