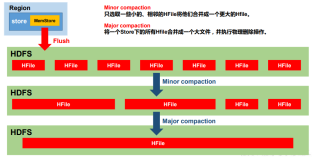
首先来想两个问题:1、何谓compact?2、它产生的背景是怎样的?
compact是指HBase表中HRegion上某个Column Family下,部分或全部HFiles的合并。它是由于数据在持续写入后,MemStore达到一定阈值,被flush到磁盘上,形成许许多多的文件,这些文件如果不做处理,将会严重影响HBase数据读取的效率。所以,在HBase系统内部,需要定期在满足一定条件的情况下,或者由人为手动触发,将这许多文件合并成一个大文件。
那么,在HRegion上,compact的流程是怎样的呢?
在HRegion上,compact流程的发起方法是compact()方法。其代码如下:
/*
* Called by compaction thread and after region is opened to compact the
* HStores if necessary.
*
* Region上线后如果需要合并HStores,该方法就被合并线程调用。
*
* <p>This operation could block for a long time, so don't call it from a
* time-sensitive thread.
*
* 该操作可能会阻塞较长一段时间,所以对时间敏感的线程不要调用该方法
*
* Note that no locking is necessary at this level because compaction only
* conflicts with a region split, and that cannot happen because the region
* server does them sequentially and not in parallel.
*
* @param cr Compaction details, obtained by requestCompaction()
* @return whether the compaction completed
* @throws IOException e
*/
public boolean compact(CompactionContext compaction, Store store) throws IOException {
// 确认合并上下文不为空,即合并请求request不为空,且请求request中所包含的文件不为空
assert compaction != null && compaction.hasSelection();
assert !compaction.getRequest().getFiles().isEmpty();
// 如果Region正在下线或者已经下线,记录日志,并取消合并请求,返回false
// 取消合并调用的是Store的cancelRequestedCompaction()方法
if (this.closing.get() || this.closed.get()) {
LOG.debug("Skipping compaction on " + this + " because closing/closed");
store.cancelRequestedCompaction(compaction);
return false;
}
// 任务状态监控器
MonitoredTask status = null;
// 标志位,请求需要撤销
boolean requestNeedsCancellation = true;
// block waiting for the lock for compaction
// 阻塞,等待合并的锁
// 获取读锁:又是一个出现读锁的地方,
/**
* 我的理解,这个lock锁是Region行为上的一个读写锁,加上这个锁,控制Region的整体行为,比如flush、compact、close等,
* flush和compact使用的是读锁,是一个共享锁,意味着flush和compact可以同步进行,但是不能执行close,因为close是写锁,
* 它是一个独占锁,一旦它占用锁,其他线程就不能发起flush、compact等操作,当然,close线程本身除外,因为Region在下线前要保证
* MemStore内的数据被flush到文件
*
*/
lock.readLock().lock();
try {
// 获取列簇名
byte[] cf = Bytes.toBytes(store.getColumnFamilyName());
// 如果根据列簇名从stores中获取的store,和传入的store不相等,则记录warn日志,并返回false
if (stores.get(cf) != store) {
// 此时,对应store已在该HRegion上被重新初始化,那么我们就要取消此次合并请求。这种情况可能是由于分裂事务回滚时造成的。
LOG.warn("Store " + store.getColumnFamilyName() + " on region " + this
+ " has been re-instantiated, cancel this compaction request. "
+ " It may be caused by the roll back of split transaction");
return false;
}
// 任务状态监控器记录状态:Compacting storename in regionname
status = TaskMonitor.get().createStatus("Compacting " + store + " in " + this);
// 如果Region已下线,跳过合并
if (this.closed.get()) {
String msg = "Skipping compaction on " + this + " because closed";
LOG.debug(msg);
status.abort(msg);
return false;
}
// 状态位,标识compact时状态已设置,主要是累加合并进行的数目已经执行
boolean wasStateSet = false;
try {
// 判断writestate,确认Region可写,并累加合并正在进行的数目
synchronized (writestate) {
if (writestate.writesEnabled) {// 如果Region可写,累加合并进行的数目,标志位wasStateSet设置为true
wasStateSet = true;
++writestate.compacting;
} else {// 如果Region不可写,记录log信息,舍弃该状态
String msg = "NOT compacting region " + this + ". Writes disabled.";
LOG.info(msg);
status.abort(msg);
return false;
}
}
LOG.info("Starting compaction on " + store + " in region " + this
+ (compaction.getRequest().isOffPeak()?" as an off-peak compaction":""));
// 空方法而已。。。其实是为compact设置的一个进行之前的预处理方法
doRegionCompactionPrep();
try {
// 任务状态监控器记录状态:
status.setStatus("Compacting store " + store);
// We no longer need to cancel the request on the way out of this
// method because Store#compact will clean up unconditionally
// 标志位requestNeedsCancellation设置为false,说明此时compact可以真正执行
requestNeedsCancellation = false;
// 调用store的compact方法,执行合并
store.compact(compaction);
} catch (InterruptedIOException iioe) {
String msg = "compaction interrupted";
LOG.info(msg, iioe);
status.abort(msg);
return false;
}
} finally {
if (wasStateSet) {// 如果合并正在进行的数目已经累加
synchronized (writestate) {
// 合并正在进行的数目减一
--writestate.compacting;
// 如果没有合并在进行,唤醒其他阻塞线程
if (writestate.compacting <= 0) {
writestate.notifyAll();
}
}
}
}
// 任务状态监控器记录状态:合并完成
status.markComplete("Compaction complete");
// 返回处理结果true
return true;
} finally {
try {
// 如果需要取消合并,调用Store的cancelRequestedCompaction()方法取消合并
if (requestNeedsCancellation) store.cancelRequestedCompaction(compaction);
// 清空状态跟踪器
if (status != null) status.cleanup();
} finally {
// 释放读锁
lock.readLock().unlock();
}
}
}
先说下这个方法的参数。它需要两个参数:CompactionContext类型的compaction和Store类型的store。
CompactionContext是合并的上下文类。该类含有运行一个合并所必需的全部“物理”细节,其内部包含一个合并请求CompactionRequest类型的request,同时包含针对该请求的判断、获取、赋值方法,代码如下:
// 合并请求
protected CompactionRequest request = null;
/**
* 获取合并请求
*/
public CompactionRequest getRequest() {
assert hasSelection();
return this.request;
}
/**
* 判断合并请求是否为空,意思也就是是否已选择文件
*/
public boolean hasSelection() {
return this.request != null;
}
/**
* Forces external selection to be applied for this compaction.
* 设置合并请求
* @param request The pre-cooked request with selection and other settings.
*/
public void forceSelect(CompactionRequest request) {
this.request = request;
}
另外,这个CompactionContext有两种实现,分别为:
1、位于DefaultStoreEngine中的DefaultCompactionContext;
2、位于StripeStoreEngine中的StripeCompaction;
这两种CompactionContext的实现都分别实现了用于选择需要合并文件的select()方法、在已选择文件的基础上执行合并的compact()方法。关于两种方案如何被选择及其区别,我们以后会在专门的文章中分析。目前读者只要知道有这两种选择及合并策略及其相应的方法即可。
Store则是HRegion上专门用于某个列簇存储的接口。Store的实现为HStore,包含了一个memstore和若干StoreFiles。从这里我们也可以看出,合并在HRegion上其实是以Store为逻辑单位来执行的。
该方法的主要流程如下:
1、首先做一些必要的校验,包括:
1.1、确认合并上下文不为空,即合并请求request不为空,且请求request中所包含的文件不为空;
1.2、如果Region正在下线或者已经下线,记录日志,并取消合并请求,返回false,取消合并调用的是Store的cancelRequestedCompaction()方法;
2、设置一个标志位:requestNeedsCancellation,表示是否需要撤销合并请求,默认为ture,需要撤销;
3、接着再获取HRegion上lock的读锁,这里读锁的理解和我们讲MemStore的flush时是一样的,即:
这个lock锁是Region行为上的一个读写锁,加上这个锁,控制Region的整体行为,比如flush、compact、close等,flush和compact使用的是读锁,是一个共享锁,意味着flush和compact可以同步进行,但是不能执行close,因为close是写锁,它是一个独占锁,一旦它占用锁,其他线程就不能发起flush、compact等操作,当然,close线程本身除外,因为Region在下线前要保证emStore内的数据被flush到文件。
4、从入参store中获取列簇名cf;
5、根据列簇名从stores中获取store,如果其和传入的store不相等,则记录warn日志,并返回false。此时,对应store已在该HRegion上被重新初始化,那么我们就要取消此次合并请求。这种情况可能是由于分裂事务回滚时造成的;
6、获取任务状态监控器status,并记录状态:Compacting storename in regionname;
7、如果Region已下线,跳过合并,返回false;
8、设置一个状态位wasStateSet,标识compact时状态已设置,主要是累加合并进行的数目已经执行,默认为false,即未设置;
9、判断writestate,确认Region可写,并累加合并正在进行的数目:
9.1、如果Region可写,累加合并进行的数目,标志位wasStateSet设置为true;
9.2、如果Region不可写,记录log信息,舍弃该状态。
10、任务状态监控器记录状态:Compacting store storename;
11、标志位requestNeedsCancellation设置为false,说明此时compact可以真正执行;
12、调用store的compact方法,执行合并,从这里看貌似是真正干活了;
13、如果合并正在进行的数目已经累加 ,即标志位wasStateSet为true:
13.1、合并正在进行的数目writestate.compacting减一;
13.2、如果没有合并在进行,唤醒其他阻塞线程;
14、任务状态监控器记录状态:合并完成Compaction complete;
15、返回处理结果true。
并且,在返回结果前,或者说抛出异常前,finally模块中,我们还需要做如下处理:
1、如果需要取消合并,调用Store的cancelRequestedCompaction()方法取消合并;
2、清空状态跟踪器status;
3、释放读锁。
上述流程基本上讲的比较细了,读者可以结合代码和流程描述,自行体会。
而关于Store的compact()、cancelRequestedCompaction()等方法,我们将在后续章节陆续进行介绍。