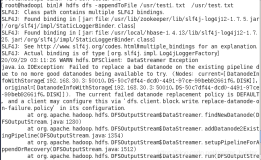
Hbase依赖的datanode日志中如果出现如下报错信息:DataXceiverjava.io.EOFException:
INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Exception in receiveBlock for block
解决办法:Hbase侧配置的dfs.socket.timeout值过小,与DataNode侧配置的 dfs.socket.timeout的配置不一致,将hbase和datanode的该配置调成大并一致。