使用kafka做消息队列中间件时,为了实时监控其性能时,免不了要使用jmx调取kafka broker的内部数据,不管是自己重新做一个kafka集群的监控系统,还是使用一些开源的产品,比如yahoo的kafka manager, 其都需要使用jmx来监控一些敏感的数据。在kafka官网中 http://kafka.apache.org/082/documentation.html#monitoring 这样说:
Kafka uses Yammer Metrics for metrics reporting in both the server and the client. This can be configured to report stats using pluggable stats reporters to hook up to your monitoring system.
The easiest way to see the available metrics to fire up jconsole and point it at a running kafka client or server; this will all browsing all metrics with JMX.
可见kafka官方也是提倡使用jmx并且提供了jmx的调用给用户以监控kafka.
本博文通过使用jmx调用kafka的几个监测项属性来讲述下如何使用jmx来监控kafka.
有关Jmx的使用可以参考:
- 从零开始玩转JMX(一)——简介和Standard MBean
- 从零开始玩转JMX(二)——Condition
- 从零开始玩转JMX(三)——Model MBean
- 从零开始玩转JMX(四)——Apache Commons Modeler & Dynamic MBean
在使用jmx之前需要确保kafka开启了jmx监控,kafka启动时要添加JMX_PORT=9999这一项,也就是:
JMX_PORT=9999 bin/kafka-server-start.sh config/server.properties &博主自行搭建了一个kafka集群,只有两个节点。集群中有一个topic(name=default_channel_kafka_zzh_demo),分为5个partition(0 1 2 3 4).
这里讨论的kafka版本是0.8.1.x和0.8.2.x,这两者在使用jmx监控时会有差异,差异体现在ObjectName之中。熟悉kafka的同学知道,kafka有topic和partition这两个概念,topic中根据一定的策略来分为若干个partitions, 这里就以此举例来看,
在0.8.1.x中有关此项的属性的ObjectName(String值)为:
“kafka.log”:type=”Log”,name=”default_channel_kafka_zzh_demo-*-LogEndOffset”
而在0.8.2.x中有关的属性的ObjectName为:
kafka.log:type=Log,name=LogEndOffset,topic=default_channel_kafka_zzh_demo,partition=0
所以在程序中要区别对待。
这里采用三个监测项来演示如果使用jmx进行监控:
- 上面所说的offset (集群中的一个topic下的所有partition的LogEndOffset值,即logSize)
- sendCount(集群中的一个topic下的发送总量,这个值是集群中每个broker中此topic的发送量之和)
- sendTps(集群中的一个topic下的TPS, 这个值也是集群中每个broker中此topic的发送量之和)
首先是针对单个kafka broker的。
package kafka.jmx;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import javax.management.*;
import javax.management.remote.JMXConnector;
import javax.management.remote.JMXConnectorFactory;
import javax.management.remote.JMXServiceURL;
import java.io.IOException;
import java.net.MalformedURLException;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* Created by hidden on 2016/12/8.
*/
public class JmxConnection {
private static Logger log = LoggerFactory.getLogger(JmxConnection.class);
private MBeanServerConnection conn;
private String jmxURL;
private String ipAndPort = "localhost:9999";
private int port = 9999;
private boolean newKafkaVersion = false;
public JmxConnection(Boolean newKafkaVersion, String ipAndPort){
this.newKafkaVersion = newKafkaVersion;
this.ipAndPort = ipAndPort;
}
public boolean init(){
jmxURL = "service:jmx:rmi:///jndi/rmi://" +ipAndPort+ "/jmxrmi";
log.info("init jmx, jmxUrl: {}, and begin to connect it",jmxURL);
try {
JMXServiceURL serviceURL = new JMXServiceURL(jmxURL);
JMXConnector connector = JMXConnectorFactory.connect(serviceURL,null);
conn = connector.getMBeanServerConnection();
if(conn == null){
log.error("get connection return null!");
return false;
}
} catch (MalformedURLException e) {
e.printStackTrace();
return false;
} catch (IOException e) {
e.printStackTrace();
return false;
}
return true;
}
public String getTopicName(String topicName){
String s;
if (newKafkaVersion) {
s = "kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec,topic=" + topicName;
} else {
s = "\"kafka.server\":type=\"BrokerTopicMetrics\",name=\"" + topicName + "-MessagesInPerSec\"";
}
return s;
}
/**
* @param topicName: topic name, default_channel_kafka_zzh_demo
* @return 获取发送量(单个broker的,要计算某个topic的总的发送量就要计算集群中每一个broker之和)
*/
public long getMsgInCountPerSec(String topicName){
String objectName = getTopicName(topicName);
Object val = getAttribute(objectName,"Count");
String debugInfo = "jmxUrl:"+jmxURL+",objectName="+objectName;
if(val !=null){
log.info("{}, Count:{}",debugInfo,(long)val);
return (long)val;
}
return 0;
}
/**
* @param topicName: topic name, default_channel_kafka_zzh_demo
* @return 获取发送的tps,和发送量一样如果要计算某个topic的发送量就需要计算集群中每一个broker中此topic的tps之和。
*/
public double getMsgInTpsPerSec(String topicName){
String objectName = getTopicName(topicName);
Object val = getAttribute(objectName,"OneMinuteRate");
if(val !=null){
double dVal = ((Double)val).doubleValue();
return dVal;
}
return 0;
}
private Object getAttribute(String objName, String objAttr)
{
ObjectName objectName =null;
try {
objectName = new ObjectName(objName);
} catch (MalformedObjectNameException e) {
e.printStackTrace();
return null;
}
return getAttribute(objectName,objAttr);
}
private Object getAttribute(ObjectName objName, String objAttr){
if(conn== null)
{
log.error("jmx connection is null");
return null;
}
try {
return conn.getAttribute(objName,objAttr);
} catch (MBeanException e) {
e.printStackTrace();
return null;
} catch (AttributeNotFoundException e) {
e.printStackTrace();
return null;
} catch (InstanceNotFoundException e) {
e.printStackTrace();
return null;
} catch (ReflectionException e) {
e.printStackTrace();
return null;
} catch (IOException e) {
e.printStackTrace();
return null;
}
}
/**
* @param topicName
* @return 获取topicName中每个partition所对应的logSize(即offset)
*/
public Map<Integer,Long> getTopicEndOffset(String topicName){
Set<ObjectName> objs = getEndOffsetObjects(topicName);
if(objs == null){
return null;
}
Map<Integer, Long> map = new HashMap<>();
for(ObjectName objName:objs){
int partId = getParId(objName);
Object val = getAttribute(objName,"Value");
if(val !=null){
map.put(partId,(Long)val);
}
}
return map;
}
private int getParId(ObjectName objName){
if(newKafkaVersion){
String s = objName.getKeyProperty("partition");
return Integer.parseInt(s);
}else {
String s = objName.getKeyProperty("name");
int to = s.lastIndexOf("-LogEndOffset");
String s1 = s.substring(0, to);
int from = s1.lastIndexOf("-") + 1;
String ss = s.substring(from, to);
return Integer.parseInt(ss);
}
}
private Set<ObjectName> getEndOffsetObjects(String topicName){
String objectName;
if (newKafkaVersion) {
objectName = "kafka.log:type=Log,name=LogEndOffset,topic="+topicName+",partition=*";
}else{
objectName = "\"kafka.log\":type=\"Log\",name=\"" + topicName + "-*-LogEndOffset\"";
}
ObjectName objName = null;
Set<ObjectName> objectNames = null;
try {
objName = new ObjectName(objectName);
objectNames = conn.queryNames(objName,null);
} catch (MalformedObjectNameException e) {
e.printStackTrace();
return null;
} catch (IOException e) {
e.printStackTrace();
return null;
}
return objectNames;
}
}注意代码中对于两种不同kafka版本的区别处理。对应前面所说的三个检测项的方法为:
public Map<Integer,Long> getTopicEndOffset(String topicName)
public long getMsgInCountPerSec(String topicName)
public double getMsgInTpsPerSec(String topicName)对于整个集群的处理需要另外一个类来保证,总体上是对集群中的每一个broker相应的值进行累加,且看代码:
package kafka.jmx;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* Created by hidden on 2016/12/8.
*/
public class JmxMgr {
private static Logger log = LoggerFactory.getLogger(JmxMgr.class);
private static List<JmxConnection> conns = new ArrayList<>();
public static boolean init(List<String> ipPortList, boolean newKafkaVersion){
for(String ipPort:ipPortList){
log.info("init jmxConnection [{}]",ipPort);
JmxConnection conn = new JmxConnection(newKafkaVersion, ipPort);
boolean bRet = conn.init();
if(!bRet){
log.error("init jmxConnection error");
return false;
}
conns.add(conn);
}
return true;
}
public static long getMsgInCountPerSec(String topicName){
long val = 0;
for(JmxConnection conn:conns){
long temp = conn.getMsgInCountPerSec(topicName);
val += temp;
}
return val;
}
public static double getMsgInTpsPerSec(String topicName){
double val = 0;
for(JmxConnection conn:conns){
double temp = conn.getMsgInTpsPerSec(topicName);
val += temp;
}
return val;
}
public static Map<Integer, Long> getEndOffset(String topicName){
Map<Integer,Long> map = new HashMap<>();
for(JmxConnection conn:conns){
Map<Integer,Long> tmp = conn.getTopicEndOffset(topicName);
if(tmp == null){
log.warn("get topic endoffset return null, topic {}", topicName);
continue;
}
for(Integer parId:tmp.keySet()){//change if bigger
if(!map.containsKey(parId) || (map.containsKey(parId) && (tmp.get(parId)>map.get(parId))) ){
map.put(parId, tmp.get(parId));
}
}
}
return map;
}
public static void main(String[] args) {
List<String> ipPortList = new ArrayList<>();
ipPortList.add("10.101.130.1:9999");
ipPortList.add("10.101.130.2:9999");
JmxMgr.init(ipPortList,true);
String topicName = "default_channel_kafka_zzh_demo";
System.out.println(getMsgInCountPerSec(topicName));
System.out.println(getMsgInTpsPerSec(topicName));
System.out.println(getEndOffset(topicName));
}
}运行结果:
2016-12-08 19:25:32 -[INFO] - [init jmxConnection [10.101.130.1:9999]] - [kafka.jmx.JmxMgr:20]
2016-12-08 19:25:32 -[INFO] - [init jmx, jmxUrl: service:jmx:rmi:///jndi/rmi://10.101.130.1:9999/jmxrmi, and begin to connect it] - [kafka.jmx.JmxConnection:35]
2016-12-08 19:25:33 -[INFO] - [init jmxConnection [10.101.130.2:9999]] - [kafka.jmx.JmxMgr:20]
2016-12-08 19:25:33 -[INFO] - [init jmx, jmxUrl: service:jmx:rmi:///jndi/rmi://10.101.130.2:9999/jmxrmi, and begin to connect it] - [kafka.jmx.JmxConnection:35]
2016-12-08 20:45:15 -[INFO] - [jmxUrl:service:jmx:rmi:///jndi/rmi://10.101.130.1:9999/jmxrmi,objectName=kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec,topic=default_channel_kafka_zzh_demo, Count:6000] - [kafka.jmx.JmxConnection:73]
2016-12-08 20:45:15 -[INFO] - [jmxUrl:service:jmx:rmi:///jndi/rmi://10.101.130.2:9999/jmxrmi,objectName=kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec,topic=default_channel_kafka_zzh_demo, Count:4384] - [kafka.jmx.JmxConnection:73]
10384
3.915592283987704E-65
{0=2072, 1=2084, 2=2073, 3=2083, 4=2072}观察运行结果可以发现 6000+4384 = 10384 = 2072+2084+2073+2083+2072,小伙伴们可以揣摩下原因。
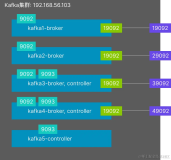
可以通过jconsole连接service:jmx:rmi:///jndi/rmi://10.101.130.1:9999/jmxrmi或者service:jmx:rmi:///jndi/rmi://10.101.130.2:9999/jmxrmi来查看相应的数据值。如下图:

也可以通过命令行的形式来查看某项数据,不过这里要借助一个jar包:cmdline-jmxclient-0.10.3.jar,这个请自行下载,网上很多。
将这个jar放入某一目录,博主这里放在了linux系统下的/root/util目录中,以offset举例:
0.8.1.x版-读取topic=default_channel_kafka_zzh_demo,partition=0的Value值:
java -jar cmdline-jmxclient-0.10.3.jar - 10.101.130.1:9999 '"kafka.log":type="Log",name="default_channel_kafka_zzh_demo-0-LogEndOffset"' Value0.8.2.x版-读取topic=default_channel_kafka_zzh_demo,partition=0的Value值:
java -jar cmdline-jmxclient-0.10.3.jar - 10.101.130.1:9999 kafka.log:type=Log,name=LogEndOffset,topic=default_channel_kafka_zzh_demo,partition=0看出规律了嘛?如果还是没有,博主再提示一个小技巧,你可以用Jconsole打开相应的属性,然后将鼠标浮于其上,Jconsole会跳出tooltips来提示怎么拼这些属性的ObjectName.