目录
**一.前言
二.原理
2.1 爬取流程
2.2 各部块的解释
2.3 scrapy数据流的分析三.理解
四.实战
4.1 首先是安装scrapy
4.2 建立项目和下载pycharm以及pycharm的配置
4.3 提取标题名和作者名
4.4 scrapy流程解析
4.5 小项目难度加深五.对scrapy建立项目的feedback
5.1 如何更快地找 bug
5.2 共存解释器可能导致的种种报错六.知识补充
6.1 Spider中的类和方法**
一. 前言
Scrapy是用于Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
有爬虫爱好者认为scrapy的优点是自定义程度高,适合学习研究爬虫技术,要学习的相关知识也较多,故而完成一个爬虫的时间较长。也有人表示,scrapy在python3上面无法运行,适用度没有想象的那么广阔。
网络爬虫通俗来说,就是一个在网上到处或定向抓取数据的程序,更专业的描述就是,抓取特定网站网页的HTML数据。抓取网页的一般方法是,定义一个入口页面,然后一般一个页面会有其他页面的URL,于是从当前页面获取到这些URL加入到爬虫的抓取队列中,然后进入到新页面后再递归的进行上述的操作。
二. 原理
Scrapy 使用 Twisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求。
在我们初次尝试去理解scrapy的结果和运行原理的时候,会用这样图表的介绍:
2.1 爬取流程
上图绿线是数据流向,首先从初始URL开始,Scheduler会将其交给Downloader进行下载,下载之后会交给Spider进行分析,Spider分析出来的结果有两种:一种是需要进一步抓取的链接,例如之前分析的“下一页”的链接,这些东西会被传回Scheduler;另一种是需要保存的数据,它们则被送到Item Pipeline那里,那是对数据进行后期处理(详细分析、过滤、存储等)的地方。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。
2.2 各部块的解释
- 引擎(Scrapy Engine):用来处理整个系统的数据流处理,触发事务。
- 调度器(Scheduler):用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。
- 下载器(Downloader):用于下载网页内容,并将网页内容返回给蜘蛛。
- 蜘蛛(Spiders):蜘蛛是主要干活的,用它来制订特定域名或网页的解析规则。编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
项目管道(Item Pipeline):负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
下载器中间件(Downloader Middlewares):位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 蜘蛛中间件(Spider Middlewares):介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件(Scheduler Middlewares):介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
2.3 scrapy数据流的分析
步骤如下:
STEP 1: 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
STEP 2: 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
STEP 3: 引擎向调度器请求下一个要爬取的URL。
STEP 4: 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
STEP 5: 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
STEP 6: 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
STEP 7: Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
STEP 8: 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
STEP 9: (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
引用出处:《学习Scrapy入门》
作者:JasonDing
链接:http://www.jianshu.com/p/a8aad3bf4dc4
三. 理解
当很多科普性的网站提起scrapy的时候,会介绍说scrapy是一个爬虫框架。框架的作用就是将重复性的工作做了封装。
举个例子,如果用linux系统处理一组数据需要四步,每一步都需要重新写命令行并且将会产生新的目录,中间还会需要等待的时间,这样的话处理这组数据耗时较长,并且你也可能忘记目录内对应存储的文件,最不便的是,当组里其他人需要相同处理其他数据的时候,又得重复你的工作,这样一来就产生了很多不必要的时间浪费。
然后,就有人想到把命令写在sh文件里直接执行,这样就省去了四步之间等待的时间,程序运行的时间没有变,但是把分散的过程变成了整体的过程,这样既提高了效率也避免了人长时间驻守在电脑前不断地输命令。
再然后,又有人在前人的sh文件基础上想到,能不能写一个框架,把数据来源,路径等不同用户存在差异的输入空出来,这样这个框架就可以供所有想要以同样方式处理类似数据的人使用了,也避免了大量重复写sh文件的时间。
基于这些想法,慢慢地就产生了框架。
框架,通俗来说,就是把相似过程的相同特征提取出来。
四. 实战
4.1 首先是安装scrapy
pip install scrapy
如果出现 Uninstalling six-1.4.1
则将命令改为:
sudo pip install Scrapy --upgrade --ignore-installed six
pip实际上是python的一个包管理工具,大多数时候在下载python时手动安装,pip可以运行在Unix/linux,OS X, and Windows平台上,可以通过pip下载python中需要的模块(module)和包。
确认scrapy是否安装成功
scrapy version
安装成功的显示应该是这样:

- 在mac上常见的问题是“动态模块中没有定义初始化函数”

ImportError: dynamic module does not define init function (init_openssl)
解决方法:
出现这个问题最可能的原因是python是32bit,而电脑属于64bit。
如何检查python版本呢和电脑的操作系统位数呢?
uname -a
可以获取电脑操作系统的信息
import platform
platform.architecture()
可以知道当前python的版本情况,示例如下:

在这里推荐一篇博客《OSX 上安装 Scrapy 的那些坑》(http://www.cnblogs.com/Ray-liang/p/4962988.html)
4.2 建立项目和下载pycharm以及pycharm的配置
在这里选用经典的“爬取豆瓣9分书单”的例子,豆瓣书单链接:https://www.douban.com/doulist/1264675/
4.2.1 建立项目
首先在终端中输入命令 :
scrapy startproject book
成功建立的话会出现:
New Scrapy project 'book', using template directory '/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/scrapy/templates/project', created in:
/Users/wuxinyao/Desktop/book
You can start your first spider with:
cd book
scrapy genspider example example.com
此时你返回建立的目录下是可以看见生成了个叫book的目录,进入目录后用命令行建立最主要的爬虫python文件,例子中命名为douban。指令:
scrapy genspider douban https://www.douban.com/doulist/1264675/
上面的那个网址就是爬虫所针对的网址
成功后会显示如下代码:
Created spider 'douban' using template 'basic' in module:
book.spiders.douban
4.2.2 用pycharm进行下一步操作
pycharm的下载网址 :http://www.jetbrains.com/pycharm/download/#section=mac
- 建立main文件
必须在book主目录下建立main.py,也就是说保证main.py和自动生成的scrapy.cfg在同一层。
在main.py中输入:
from scrapy import cmdline
cmdline.execute("scrapy crawl douban”.split())
- 修改douban.py
在spiders目录下找到douban.py,注释掉#allowed_domains = [‘https://www.douban.com/doulist/1264675/'],并把函数改成如下:
def parse(self, response):
print response.body

- 添加
在setting.py里添加:
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0'
4.2.3 常见问题:下载的scrapy的包无法导入
unresolved reference ‘scrapy’
并且由于pycharm的权限问题,可能不能直接在IDE上下载scrapy。所以会反复报错。出现这个问题有以下几种解决办法:
再次尝试在IDE上下载scrapy
file ——>default settings —-> Project Interpreter
选择一个解释器版本,点左下角的加号,在新弹出的界面中搜索scrapy,点击install,即可下载。
project interpreter的意思是解释器,mac电脑是自带python,但是可能种种原因很多人会选择下载新的python(例如操作系统的位数想从32位改成64位),并且储存在了不同的路径。而且mac自带的python在引入新的包的时候,很容易出现权限问题,所以mac用户常常有多个python解释器共存的情况。
在这个界面你就可以选择你想用的解释器:

这样做也不一定能解决问题,下载失败的原因有很多种,例如权限原因,或者是scrapy下载所需的某个包的版本不够新。它相当于在终端中运行:pip install scrapy的命令。
即使下载成功,也不一定能成功跑出来。不过这是相对来说最简单的解决方法,可以试试。
- 重新编辑路径
run —>Edit Configuration

script里面写main.py的绝对路径,python interpreter里面选择你想用的解释器的版本。
如果你的scrapy可以在终端运行的话,你可以用 which scrapy查找一下scrapy的位置,然后选择路径相近的python版本。或者用which python找一下正在工作的python的绝对路径,选择该版本的解释器。
成功执行的输出结果:

最前面几行是这个样子,相当于扒下了网站的源码。其实用浏览器查一下网站的源码,显示的是相同的结果。
4.3 提取标题名和作者名
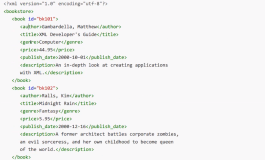
首先得观察网站的源代码:

发现在
参考原作者的写法,提取顺序如下:
- 提取大框架 :
- 提取作者:'
(.*?)
- 提取得分:’div[@class="rating"]/span[@class="rating_nums"]/text()'
原作者 voidsky_很有趣儿(via 豆瓣)提供了这样一段代码:
selector = scrapy.Selector(response)
books = selector.xpath('//div[@class="bd doulist-subject"]')
for each in books:
title = each.xpath('div[@class="title"]/a/text()').extract()[0]
rate = each.xpath('div[@class="rating"]/span[@class="rating_nums"]/text()').extract()[0]
author = re.search('<div>(.*?)<br',each.extract(),re.S).group(1)
print '标题:' + title
print '评分:' + rate
print author
print ''
引用出处:《scrapy安装与真的快速上手——爬取豆瓣9分榜单》
作者:voidsky_很有趣儿
链接:http://www.jianshu.com/p/fa614bea98eb
这段代码用到了xpath,XPath 是一门在 XML 文档中查找信息的语言,但它也可以用在HTML中。获取大部分标签的内容不需要编写复杂的正则表达式,可以直接使用xpath。 下表列出了常用表达式:

这段代码加在之前的douban.py中的函数parse(self,response)下面,把之前的 “print response.body”注释掉,直接加上这段。
4.4 scrapy流程解析
其实写到这里,一个完整的小程序就已经成型了,输出的结果应该是:

但是很可能第一遍程序无法得出这样的结果,而出现了各种各样的错误,然而在debug的时候却可以看到一些有助于帮助理解scrapy结构的东西:
2017-07-20 xx:50:53 [scrapy.middleware] INFO: Enabled extensions:
……
2017-07-20 20:50:53 [scrapy.middleware] INFO: Enabled downloader middlewares
……
2017-07-20 20:50:53 [scrapy.middleware] INFO: Enabled spider middlewares:
……
2017-07-20 20:50:53 [scrapy.middleware] INFO: Enabled item pipelines:
……
2017-07-20 20:50:53 [scrapy.core.engine] INFO: Spider opened
……
2017-07-20 20:50:54 [scrapy.core.engine] INFO: Spider closed (finished)
……
可能出现的问题:
如果没有得到上述的输出结果的话,仔细看一下跑出的代码,如果有这样一条:
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe6 in position 0: ordinal not in range(128)
说明python的str默认是ascii编码,和unicode编码冲突,于是就会报这个标题错误
只需要在main.py中加上:
import sys
reload(sys)
sys.setdefaultencoding(‘utf8')
就能将使问题得到解决。
4.5 小项目难度加深
上面的那个小项目仔细看看,item和pipline都没有涉及到,只是爬取了数据而并没有进行存储操作,scrapy的结构化的特点并没有完全的体现出来,下面将用另一个经典小项目对scrapy的结构功能进行更深一步的阐述。
4.5.1 对于第一步产生的目录子目录的解释:
输入命令:
scrapy startproject myproject
ls myproject
- scrapy.cfg: 项目配置文件
- /: 项目python模块, 之后您将在此加入代码
- myproject/items.py: 项目items文件
- myproject/pipelines.py: 项目管道文件
- myproject/settings.py: 项目配置文件
- myproject/spiders: 放置spider的目录
4.5.2 Item就像是python中的字典
从前面的内容可以知道, Item是装载数据的容器,我们需要将Item模型化来获取从站点抓取的数据。
scrapy中在Item的注释中已经注明了写法,最后写在自创的python文件中(如例一中的douban.py),可以实现抓取数据的存储。
在自创的python文件中(本例叫project.py),需要先导入item的那个函数
from project.py import MyprojectItem

4.5.3 setting中Feed输出的变量设置
在Item存储了抓取的数据后,如果想把它列成excel表格打印出的话,需要在settig.py中进行设置,加入以下两行:
FEED_FORMAT :指示输出格式,csv/xml/json/
FEED_URI : 指示输出位置,可以是本地,也可以是FTP服务器
例如:
FEED_URI = u'file:///G://dou.csv'
FEED_FORMAT = ‘CSV'
这样的话,输出的文件存在G盘,名字叫dou.csv,是一个csv文件。

五. 对scrapy建立项目的feedback
5.1 如何更快地找 bug
对于一个新手而言,学会用scrapy编写爬虫程序,困难更多在于对pycharm的配置和对正则表达式的适应,如果把完成这个项目分成很多逻辑板块的话,比较建议的是先理解scrapy的信息流和数据流,这样的话即使程序跑出bug(几率特别大)也能很快清楚问题在哪个文件里面。scrapy的console不是很适合调试bug,它并不会直接把key error显示出来,所以最好脑中能区分出上述那些功能板块,对应着去找bug。
5.2 共存解释器可能导致的种种报错
这篇文章的主要目的是介绍scrapy这个框架的使用,也着重讲述了在完成一个爬虫程序可能面临到的种种问题,包括电脑中存在多个python解释器时可能出现的各种报错,笔者最后总结:如果导入包的时候一直报错,就更改run/configuration里面的python解释器;如果在console一直报错,cannot connect to console,就重建project,选择usr/bin目录下的外部库。
六. 知识补充
6.1 Spider中的类和方法
- name:必须且唯一的spider名字,类型为string,运行该spider时输入它
- allow_domains:允许方法的域名,可以是string 或者list,可选项,非必须。
- start_urls: 指定要首先访问的url
- start_requests(): 默认从start_urls里面获取url,并且为每一个url产生一个request,默认的 callback为parse。调度就是从这里开始执行的。这里可以改写,以便从指定的url开始访问,一般用于模拟登陆时,获取动态code的时候。获取动态code那么你可以这样:
from scrapy.http import Request,FromRequest
start_requests():
return [ Request( url, mata={'cookiejar':1}callback=login ) ] #加入meta想要获取cookie
这里的url就是你登陆的login URL,访问这个url时,server会返回你一个response,这个response里面就有下一步登陆的时候要发送的code。那么这里的callback到login这个方法的功能就是要从返回的response里面通过正则表达式或者结合xpath等得到这个code。
start_requests中将Downloader下载的response返回给callback,也就是我定义的login方法,那么在login方法中,除了要解析并获得动态code外,还可以进行模拟登陆,在login中可以加入:
def login(self,response):
code=response.xpath('//h1/text()').extract() #就是为了获得code,也可以结合re来提取
headers={} #模拟浏览器登陆的header
postdata={} #server要你post的数据,包括上面获得的code
return [FormRequest.from_response( url, headers=headers, formdata=postdata, meta={'cookiejar':response.meta['cookiejar'], callback=loged , dont_filter=x } ) ]
#注意这里postdata并没有用urlencode,且cookie用的是返回的response中的cookie,也就是上面start_requests那里记录的cookie。另外此时的url则是你真正post数据的url,一般可以通过firebug获得。其实,这里也可以这个时候才获得cookie,这样可以获得登陆以后的cookie。这个方法被调用以后,就成功登陆了,那么此时可以在loged方法中通过下面make_requests_from_url这个方法来访问登陆以后的其他页面。
#这里如果需要输入验证码,可以采用下载图片并手动输入的方式进行,在另外一片记录里可以看到。
如果该方法被重写了,那么start_urls里面的url将不会被首先访问,后面想要访问的时候则要特别的“强调“。会在后面说明。
还要注意的是,start_requests只被自动调用一次。
make_requests_from_url(url):
这个方法就是当你指定了url的时候,则通过这个方法,可以自动返回给parse。scrapy中能够自动调用parse的方法,就我目前的学习来看,只有这两个(start_requests和make_requests_from_url)。这个之所以重要,是因为要结合后面说的CrawlSpider中的rule。
可以通过make_requests_from_url()来实现访问start_urls里面的url:
def loged(self, response):
for url in start_urls:
yield make_requests_from_url(url)
parse():
scrapy中默认将response传递到的地方就是parse(),这里顾名思义是用来提取网页内容的地方,在Spider类中可以在这里实现网页内容提取,但是在CralwSpider中,parse()实现用rule中获得的link进行进一步处理,所以在CrawlSpider中不建议重写parse方法。
rule():
rule提供了如何指导Downloader获取链接的的功能,其具体实现是:
from scrapy.linkextractors import LinkExtractor as LKE
引用作者:ChrisPop
链接:http://www.jianshu.com/p/a1018729d695
结语:选择用一个新的方法在刚开始起步的时候总是艰难的,适应一个新的软件也是充满bug的,只要熬过了开头的阶段,后面就会变得开阔和顺手起来。也祝福大家能通过scrapy做出越来越多的有趣且好玩的爬虫小程序!
原文发布时间为:2017-11-7
本文作者:邬欣尧
本文来自云栖社区合作伙伴“数据派THU”,了解相关信息可以关注“数据派THU”微信公众号