蜻蜓,通过解决大规模文件下载以及跨网络隔离等场景下各种难题,大幅提高数据预热、大规模容器镜像分发等业务能力。月均分发次数突破20亿次,分发数据量3.4PB。其中容器镜像分发比natvie方式提速可高达57倍,registry网络出口流量降低99.5%以上。今天,阿里妹邀请阿里基础架构事业群高级技术专家如柏,为我们详述蜻蜓从文件分发到镜像传输的技术之路。
蜻蜓的诞生
随着阿里业务爆炸式增长,2015年时发布系统日均的发布量突破两万,很多应用的规模开始破万,发布失败率开始增高,而根本原因就是发布过程需要大量的文件拉取,文件服务器扛不住大量的请求,当然很容易想到服务器扩容,可是扩容后又发现后端存储成为瓶颈。此外,大量来自不同IDC的客户端请求消耗了巨大的网络带宽,造成网络拥堵。
同时,很多业务走向国际化,大量的应用部署在海外,海外服务器下载要回源国内,浪费了大量的国际带宽,而且还很慢;如果传输大文件,网络环境差,失败的话又得重来一遍,效率极低。
于是很自然的就想到了P2P技术,因为P2P技术并不新鲜,当时也调研了很多国内外的系统,但是调研的结论是这些系统的规模和稳定性都无法达到我们的期望。所以就有了蜻蜓这个产品。
设计目标
针对这些痛点,蜻蜓在设计之初定了几个目标:
- 解决文件源被打爆的问题,在Host之间组P2P网,缓解文件服务器压力,节约跨IDC之间的网络带宽资源。
- 加速文件分发速度,并且保证上万服务器同时下载,跟一台服务器下载没有太大的波动。
- 解决跨国下载加速和带宽节约。
- 解决大文件下载问题,同时必须要支持断点续传。
- Host上的磁盘IO,网络IO必须可以被控制,以避免对业务造成影响。
系统架构
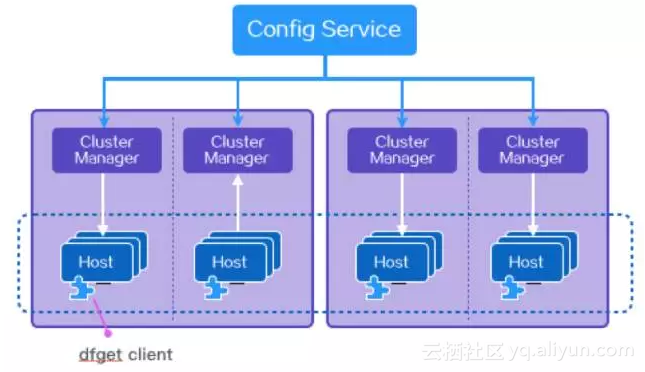
蜻蜓整体架构
蜻蜓整体架构分三层:第一层是Config Service, 他管理所有的Cluster Manager,Cluster Manager又管理所有的Host, Host就是终端,dfget就是类似wget的一个客户端程序。
Config Service 主要负责Cluster Manager的管理、客户端节点路由、系统配置管理以及预热服务等等。简单的说, 就是负责告诉Host,离他最近的一组Cluster Manager的地址列表,并定期维护和更新这份列表,使Host总能找到离他最近的Cluster Manager。
Cluster Manager 主要的职责有两个:
- 以被动CDN方式从文件源下载文件并生成一组种子分块数据;
- 构造P2P网络并调度每个peer之间互传指定的分块数据。
Host上就存放着dfget,dfget的语法跟wget非常类似。主要功能包括文件下载和P2P共享等。
在阿里内部我们可以用StarAgent来下发dfget指令,让一组机器同时下载文件,在某种场景下一组机器可能就是阿里所有的服务器,所以使用起来非常高效。除了客户端外, 蜻蜓还有Java SDK,可以让你将文件“PUSH”到一组服务器上。
下面这个图阐述了两个终端同时调用dfget,下载同一个文件时系统的交互示意图:
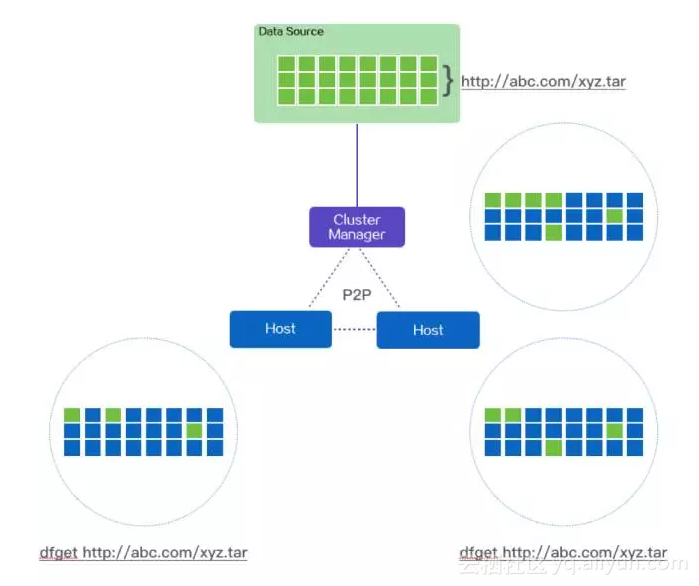
蜻蜓P2P组网逻辑示意图
两个Host和CM会组成一个P2P网络,首先CM会查看本地是否有缓存,如果没有,就会回源下载,文件当然会被分片,CM会多线程下载这些分片,同时会将下载的分片提供给Host们下载,Host下载完一个分片后,同时会提供出来给peer下载,如此类推,直到所有的Host全部下载完。
本地下载的时候会将下载分片的情况记录在metadata里,如果突然中断了下载,再次执行dfget命令,会断点续传。
下载结束后,还会比对MD5,以确保下载的文件和源文件是完全一致的。蜻蜓通过HTTP cache协议来控制CM端对文件的缓存时长,CM端当然也有自己定期清理磁盘的能力,确保有足够的空间支撑长久的服务。
在阿里还有很多文件预热的场景,需要提前把文件推送到CM端,包括容器镜像、索引文件、业务优化的cache文件等等。
在第一版上线后,我们进行了一轮测试, 结果如下图:
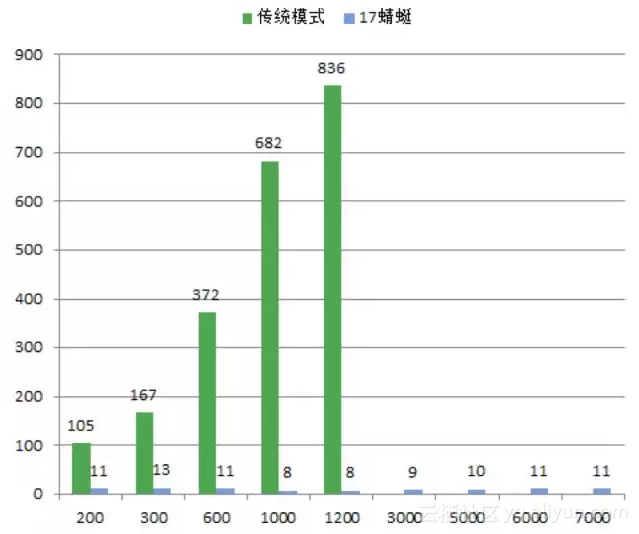
传统下载和蜻蜓P2P下载测试结果对比图
X轴是客户端数量, Y轴是下载时长,
文件源:测试目标文件200MB(网卡:千兆bit/s)
Host端:百兆bit/s网卡
CM端:2台服务器(24核 64G,网卡:千兆bit/s)
从这个图可以看出两个问题:
- 传统模式随着客户端的增加,下载时长跟着增加,而dfget可以支撑到7000客户端依然没变好。
- 传统模式到了1200客户端以后就没有数据了,因为数据源被打爆了。
从发布系统走向基础设施
2015年双11后,蜻蜓的下载次数就达到了12万/月,分发量4TB。当时在阿里还有别的下载工具,如wget,curl,scp,ftp 等等,也有自建的小规模文件分发系统。我们除了全面覆盖自身发布系统外,也做了小规模的推广。到2016年双11左右,我们的下载量就达到了1.4亿/月,分发量708TB,业务增长了近千倍。
2016年双11后我们提出了一个更高的目标, 希望阿里大规模文件分发和大文件分发90%的业务由蜻蜓来承担。
我希望通过这个目标锤炼出最好的P2P文件分发系统。此外也可以统一集团内所有的文件分发系统。统一可以让更多的用户受益,但统一从来不是终极目标, 统一的目的是:1. 减少重复建设;2. 全局优化。
只要优化蜻蜓一个系统,全集团都能受益。比如我们发现系统文件是每天全网分发的,而光这一个文件压缩的话就能给公司每天节省9TB网络流量。跨国带宽资源尤其宝贵。而如果大家各用各的分发系统,类似这样的全局优化就无从谈起。
所以统一势在必行!
在大量数据分析基础上,我们得出全集团文件分发的量大概是3.5亿次/周,而我们当时的占比只有10%不到。
经过半年努力,在2017年4月份,我们终于实现了这个目标, 达到90%+的业务占有率,业务量增长到3亿次/周(跟我们之前分析的数据基本吻合),分发量977TB,这个数字比半年前一个月的量还大。
当然,不得不说这跟阿里容器化也是密不可分的,镜像分发流量大约占了一半。下面我们就来介绍下蜻蜓是如何支持镜像分发的。在说镜像分发之前先说下阿里的容器技术。
阿里的容器技术
容器技术的优点自然不需要多介绍了,全球来看,容器技术以Docker为主占了大部分市场,当然还有其他解决方案:比如rkt,Mesos Uni Container,LXC等,而阿里的容器技术命名为Pouch。早在2011年,阿里就自主研发了基于LXC的容器技术T4,只是当时我们没有创造镜像这个概念,T4还是当做虚拟机来用,当然比虚拟机要轻量的多。
2016年阿里在T4基础上做了重大升级,演变为今天的Pouch,并且已经开源。目前Pouch容器技术已经覆盖阿里巴巴集团几乎所有的事业部,在线业务100%容器化,规模高达数十万。镜像技术的价值扩大了容器技术的应用边界,而在阿里如此庞大的应用场景下,如何实现高效“镜像分发”成为一个重大命题。
回到镜像层面。宏观上,阿里巴巴有规模庞大的容器应用场景;微观上,每个应用镜像在镜像化时,质量也存在参差不齐的情况。
理论上讲用镜像或者用传统“基线”模式,在应用大小上不应该有非常大的区别。但事实上这完全取决于Dockerfile写的好坏,也取决于镜像分层是否合理。阿里内部其实有最佳实践,但是每个团队理解接受程度不同,肯定会有用的好坏的之分。尤其在一开始,大家打出来的镜像有3~4GB这都是非常常见的。
所以作为P2P文件分发系统,蜻蜓就有了用武之地,无论是多大的镜像,无论是分发到多少机器,即使你的镜像打的非常糟糕,我们都提供非常高效的分发,都不会成瓶颈。这样就给我们快速推广容器技术,让大家接受容器运维模式,给予了充分消化的时间。
容器镜像
在讲镜像分发之前先简单介绍下容器镜像。我们看下Ubuntu系统的镜像:我们可以通过命令 docker history ubuntu:14.04 查看 ubuntu:14.04,结果如下:
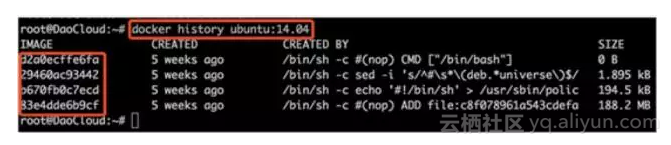
需要注意的是:镜像层 d2a0ecffe6fa 中没有任何内容,也就是所谓的空镜像。
镜像是分层的,每层都有自己的ID和尺寸,这里有4个Layer,最终这个镜像是由这些Layer组成。
Docker镜像是通过Dockerfile来构建,看一个简单的Dockerfile:

镜像构建过程如下图所示:
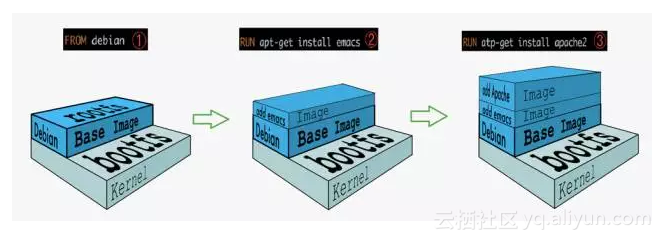
可以看到,新镜像是从 base 镜像一层一层叠加生成的。每安装一个软件,就在现有镜像的基础上增加一层。
当容器启动时,一个可写层会被加载到镜像的顶层,这个可读可写层也被称为“容器层”,容器层之下都是“镜像层”,都是只读的。
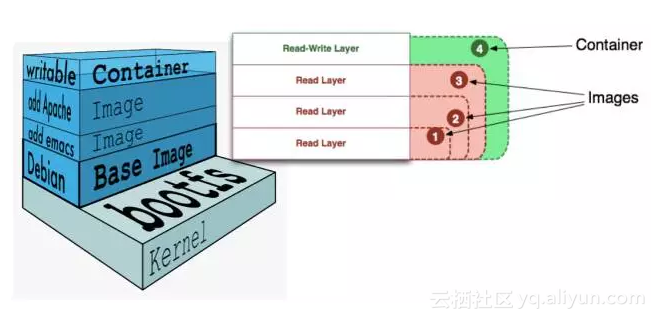
如果镜像层内容为空,相应的信息会在镜像json文件中描述,如果镜像层内容不为空,则会以文件的形式存储在OSS中。
镜像分发
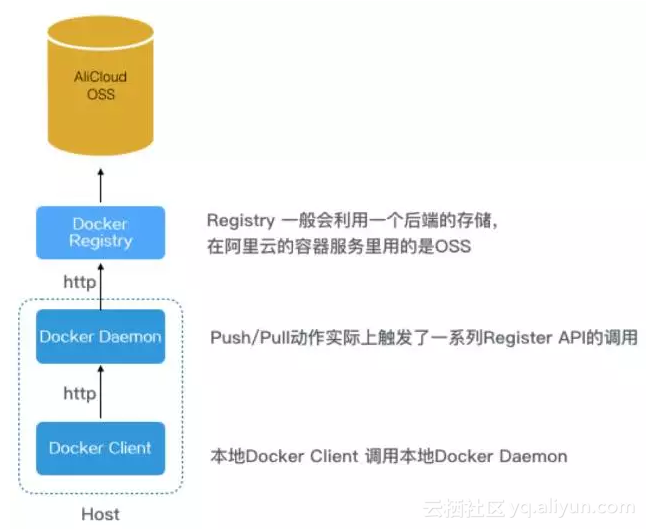
Docker 镜像下载流程图
以阿里云容器服务为例,传统的镜像传输如上图所示,当然这是最简化的一种架构模式,实际的部署情况会复杂的多,还会考虑鉴权、安全、高可用等等。
从上图可以看出,镜像传输跟文件分发有类似的问题,当有一万个Host同时向Registry请求时,Registry就会成为瓶颈,还有海外的Host访问国内Registry时候也会存在带宽浪费、延时变长、成功率下降等问题。
下面介绍下Docker Pull的执行过程:
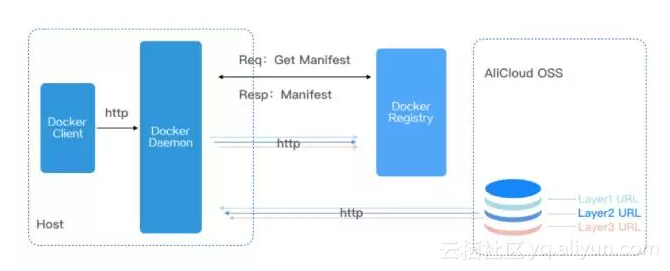
Docker 镜像分层下载图
Docker Daemon调用Registry API得到镜像的Manifest,从Manifest中能算出每层的URL,Daemon随后把所有镜像层从Registry并行下载到Host本地仓库。
所以最终,镜像传输的问题变成了各镜像层文件的并行下载的问题。而蜻蜓擅长的正是将每层镜像文件从Registry用P2P模式传输到本地仓库中。
那么具体又是如何做到的呢?
事实上我们会在Host上启动dfGet proxy,Docker/Pouch Engine的所有命令请求都会通过这个proxy,我们看下图:
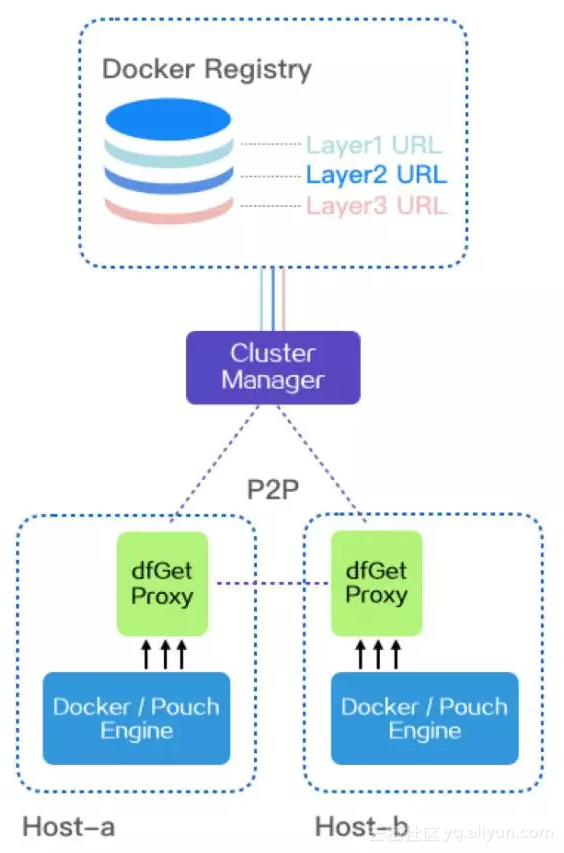
蜻蜓P2P容器镜像分发示意图
首先,docker pull命令,会被dfget proxy截获。然后,由dfget proxy向CM发送调度请求,CM在收到请求后会检查对应的下载文件是否已经被缓存到本地,如果没有被缓存,则会从Registry中下载对应的文件,并生成种子分块数据(种子分块数据一旦生成就可以立即被使用);如果已经被缓存,则直接生成分块任务,请求者解析相应的分块任务,并从其他peer或者supernode中下载分块数据,当某个Layer的所有分块下载完成后,一个Layer也就下载完毕了,同样,当所有的Layer下载完成后,整个镜像也就下载完成了。
蜻蜓支持容器镜像分发,也有几个设计目标:
- 大规模并发:必须能支持十万级规模同时Pull镜像。
- 不侵入容器技术内核(Docker Daemon, Registry):也就是说不能改动容器服务任何代码。
- 支持Docker,Pouch,Rocket ,Hyper等所有容器/虚拟机技术。
- 支持镜像预热:构建时就推送到蜻蜓集群CM。
- 支持大镜像文件:至少30GB。
- 安全
Native Docker V.S 蜻蜓
我们一共做了两组实验:
实验一:1个客户端
- 测试镜像大小:50MB、200MB、500MB、1GB、5GB
- 镜像仓库带宽:15Gbps
- 客户端带宽:双百兆bit/s网络环境
- 测试规模:单次下载
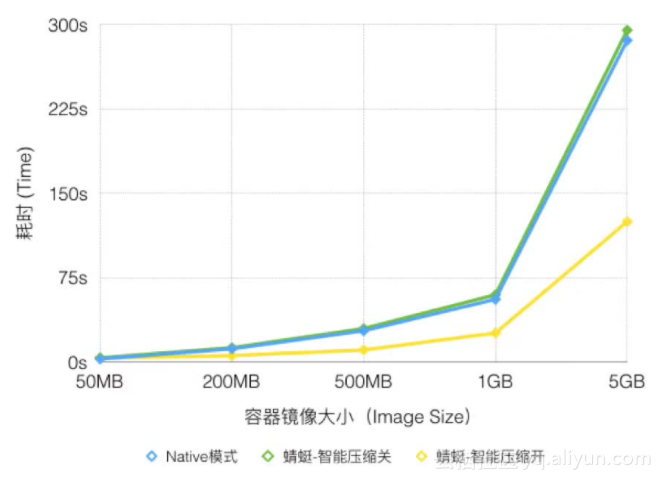
单客户端不同模式对比图
Native和蜻蜓(关闭智能压缩特性)平均耗时基本接近,蜻蜓稍高一点,因为蜻蜓在下载过程中会校验每个分块数据的MD5值,同时在下载之后还会校验整个文件的MD5,以保证下载的文件跟源文件是一致的;而开启了智能压缩的模式下,其耗时比Native模式还低!
实验二:多客户端并发
- 测试镜像大小:50MB、200MB、500MB、1GB、5GB
- 镜像仓库带宽:15Gbps
- 客户端带宽:双百兆bit/s网络环境
- 多并发:10并发、200并发、1000并发
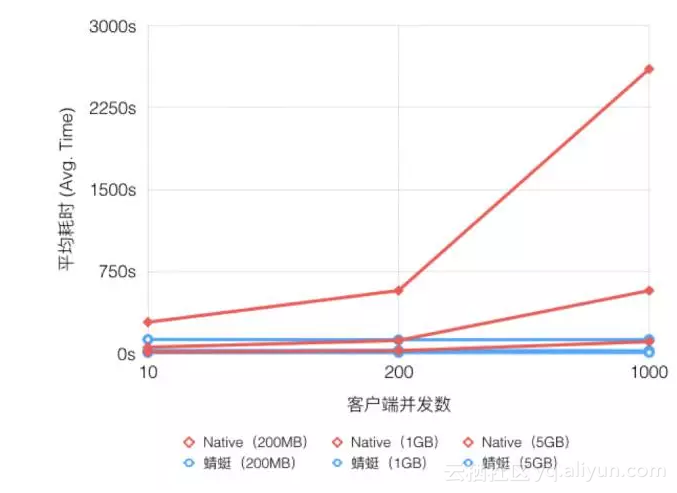
不同镜像大小和并发数的对比图
上图可以看出,随着下载规模的扩大,蜻蜓与Native模式耗时差异显著扩大,最高可提速可以达20倍。在测试环境中源的带宽也至关重要,如果源的带宽是2Gbps,提速可达57倍。
下图是下载文件的总流量(并发数 * 文件大小)和回源流量(去Registry下载的流量)的一个对比:
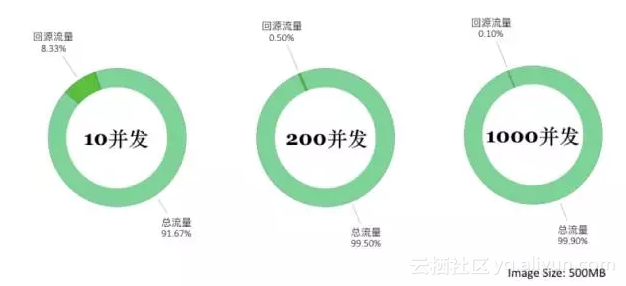
蜻蜓镜像分发出流量对比图
向200个节点分发500M的镜像,比docker原生模式使用更低的网络流量,实验数据表明采用蜻蜓后,Registry的出流量降低了99.5%以上;而在1000并发规模下,Registry的出流量更可以降低到99.9%左右。
阿里巴巴实践效果
蜻蜓在阿里投入使用大概已有两年,两年来业务发展迅速,从分发的次数来统计目前一个月接近20亿次,分发3.4PB数据。其中容器镜像的分发量接近一半。
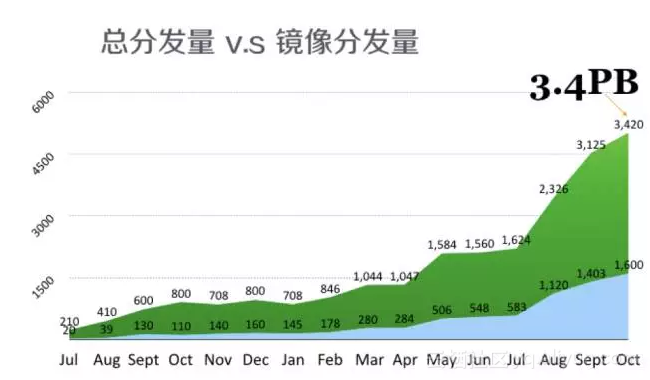
蜻蜓在阿里文件vs镜像分发流量趋势图
在阿里最大的一次分发应该就是今年双11期间, 要对上万台服务器同时下发5GB的数据文件。
走向智能化
阿里在AIOps起步虽然不是最早, 但是我们近年来投入巨大,并在很多产品上有所应用。蜻蜓这个产品中有以下应用:
智能流控
流控在道路交通中很常见,比如中国道路限速规定,没有中心线的公路,限速为40公里/小时;同方向只有1条机动车道的公路,限速为70公里/小时;快速道路80公里;高速公路最高限速为120公里/小时等等。这种限速对每辆车都一样,显然不够灵活,所以在道路非常空闲的情况下,道路资源其实是非常浪费的,整体效率非常低下。
红绿灯其实也是流控的手段,现在的红绿灯都是固定时间,不会根据现实的流量来做智能的判断,所以去年10月召开的云栖大会上,王坚博士曾感慨,世界上最遥远的距离不是从南极到北极,而是从红绿灯到交通摄像头,它们在同一根杆上,但从来没有通过数据被连接过,摄像头看到的东西永远不会变成红绿灯的行动。这既浪费了城市的数据资源,也加大了城市运营发展的成本。
蜻蜓其中一个参数就是控制磁盘和网络带宽利用率的,用户可以通过参数设定使用多少网络IO/磁盘IO。如上所述,这种方法是非常僵化的。所以目前我们智能化方面的主要思想之一是希望类似的参数不要再人为来设定,而是根据业务的情况结合系统运行的情况,智能的决定这些参数的配置。最开始可能不是最优解,但是经过一段时间运行和训练后自动达到最优化的状态,保证业务稳定运行同时又尽可能的充分利用网络和磁盘带宽,避免资源浪费。
智能调度
分块任务调度是决定整个文件分发效率高低与否的关键因素,如果只是通过简单的调度策略,比如随机调度或者其他固定优先级的调度,这种做法往往会引起下载速率的频繁抖动,很容易导致下载毛刺过多,同时整体下载效率也会很差。为了最优化任务调度,我们经历了无数次的尝试和探索,最终通过多维度(比如机器硬件配置、地理位置、网络环境、历史下载结果和速率等等维度的数据)的数据分析(主要利用了梯度下降算法,后续还会尝试其他算法),智能动态决定当前请求者最优的后续分块任务列表。
智能压缩
智能压缩会对文件中最值得压缩的部分实施相应的压缩策略,从而可以节约大量的网络带宽资源。
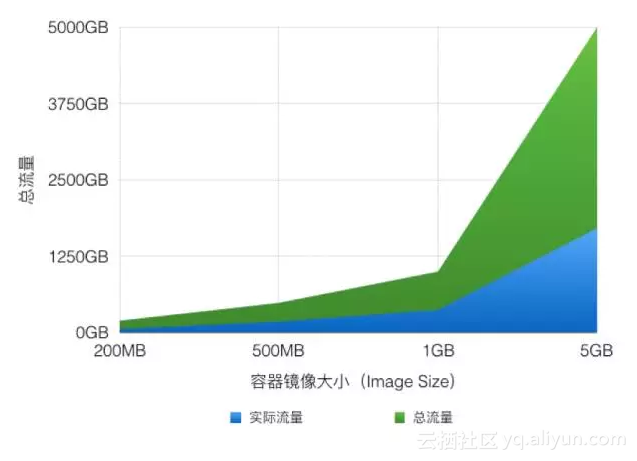
对容器镜像目前的实际平均数据来看,压缩率(Compression Ration) 是40%,也就是说100MB镜像可以压缩到40MB。针对1000并发规模,通过智能压缩可以减少60%的流量。
安全
在下载某些敏感的文件(比如秘钥文件或者账号数据文件等)时,传输的安全性必须要得到有效的保证,在这方面,蜻蜓主要做了两个工作:
- 支持携带HTTP的header数据,以满足那些需要通过header来进行权限验证的文件源;
- 利用对称加密算法,对文件内容进行传输加密。
开源
随着容器技术的流行,容器镜像这类大文件分发成为一个重要问题,为了更好的支持容器技术的发展,数据中心大规模文件的分发,阿里决定开源蜻蜓来更好的推进技术的发展。阿里将持续支持开源社区,并把自己经过实战检验的技术贡献给社区。敬请期待。
总结
蜻蜓通过使用P2P技术同时结合智能压缩、智能流控等多种创新技术,解决大规模文件下载以及跨网络隔离等场景下各种文件分发难题,大幅提高数据预热、大规模容器镜像分发等业务能力。
蜻蜓支持多种容器技术,对容器本身无需做任何改造,镜像分发比natvie方式提速可高达57倍,Registry网络出流量降低99.5%以上。承载着PB级的流量的蜻蜓,在阿里已然成为重要的基础设施之一,为业务的极速扩张和双11大促保驾护航。
PS:云效2.0 智能运维平台 - 致力于打造具备世界级影响力的智能运维平台,诚聘资深技术/产品专家,工作地点:杭州、北京、美国,有意者可以点击文末“阅读原文”了解详情。
Reference
[1]Docker Overview:
https://docs.docker.com/engine/docker-overview/
[2]Where are docker images stored:
http://blog.thoward37.me/articles/where-are-docker-images-stored/
[3]Image Spec:
https://github.com/moby/moby/blob/master/image/spec/v1.md
[4]Pouch开源地址:
https://github.com/alibaba/pouch
[5]蜻蜓开源地址:
https://github.com/alibaba/dragonfly
[6]阿里云容器服务:
https://www.aliyun.com/product/containerservice
[7]飞天专有云敏捷版:
https://yq.aliyun.com/articles/224507
[8]云效智能运维平台:
https://www.aliyun.com/product/yunxiao