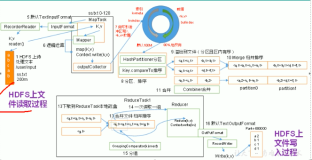
基于作业大小因素,MRAppMaster提供了三种作业运行方式:本地Local模式、Uber模式、Non-Uber模式。其中,
1、本地Local模式:通常用于调试;
2、Uber模式:为降低小作业延迟而设计的一种模式,所有任务,不管是Map Task,还是Reduce Task,均在同一个Container中顺序执行,这个Container其实也是MRAppMaster所在Container;
3、Non-Uber模式:对于运行时间较长的大作业,先为Map Task申请资源,当Map Task运行完成数目达到一定比例后再为Reduce Task申请资源。
在Yarn中,作业运行的资源,统一被抽象为容器Container,在MRAppMaster中关于作业运行时需要的资源的分配与加载代码中,容器分配申请服务、容器分配完成后加载服务中,都有关于Uber模式和Non-Uber模式的处理,如下:
1、容器分配申请路由服务
容器分配申请路由服务ContainerAllocatorRouter继承自AbstractService,是Hadoop中一个典型的服务,其正常提供服务需要经历初始化init、启动start等过程,而在服务启动的serviceStart()方法中,存在以下关于Uber模式和Non-Uber模式的处理:
// 如果Job在Uber模式下运行,启动构造容器分配器LocalContainerAllocator实例
if (job.isUber()) {
MRApps.setupDistributedCacheLocal(getConfig());
this.containerAllocator = new LocalContainerAllocator(
this.clientService, this.context, nmHost, nmPort, nmHttpPort
, containerID);
} else {
// 否则构造RM容器分配器RMContainerAllocator实例
this.containerAllocator = new RMContainerAllocator(
this.clientService, this.context);
}
可见,如果Job在Uber模式下运行,启动构造容器分配器LocalContainerAllocator实例,否则构造RM容器分配器RMContainerAllocator实例。而LocalContainerAllocator代表的是本地容器分配器,其构造过程中传入的containerID为MRAppMaster的成员变量containerID,什么意思呢?不就正好说明LocalContainerAllocator所使用的容器,也就是Uber模式下所使用的容器,就是MRAppMaster所在Container,与上面所介绍的Uber模式正好一致,而Non-Uber模式下则需要使用Yarn的RMContainerAllocator,通过与ResourceManager进行通信来申请容器的分配,总的原则就是:先为Map Task申请资源,当Map Task运行完成数目达到一定比例后再为Reduce Task申请资源。
2、容器加载路由服务
容器加载路由服务ContainerLauncherRouter同样继承自AbstractService,也是Hadoop中一个典型的服务,我们同样看下服务启动serviceStart()方法,如下:
// 如果Job在Uber模式下运行,启动构造本地容器加载器LocalContainerLauncher实例
if (job.isUber()) {
this.containerLauncher = new LocalContainerLauncher(context,
(TaskUmbilicalProtocol) taskAttemptListener);
} else {
// 否则,构造容器加载器ContainerLauncherImpl实例
this.containerLauncher = new ContainerLauncherImpl(context);
} 也是针对Uber模式和Non-Uber模式分别处理,如果Job在Uber模式下运行,启动构造本地容器加载器LocalContainerLauncher实例;否则,构造容器加载器ContainerLauncherImpl实例。
另外,由于Uber模式下不管是Map Task,还是Reduce Task,均在同一个Container中顺序执行,所以MapReduce的推测执行机制对于Uber模式是不适用的,故在MRAppMaster服务启动的serviceStart()方法中,对于Uber模式,会禁用推测执行机制,相关代码如下:
if (job.isUber()) {
// Uber模式下禁用推测执行机制,即Disable Speculation
speculatorEventDispatcher.disableSpeculation();
LOG.info("MRAppMaster uberizing job " + job.getID()
+ " in local container (\"uber-AM\") on node "
+ nmHost + ":" + nmPort + ".");
} else {
// send init to speculator only for non-uber jobs.
// This won't yet start as dispatcher isn't started yet.
// Non-Uber模式下发送SpeculatorEvent事件,初始化speculator
dispatcher.getEventHandler().handle(
new SpeculatorEvent(job.getID(), clock.getTime()));
LOG.info("MRAppMaster launching normal, non-uberized, multi-container "
+ "job " + job.getID() + ".");
} 可以看到,Uber模式下禁用推测执行机制,即Disable Speculation,Non-Uber模式下发送SpeculatorEvent事件,初始化speculator,因此,对于Uber模式,会禁用推测执行机制。
在作业的抽象实现JobImpl中,会针对Uber模式进行一些特定参数设置,如下:
if (isUber) {
LOG.info("Uberizing job " + jobId + ": " + numMapTasks + "m+"
+ numReduceTasks + "r tasks (" + dataInputLength
+ " input bytes) will run sequentially on single node.");
// make sure reduces are scheduled only after all map are completed
// mapreduce.job.reduce.slowstart.completedmaps参数设置为1,
// 即全部Map任务完成后才会为Reduce任务分配资源
conf.setFloat(MRJobConfig.COMPLETED_MAPS_FOR_REDUCE_SLOWSTART,
1.0f);
// uber-subtask attempts all get launched on same node; if one fails,
// probably should retry elsewhere, i.e., move entire uber-AM: ergo,
// limit attempts to 1 (or at most 2? probably not...)
// 参数mapreduce.map.maxattempts、mapreduce.reduce.maxattempts设置为1,即Map、Reduce任务的最大尝试次数均为1
conf.setInt(MRJobConfig.MAP_MAX_ATTEMPTS, 1);
conf.setInt(MRJobConfig.REDUCE_MAX_ATTEMPTS, 1);
// disable speculation
// 参数mapreduce.map.speculative、mapreduce.reduce.speculative设置为false,即禁用Map、Reduce任务的推测执行机制
conf.setBoolean(MRJobConfig.MAP_SPECULATIVE, false);
conf.setBoolean(MRJobConfig.REDUCE_SPECULATIVE, false);
} 主要包括:
1、mapreduce.job.reduce.slowstart.completedmaps参数设置为1,即全部Map任务完成后才会为Reduce任务分配资源;
2、参数mapreduce.map.maxattempts、mapreduce.reduce.maxattempts设置为1,即Map、Reduce任务的最大尝试次数均为1;
3、参数mapreduce.map.speculative、mapreduce.reduce.speculative设置为false,即禁用Map、Reduce任务的推测执行机制;