标签
PostgreSQL , HTAP , OLTP , OLAP , 场景与性能测试
背景
PostgreSQL是一个历史悠久的数据库,历史可以追溯到1973年,最早由2014计算机图灵奖得主,关系数据库的鼻祖Michael_Stonebraker 操刀设计,PostgreSQL具备与Oracle类似的功能、性能、架构以及稳定性。

PostgreSQL社区的贡献者众多,来自全球各个行业,历经数年,PostgreSQL 每年发布一个大版本,以持久的生命力和稳定性著称。
2017年10月,PostgreSQL 推出10 版本,携带诸多惊天特性,目标是胜任OLAP和OLTP的HTAP混合场景的需求:
《最受开发者欢迎的HTAP数据库PostgreSQL 10特性》
1、多核并行增强
2、fdw 聚合下推
3、逻辑订阅
4、分区
5、金融级多副本
6、json、jsonb全文检索
7、还有插件化形式存在的特性,如 向量计算、JIT、SQL图计算、SQL流计算、分布式并行计算、时序处理、基因测序、化学分析、图像分析 等。

在各种应用场景中都可以看到PostgreSQL的应用:

PostgreSQL近年来的发展非常迅猛,从知名数据库评测网站dbranking的数据库评分趋势,可以看到PostgreSQL向上发展的趋势:

从每年PostgreSQL中国召开的社区会议,也能看到同样的趋势,参与的公司越来越多,分享的公司越来越多,分享的主题越来越丰富,横跨了 传统企业、互联网、医疗、金融、国企、物流、电商、社交、车联网、共享XX、云、游戏、公共交通、航空、铁路、军工、培训、咨询服务等 行业。
接下来的一系列文章,将给大家介绍PostgreSQL的各种应用场景以及对应的性能指标。
环境
环境部署方法参考:
《PostgreSQL 10 + PostGIS + Sharding(pg_pathman) + MySQL(fdw外部表) on ECS 部署指南(适合新用户)》
阿里云 ECS:56核,224G,1.5TB*2 SSD云盘。
操作系统:CentOS 7.4 x64
数据库版本:PostgreSQL 10
PS:ECS的CPU和IO性能相比物理机会打一定的折扣,可以按下降1倍性能来估算。跑物理主机可以按这里测试的性能乘以2来估算。
场景 - 字符串搜索 - 相似查询 (OLTP)
1、背景
字符串搜索是非常常见的业务需求,它包括:
1、前缀+模糊查询。(可以使用b-tree索引)
2、后缀+模糊查询。(可以使用b-tree索引)
3、前后模糊查询。(可以使用pg_trgm和gin索引)
https://www.postgresql.org/docs/10/static/pgtrgm.html
4、全文检索。(可以使用全文检索类型以及gin或rum索引)
5、正则查询。(可以使用pg_trgm和gin索引)
6、相似查询。(可以使用pg_trgm和gin索引)
通常来说,数据库并不具备3以后的加速能力,但是PostgreSQL的功能非常强大,它可以非常完美的支持这类查询的加速。(是指查询和写入不冲突的,并且索引BUILD是实时的。)
用户完全不需要将数据同步到搜索引擎,再来查询,而且搜索引擎也只能做到全文检索,并不你做到正则、相似、前后模糊这几个需求。
使用PostgreSQL可以大幅度的简化用户的架构,开发成本,同时保证数据查询的绝对实时性。
2、设计
1亿条文本,每一条长度为128个中文字符的随机串。按随机提供的字符串进行相似查询。
相似查询解决的是模糊查询、全文检索都不能解决的问题,例如业务要求 PostgreSQL,可以与p0stgresl 匹配。因为它们有足够的相似度。
https://www.postgresql.org/docs/10/static/pgtrgm.html
《PostgreSQL 文本数据分析实践之 - 相似度分析》
《17种文本相似算法与GIN索引 - pg_similarity》
《从相似度算法谈起 - Effective similarity search in PostgreSQL》
《聊一聊双十一背后的技术 - 毫秒分词算啥, 试试正则和相似度》
类似的应用还有图像相似搜索:
《(AR虚拟现实)红包 技术思考 - GIS与图像识别的完美结合》
《PostgreSQL 在视频、图片去重,图像搜索业务中的应用》
《弱水三千,只取一瓢,当图像搜索遇见PostgreSQL(Haar wavelet)》
3、准备测试表
create extension pg_trgm;
create table t_likeall (
id int,
info text
);
create index idx_t_likeall_1 on t_likeall using gin (info gin_trgm_ops);
-- 设置相似度阈值(0-1,浮点)
-- select set_limit(0.7);
-- 查询超过相似阈值的记录
-- SELECT info, similarity(info, '字符串') AS sml
-- FROM t_likeall
-- WHERE info % '字符串' -- 查找超过相似阈值的记录
-- ORDER BY sml DESC;
4、准备测试函数(可选)
-- 生成随机汉字符串
create or replace function gen_hanzi(int) returns text as $$
declare
res text;
begin
if $1 >=1 then
select string_agg(chr(19968+(random()*20901)::int), '') into res from generate_series(1,$1);
return res;
end if;
return null;
end;
$$ language plpgsql strict;
-- 使用随机字符串like查询(用于压测)
create or replace function get_t_likeall_test(int, real) returns setof record as
$$
declare
str text;
begin
-- 选择一个输入字符串
select info into str from t_likeall_test where id=$1;
-- 设置相似度阈值
perform set_limit($2);
-- 查找超过相似阈值的记录
return query execute 'select *, '''||str||''' as str, similarity(info, '''||str||''') as sml from t_likeall where info % '''||str||''' order by sml DESC limit 1';
end;
$$ language plpgsql strict;
5、准备测试数据
insert into t_likeall select id, gen_hanzi(128) from generate_series(1,100000000) t(id);
生成200万随机字符串,并加入一些噪音干扰,达到相似查询的目的。
create table t_likeall_test (id serial primary key, info text);
-- 截取任意位置开始的120个中文字符, 追加6个干扰字符,200万条
insert into t_likeall_test (info) select substring(info, (random()*10)::int, 120)||gen_hanzi(6) from t_likeall limit 2000000;
6、准备测试脚本
vi test.sql
\set id random(1,2000000)
select * from get_t_likeall_test(:id, 0.855) as t(id int , info text, str text, sml real);
7、测试
单次相似查询效率,响应时间低于20毫秒。(使用绑定变量、并且CACHE命中后,响应时间更低。)
postgres=# select * from get_t_likeall_test(2, 0.855) as t(id int , info text, str text, sml real);
-[ RECORD 1 ]----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
id | 2
info | 廮饓紡冮竊窔靉許訓寫黅噴贝嶸訐殿談暃涜魢劽刱酒戉磝遊瓈惝诪馈撋鳘錶鎭仠湛溜頪壨変呰堇慾鎍枿鶎徧勡摬罃亝椩荴釯紳岬芔剕澉滙鷞蘕氌酯稜泭急骸敲欍吜毢甕枚忊軔斃煱鎴篯儏鑑霘蚃蚜璥锰榋磻攔詥眳鴩囌棽瞠疹笣犳贪頰磏奧涠鉩欱峎塇躣僝蘵醲霯綨碐縦动減馱綢蔯葱唱芳贽瀮媮捐
str | 竊窔靉許訓寫黅噴贝嶸訐殿談暃涜魢劽刱酒戉磝遊瓈惝诪馈撋鳘錶鎭仠湛溜頪壨変呰堇慾鎍枿鶎徧勡摬罃亝椩荴釯紳岬芔剕澉滙鷞蘕氌酯稜泭急骸敲欍吜毢甕枚忊軔斃煱鎴篯儏鑑霘蚃蚜璥锰榋磻攔詥眳鴩囌棽瞠疹笣犳贪頰磏奧涠鉩欱峎塇躣僝蘵醲霯綨碐縦动減馱綢蔯葱唱芳迦摅羹帉胕谝
sml | 0.855072
Time: 19.455 ms
压测
CONNECTS=56
TIMES=300
export PGHOST=$PGDATA
export PGPORT=1999
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
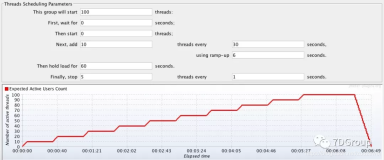
pgbench -M prepared -n -r -f ./test.sql -P 5 -c $CONNECTS -j $CONNECTS -T $TIMES
8、测试结果
transaction type: ./test.sql
scaling factor: 1
query mode: prepared
number of clients: 56
number of threads: 56
duration: 300 s
number of transactions actually processed: 459463
latency average = 36.562 ms
latency stddev = 8.063 ms
tps = 1531.259508 (including connections establishing)
tps = 1531.422742 (excluding connections establishing)
script statistics:
- statement latencies in milliseconds:
0.002 \set id random(1,2000000)
36.565 select * from get_t_likeall_test(:id, 0.855) as t(id int , info text, str text, sml real);
TPS: 1531
平均响应时间: 36.562 毫秒
参考
《PostgreSQL、Greenplum 应用案例宝典《如来神掌》 - 目录》