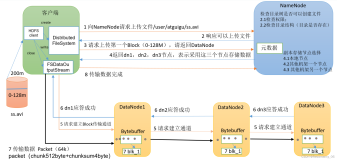
我们知道,HDFS中的文件是由数据块Block组成的,并且为了提高容错性,每个数据块Block都会在不同数据节点DataNode上有若干副本Replica。那么,什么是Block?什么又是Replica?
首先,我们看下Block的定义,如下:
/**************************************************
* A Block is a Hadoop FS primitive, identified by a
* long.
*
**************************************************/
@InterfaceAudience.Private
@InterfaceStability.Evolving
public class Block implements Writable, Comparable<Block> {
public static final String BLOCK_FILE_PREFIX = "blk_";
public static final String METADATA_EXTENSION = ".meta";
//....省略部分代码
private long blockId;
private long numBytes;
private long generationStamp;
//....省略部分代码
} Block实际上是HDFS文件数据块在HDFS元数据或者文件树中的一种表现形式。它有三个重要字段,均是long类型的,数据块艾迪blockId、数据块字节数numBytes、数据块时间戳generationStamp。另外,BLOCK_FILE_PREFIX表明了数据块数据文件在物理硬盘上为文件名是以blk_为前缀的,而METADATA_EXTENSION则标识了数据块元数据文件在物理硬盘上是以.meta为文件名后缀的。
我们再看下副本Replica的定义,它实际上是一个借口,如下:
/**
* This represents block replicas which are stored in DataNode.
*/
@InterfaceAudience.Private
public interface Replica {
//....省略部分代码
} Replica实际上代表了存储与数据节点上的数据块副本,是数据块Block在数据节点上的存储形式的抽象。Replica的实现则是ReplicaInfo,它继承自Block,并实现了Replica接口,如下:
/**
* This class is used by datanodes to maintain meta data of its replicas.
* It provides a general interface for meta information of a replica.
* 这个类被数据节点用于保持它副本的元数据信息。它为副本的元数据信息提供了通用的接口。
*/
@InterfaceAudience.Private
abstract public class ReplicaInfo extends Block implements Replica {
//....省略部分代码
} 到了这里,我们就可以通俗的理解为,Block是名字节点NanmeNode中对文件数据块的抽象描述,它不区分副本,是组成文件的数据块的统一抽象描述,而Replica则是数据节点DataNode对存储在其上的物理数据块副本的统一抽象描述,它继承自Block,很好的反应了Block与Replica的对应关系。
我们简单看下抽象类ReplicaInfo都有哪些成员变量,代码如下:
/** volume where the replica belongs */ // 数据块副本属于的卷FsVolumeSpi实例volume private FsVolumeSpi volume; /** directory where block & meta files belong */ /** * Base directory containing numerically-identified sub directories and * possibly blocks. * 数据块副本存储的基础路径,其包含以数字标识的子目录,或者干脆是数据块 */ private File baseDir; /** * Whether or not this replica's parent directory includes subdirs, in which * case we can generate them based on the replica's block ID * 标志位:数据块副本的父目录是否包含子目录,如果是的话,我们可以根据数据块副本的数据块ID获取它们。 */ private boolean hasSubdirs; // 内部基础路径 private static final Map<String, File> internedBaseDirs = new HashMap<String, File>();由上面的代码,我们可以知道,它主要包括数据块副本属于的卷FsVolumeSpi实例volume,数据块副本存储的基础路径baseDir,其包含以数字标识的子目录,或者干脆是数据块,还有就是标志位:数据块副本的父目录是否包含子目录,如果是的话,我们可以根据数据块副本的数据块ID获取它们。