一、概述
因为自家公司是做B2B类Saas服务的,难免会产生精准计费的问题,所以在通过多套方案的选型及对比以后,我们最终确定了以下的方式进行自有业务平台的流量计算方案。因为涉及到具体的操作,所以阅读本文的前提是我默认您已经具备了阿里云相关产品的使用经验。
目前的流量构成主要为:
1.用户访问业务平台产品的页面响应流量,即http返回页面的大小。
2.用户访问业务平台中图片所产品的流量,所有的图片存放在OSS中,通过CDN暴露在公网访问。
3.用户的API请求产生的响应流量,即Json返回值页面的大小。
我们的目标:
1.我们的计费颗粒为按天计算,所以我们只需要确保第二天能得到前一天的流量数据即可。对实时性的要求不是那么的高。
2.需要所有的数据都参与运算,并且能支持多渠道的日志来源。
3.需要支持重新计算,有些时候因为一些特定原因,需要重新获取某个时间段的流量数据,需要得到和之前一致的数据结果(前提是原始日志相同的情况下)。
4.不能产生大量成本,最好是不要购买服务器,不要进行太大的支出。
5.所有流量计算出的结果,按年、月、日、时存入Mysql数据库,便于实时查表显示给客户。
二、流量统计流程

三、获取访问日志
目前所有的访问都基于HTTP展开,那么无论是apache还是nginx都是自带访问日志功能的,只需要把这些文本日志清洗一下存到数据库就行了,或者有更简单的方式,将这些日志通过阿里云的日志服务收集起来,然后定时投递到数加的ODPS表里即可。
这里给一个日志服务的传送门:https://www.aliyun.com/product/sls
相对于自己收集日志并清洗,我还是更加建议使用阿里云的日志服务,查询快且稳定、收费也低、客户支持力度很棒、迭代速度很快。
值得一提的是,数加平台支持一键导入CDN日志,如果你的业务恰恰好是全CDN加速的,那么你只需要收集CDN日志就可以进行较为精准的流量统计了。
我们收集到的访问日志格式大概是这样的:
[12/Nov/2017:00:09:15 +0800] 112.28.172.8 - 0 "http://www.xxx.com/Article/86892.html" "GET http://www.xxx.com/Public/css/style.css" 200 393 21427 HIT "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36" "text/css"
分割后按顺序分别是:时间,访问IP,代理IP,responsetime,referer,method,访问URL,httpcode,requestsize,responsesize,cache命中状态,UA头,文件类型。
其中最重要的就是2个字段:URL、responsesize。
URL字段是整个访问的URL路径,可以用于分析文件类型和客户平台。
Responsesize是指整个请求响应的数据大小。
你也可以结合httpcode和缓存命中来进行更精准的计算,我下面的介绍不涉及这一块内容,一通百通,明白后自己调整一下ODPS的SQL语句就行了。
日志导入ODPS
如果我们需要将日志数据导入到ODPS中,那么需要完成ODPS表的创建,这一块进入到数加平台即可完成,与我们平时开发中创建MYSQL、MSSQL表的方式差不多,只是有些数据类型上的差异。同时ODPS表也支持了一个很重要也很有用的概念——分区。
你可以在创建ODPS表的时候,指定一个或多个字段来对某一些数据进行分区,常见的就是按时间分区,比如日志时间格式化到小时级别用作分区,这样就能把某个小时的数据置入特定分区。设置分区的目的主要是在后期运算、覆写、重跑时更便利。
那么日志导入到ODPS的方式有几种:
1.如果你的日志在阿里云日志服务中,直接配置一下ODPS投递即可,具体查询文档还是比较简单的,就不啰嗦了。
2.如果你的日志数据在自建系统中,那么可以考虑使用“数加平台的-数据集成”功能来完成数据的导入和同步,支持的数据库种类超级多,具体请看文档:https://help.aliyun.com/document_detail/53008.html ,市面上90%的数据库都支持的。
此处我们得到一个ODPS数据表名为:cdn_logs,里面存放的是所有的cdn访问日志,名字只是演示,你可以自定义。我的建表语句是这样的:
CREATE TABLE cdn_logs ( station_node STRING COMMENT '节点', unix_time BIGINT COMMENT '访问时间', method STRING COMMENT '请求方法', procotol STRING COMMENT '请求协议', domain STRING COMMENT '域名', uri STRING COMMENT '请求的uri', uri_parameter STRING COMMENT '请求参数', imgsrc_type BIGINT COMMENT '图片压缩类型ID', return_code BIGINT COMMENT '返回码', rt BIGINT COMMENT '延时', request_size BIGINT COMMENT '请求大小', response_size BIGINT COMMENT '响应大小', hit_info STRING COMMENT '命中信息', client_ip BIGINT COMMENT '真实用户IP', proxy_ip STRING COMMENT '中间代理ip', remote_address BIGINT COMMENT '客户端IP', bacend_server STRING COMMENT '回源IP', refer_procotol STRING COMMENT '引用协议', refer_domain STRING COMMENT '引用域名', refer_uri STRING COMMENT '引用uri', refer_parameter STRING COMMENT '引用参数', content_type STRING COMMENT '请求返回类型', user_agent STRING COMMENT 'UA', port BIGINT COMMENT '客户端口', transfer_success BIGINT COMMENT '传输是否成功', last_modify STRING COMMENT '服务器上文件的最后修改时间', user_info STRING COMMENT '用户信息', traceid STRING COMMENT '访问错误排查跟踪id', sent_http_via STRING COMMENT 'http via头', reserve_1 STRING COMMENT '保留字段1', reserve_2 STRING COMMENT '保留字段2', reserve_3 STRING COMMENT '保留字段3' ) PARTITIONED BY ( log_date STRING COMMENT '日期分区', domain_id BIGINT COMMENT 'ID分区' ) LIFECYCLE 100000;
四、进行离线计算任务配置
我们已经拥有了一个基础数据表:cdn_logs,在此之外我们还需要创建2个表,分别为:
cdn_logs_format表——对cdn_logs表进行格式化后得到的进一步清洗数据,此处需要贴近业务进行各种DIY操作,这个表的生命周期建议是参考自己的日志量来规划,如果日志少,就设为永久,否则设置成周期。建表语句如下:
CREATE TABLE cdn_logs_format ( unix_time BIGINT COMMENT '访问时间', uri_parent STRING COMMENT '首层目录名', method STRING COMMENT '请求方法', procotol STRING COMMENT '请求协议', domain STRING COMMENT '域名', uri STRING COMMENT '请求的uri', return_code BIGINT COMMENT '返回码', rt BIGINT COMMENT '延时', response_size BIGINT COMMENT '响应大小', client_ip BIGINT COMMENT '真实用户ip', remote_address BIGINT COMMENT '客户端ip', bacend_server STRING COMMENT '回源ip', refer_domain STRING COMMENT '引用域名', refer_uri STRING COMMENT '引用uri', content_type STRING COMMENT '请求返回类型', user_agent STRING COMMENT 'ua' ) PARTITIONED BY ( log_date STRING COMMENT '日期分区' ) LIFECYCLE 100000;
aggr_product_traffic表——最终的流量统计结果表,这个表结果少,建议生命周期永久,建表语句:
CREATE TABLE aggr_product_traffic ( clientcode STRING COMMENT '客户端代码', year BIGINT COMMENT '年', month BIGINT COMMENT '月', day BIGINT COMMENT '日', hour BIGINT COMMENT '小时', mi BIGINT COMMENT '分钟', traffic BIGINT COMMENT '流量', create_at BIGINT COMMENT '创建汇总时的时间戳', targetdate STRING COMMENT '汇总结果时间' ) COMMENT '产品流量汇总表' PARTITIONED BY ( aggr_date STRING COMMENT '分区时间', product STRING COMMENT '产品代码' ) LIFECYCLE 100000;
把准备工作准备完成后,我们需要在数加里配置对应的离线任务,在配置离线任务之前可以使用数加的“数据开发IDE”进行试验,这里需要注意,试验是有成本的,但是很便宜,一瓶可乐钱大概可以玩一天。
开始之前,我们需要明白几个关键词:
虚节点:没意义的节点,没实际功能,虚拟出来便于理解整体逻辑关系的,可建可不建。
任务节点:说白了就是一个具体的操作,比如跑SQL语句或同步数据。
调度周期:这个很重要,关系到了你的任务颗粒细度,可以设置为分钟、小时、天、周、月,大部分是够用的。
离线任务:我们一定要明白一个概念,所有在数加平台运行的离线任务都是非实时的,所有的ODPS表查询也都是非实时的,虽然SQL语句查询的方式很像实时数据库,但是你不能直接连接到ODPS进行业务数据实时展示,所以在流程的最后,我们一般需要放一个数据同步的节点,用来将运算完成的ODPS数据同步到自己的数据库中,进了自己数据库还不是任你揉捏~
进入到数加平台的“数据开发”模块,在左侧创建任务,此处我们选择工作流任务,便于理解整体的逻辑,以下是我的实现逻辑,不一定适合所有人,请自行调整(图片看不清请放大看):

格式化cdn日志,我是通过SQL语句结合一些小技巧来完成的,因为我们是一家to B的Saas服务商,所以在文件的存储上有自己的规律,比如:
http://www.xxx.com/client123/logo.png
http://www.xxx.com/client999/logo.png
分别代表了两个客户的文件URL,我们需要通过字符串切割,把客户标识找出来,也就是连接中 client123和client999 这一部分。
以下是我的SQL语句:
ALTER TABLE cdn_logs_format DROP if exists PARTITION (log_date='${bdp.system.bizdate}');
INSERT into TABLE cdn_logs_format PARTITION (log_date='${bdp.system.bizdate}')
SELECT unix_time
, TOLOWER(split_part(uri, '/', 2)) AS uri_parent
, method, procotol, domain, uri, return_code
, rt, response_size, client_ip, remote_address, bacend_server
, refer_domain, refer_uri, content_type, user_agent
FROM cdn_logs
WHERE log_date = '${bdp.system.bizdate}'
上面的语句中,最核心的其实就3个部分。
第一部分是维护cdn_logs_format表的特定分区,判断是否存在脏数据,如果存在,删除掉这个分区的内容。${bdp.system.bizdate}这个是内置变量,最终运行时会被替换为日期。
第二部分是通过split_part方法切割出url中的第一级目录,也就是我们业务中的客户标识部分。
第三部分是把查询到的内容INSERT into到cdn_logs_format表中。
在完成了基础日志的格式化之后,我们需要对同一个客户的访问请求进行合并汇总,需要用到下面的SQL语句:
ALTER TABLE aggr_product_traffic DROP IF EXISTS PARTITION (product = 'emp', aggr_date = '${bdp.system.bizdate}');
INSERT INTO TABLE aggr_product_traffic PARTITION (product = 'emp', aggr_date = '${bdp.system.bizdate}')
SELECT uri_parent AS clientcode
, datepart(TO_DATE(log_date, 'yyyymmdd'), 'yyyy') AS year
, datepart(TO_DATE(log_date, 'yyyymmdd'), 'mm') AS month
, datepart(TO_DATE(log_date, 'yyyymmdd'), 'dd') AS day
, datepart(TO_DATE(log_date, 'yyyymmdd'), 'hh') AS hour
, datepart(TO_DATE(log_date, 'yyyymmdd'), 'mi') AS mi
, SUM(response_size) AS traffic
, UNIX_TIMESTAMP(TO_DATE('${bdp.system.bizdate}', 'yyyymmdd')) AS create_at
, to_char(TO_DATE('${bdp.system.bizdate}', 'yyyymmdd'), 'yyyy-mm-dd') AS targetdate
FROM cdn_logs_format
WHERE log_date = '${bdp.system.bizdate}'
GROUP BY uri_parent,log_date
上面的语句中,核心其实就是group by + sum方法,做过关系型数据库开发的同学一定很熟悉,我也就不赘述了。
至此我们就通过2个任务分别完成了基础日志的处理及流量数据的合并汇总。
五、运算结果同步到自有数据库
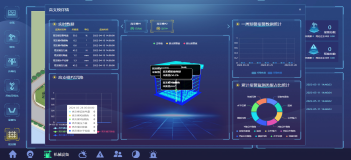
这一步就不截图展示了,很简单,配置好数据源,一一对应数据库字段即可,傻瓜操作,so easy!然后找你的开发同学做个好看的图表,出来后,你的客户看到的就是这个效果:

六、后记
因为只是偏场景方向的某一个侧重点展示,所以对经常使用数加平台的同学来说这个可能太浅了,帮助不大。但是对未接触过数加产品的同学来说,其实数加有好多产品都挺有意思的,只不过因为大数据这一块因为大家领域、场景重叠的少导致分享的东西很难产生共鸣。
不得不说,阿里云的大数据产品真的做的还不错,开箱即用,如果大家感兴趣的,后面也会写几篇阿里云机器学习方面的分享。
博客原文链接:http://qipangzi.com
钉钉群名称: [Aliyun用户]日志服务-SLS / 群号: 11775223
钉钉群名称: 数加·DataWorks交流群001 / 群号: 11718465
在评论区发表:优质评论/大数据讨论/阿里数加平台建议,将会得到阿里云定制雨伞1把,只有3把,先到先得!