从rnn结构说起
根据输出和输入序列不同数量rnn可以有多种不同的结构,不同结构自然就有不同的引用场合。如下图,
- one to one 结构,仅仅只是简单的给一个输入得到一个输出,此处并未体现序列的特征,例如图像分类场景。
- one to many 结构,给一个输入得到一系列输出,这种结构可用于生产图片描述的场景。
- many to one 结构,给一系列输入得到一个输出,这种结构可用于文本情感分析,对一些列的文本输入进行分类,看是消极还是积极情感。
- many to many 结构,给一些列输入得到一系列输出,这种结构可用于翻译或聊天对话场景,对输入的文本转换成另外一些列文本。
- 同步 many to many 结构,它是经典的rnn结构,前一输入的状态会带到下一个状态中,而且每个输入都会对应一个输出,我们最熟悉的就是用于字符预测了,同样也可以用于视频分类,对视频的帧打标签。

seq2seq
在 many to many 的两种模型中,上图可以看到第四和第五种是有差异的,经典的rnn结构的输入和输出序列必须要是等长,它的应用场景也比较有限。而第四种它可以是输入和输出序列不等长,这种模型便是seq2seq模型,即Sequence to Sequence。它实现了从一个序列到另外一个序列的转换,比如google曾用seq2seq模型加attention模型来实现了翻译功能,类似的还可以实现聊天机器人对话模型。经典的rnn模型固定了输入序列和输出序列的大小,而seq2seq模型则突破了该限制。


其实对于seq2seq的decoder,它在训练阶段和预测阶段对rnn的输出的处理可能是不一样的,比如在训练阶段可能对rnn的输出不处理,直接用target的序列作为下时刻的输入,如上图一。而预测阶段会将rnn的输出当成是下一时刻的输入,因为此时已经没有target序列可以作为输入了,如上图二。
encoder-decoder结构
seq2seq属于encoder-decoder结构的一种,这里看看常见的encoder-decoder结构,基本思想就是利用两个RNN,一个RNN作为encoder,另一个RNN作为decoder。encoder负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,这个过程称为编码,如下图,获取语义向量最简单的方式就是直接将最后一个输入的隐状态作为语义向量C。也可以对最后一个隐含状态做一个变换得到语义向量,还可以将输入序列的所有隐含状态做一个变换得到语义变量。

而decoder则负责根据语义向量生成指定的序列,这个过程也称为解码,如下图,最简单的方式是将encoder得到的语义变量作为初始状态输入到decoder的rnn中,得到输出序列。可以看到上一时刻的输出会作为当前时刻的输入,而且其中语义向量C只作为初始状态参与运算,后面的运算都与语义向量C无关。

decoder处理方式还有另外一种,就是语义向量C参与了序列所有时刻的运算,如下图,上一时刻的输出仍然作为当前时刻的输入,但语义向量C会参与所有时刻的运算。

encoder-decoder模型对输入和输出序列的长度没有要求,应用场景也更加广泛。
如何训练
前面有介绍了encoder-decoder模型的简单模型,但这里以下图稍微复杂一点的模型说明训练的思路,不同的encoder-decoder模型结构有差异,但训练的核心思想都大同小异。

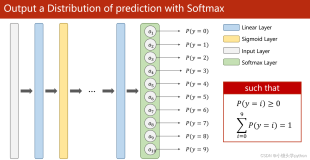
我们知道RNN是可以学习概率分布然后进行预测的,比如我们输入t个时刻的数据后预测t+1时刻的数据,最经典的就是字符预测的例子,可在前面的《循环神经网络》和《TensorFlow构建循环神经网络》了解到更加详细的说明。为了得到概率分布一般会在RNN的输出层使用softmax激活函数,就可以得到每个分类的概率。
对于RNN,对于某个序列,对于时刻t,它的输出概率为
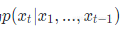
,则softmax层每个神经元的计算如下:
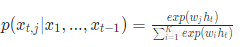
其中ht是隐含状态,它与上一时刻的状态及当前输入有关,即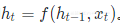 。
。
那么整个序列的概率就为
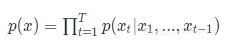

========广告时间========
鄙人的新书《Tomcat内核设计剖析》已经在京东销售了,有需要的朋友可以到 https://item.jd.com/12185360.html 进行预定。感谢各位朋友。
=========================
欢迎关注: