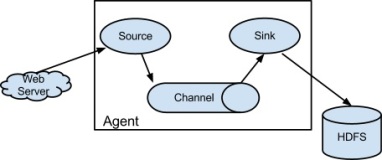
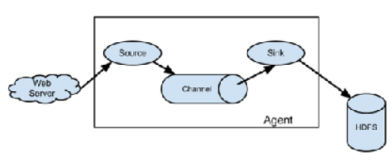
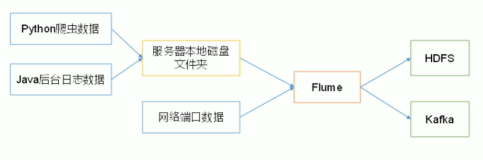
a1.sources = r1
a1.sinks = s1
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.bind =master
a1.sources.r1.port =8888
a1.sinks.s1.type = logger
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sinks.s1.channel = c1
a1.sources.r1.intercpetors=i1
a1.sources.r1.interceptors.i1.type=search_replace
a1.sources.r1.interceptors.i1.searchPattern=(\\d{3})\\d{4}(\\d{4})
a1.sources.r1.interceptors.i1.replaceString=$1xxxx$2
手机号码抹去中间四位
这个还需要java类去制造avro序列化的文件
package flumeTest;
import java.nio.charset.Charset;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import org.apache.flume.Event;
import org.apache.flume.api.RpcClient;
import org.apache.flume.api.RpcClientFactory;
import org.apache.flume.event.EventBuilder;
//链接avro的flume source 发送event 到flume agent
public class FlumeClient {
private RpcClient flumeClient;
private String hostName;
private int port;
public FlumeClient(String hostname,int port){
this.hostName =hostname;
this.port=port;
this.flumeClient=RpcClientFactory.getDefaultInstance(hostname, port);
}
//把字符串消息发送event到avro source
public void sendEvent(String msg){
Map<String, String> headers =new HashMap<String, String>();
headers.put("timestamp", String.valueOf(new Date().getTime()));
//构建event
Event event =EventBuilder.withBody(msg, Charset.forName("UTF-8"), headers);
try{
flumeClient.append(event);
}catch (Exception e) {
e.printStackTrace();
flumeClient.close();
flumeClient=null;
flumeClient=RpcClientFactory.getDefaultInstance(hostName, port);
}
}
public void close(){
flumeClient.close();
}
//这个类的作用就是向hostName的port端口输入Flume定义的RpcClient avro格式的内容
public static void main(String[] args) {
FlumeClient flumeClient =new FlumeClient("master", 8888);
String bMsg="fromjava-msg";
for(int i=0;i<100;i++){
flumeClient.sendEvent(bMsg+i);
}
flumeClient.close();
}
}
package flumeTest;
import java.util.Random;
public class SendPhoneNo {
public static void main(String[] args) {
FlumeClient flumeClient = new FlumeClient("master", 8888);
Random random = new Random();
for (int i = 0; i < 100; i++) {
String phoneNo = "1" + random.nextInt(10) + random.nextInt(10) + random.nextInt(10) + random.nextInt(10)
+ random.nextInt(10) + random.nextInt(10) + random.nextInt(10) + random.nextInt(10)
+ random.nextInt(10) + random.nextInt(10);
flumeClient.sendEvent(phoneNo);
}
flumeClient.close();
}
}
列子二
a1.sources=r1
a1.channels=c1 c2 c3 c4
a1.sinks=s1 s2 s3 s4
a1.sources.r1.type=avro
a1.sources.r1.bind=master
a1.sources.r1.port=8888
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.channels.c2.type=memory
a1.channels.c2.capacity=1000
a1.channels.c2.transactionCapacity=100
a1.channels.c3.type=memory
a1.channels.c3.capacity=1000
a1.channels.c3.transactionCapacity=100
a1.channels.c4.type=memory
a1.channels.c4.capacity=1000
a1.channels.c4.transactionCapacity=100
a1.sinks.s1.type=hdfs
a1.sinks.s1.hdfs.path=/flumelog/henan
a1.sinks.s1.hdfs.fileSuffix=.log
a1.sinks.s1.hdfs.filePrefix=test_log
a1.sinks.s1.hdfs.rollInterval=0
a1.sinks.s1.hdfs.rollSize=0
a1.sinks.s1.hdfs.fileType=DataStream
a1.sinks.s1.hdfs.writeFormat=Text
a1.sinks/s1.hdfs.userLocalTimeStamp=true
a1.sinks.s2.type=hdfs
a1.sinks.s2.hdfs.path=/flumelog/hebei
a1.sinks.s2.hdfs.fileSuffix=.log
a1.sinks.s2.hdfs.filePrefix=test_log
a1.sinks.s2.hdfs.rollInterval=0
a1.sinks.s2.hdfs.rollSize=0
a1.sinks.s2.hdfs.fileType=DataStream
a1.sinks.s2.hdfs.writeFormat=Text
a1.sinks/s2.hdfs.userLocalTimeStamp=true
这个conf是为了将events按照不同地区拦截写入到hdfs上的不同文件夹中 相当于按区归类处理source文件为avro所以写了一个java类来传送到master
package flumeTest;
//agent的slector 为multiplexing
//到event的header去匹配key为ptovince的value 然后发送到相应的channel中
import java.nio.charset.Charset;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
import org.apache.flume.Event;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.api.RpcClient;
import org.apache.flume.api.RpcClientFactory;
import org.apache.flume.event.EventBuilder;
public class ForFanoutSelectorClient {
private RpcClient client;
private final String[] provinces={"henan","hebei","shanghai","shandong"};
private final Random random =new Random();
public ForFanoutSelectorClient(String hostname,int port){
this.client=RpcClientFactory.getDefaultInstance(hostname, port);
}
public Event getRandomEvent(String msg){
Map<String,String> headers=new HashMap<String, String>();
String province =provinces[random.nextInt(4)];
headers.put("province", province);
Event result=EventBuilder.withBody(msg, Charset.forName("UTF-8"), headers);
return result;
}
public void sendEvent(Event event){
try {
client.append(event);
} catch (EventDeliveryException e) {
e.printStackTrace();
}
}
public void close(){
client.close();
}
public static void main(String[] args) {
ForFanoutSelectorClient fanoutSelectorClient =new ForFanoutSelectorClient("master", 8888);
String msg ="peopleinfo_";
for(int i=0;i<300;i++){
Event event =fanoutSelectorClient.getRandomEvent(msg+i+"_");
fanoutSelectorClient.sendEvent(event);
}
fanoutSelectorClient.close();
}
}
列子三
a1.sources = r1
a1.sinks = s1
a1.channels = c1
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir=/opt/spooldirnew
a1.sources.r1.fileHeader=true
a1.sinks.s1.type = logger
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sinks.s1.channel = c1
a1.sources.r1.interceptor=i1
a1.sources.r1.interceptor.i1.type=regex_filter
a1.sources.r1.interceptor.i1.regex=^[a-z0-9]+([._\\-]*[a-z0-9])*@([a-z0-9]+[-a-z0-9]*[a-z0-9]+.){1,63}[a-z0-9]+$
a1.sources.r1.interceptor.excludeEvents=false删选出在spooldirnew文件里面有关邮箱的event时间 输出在logger中
a1.sources=r1
a1.sinks=k1
a1.channels=c1
a1.sources.r1.type=spooldir
a1.sources.r1.spoolDir=/opt/spooldir
a1.sources.r1.fileHeader=true
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=/flumelog/%Y%m%d
a1.sinks.k1.hdfs.fileSuffix=.log
a1.simks.k1.hdfs.rollInterval=0
a1.sinks.k1.hdfs.roolSize=0
a1.sinks.k1.hdfs.roolCount=100
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=Text
a1.sinks.k1.hdfs.useLocalTimeStamp=true
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
这个conf是用来动态分布采集到的数据的
动态即按照年月日创建文件夹在集群上 需要注意的一点事得写userLocalTimeStamp=true 不然flume无法参照时间做事
a1.sources = r1
a1.sinks = s1
a1.channels = c1
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sinks.s1.type = logger
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sinks.s1.channel = c1
采集netcat类型的数据以日志形式展示 (官网例子)
a1.sources=r1
a1.sinkes=s1
a1.channels=c1
a1.sources.r1.type=avro
a1.sources.r1.bind=master
a1.sources.r1.port=8888
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sinks.s1.type=logger
a1.sources.r1.channels=c1
a1.sinks.s1.channel=c1
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=host
host拦截器 之前总结过 就是在header中添加host Ip
a1.sources= r1
a1.sinkes=s1 s2
a1.channels=c1 c2
a1.sources.r1.type=avro
a1.sources.r1.bind=master
a1.sources.r1.port=8888
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sinks.s1.type=logger
a1.sinks.s2.type=hdfs
a1.sinks.s2.hdfs.path=/flumelog/%Y%m%d
a1.sinks.s2.hdfs.fileSuffix=.log
a1.sinks.s2.hdfs.filePrefix=test_log
a1.sinks.s2.hdfs.rollInterval=0
a1.sinks.s2.hdfs.rollSize=0
a1.sinks.s2.hdfs.fileType=DataStream
a1.sinks.s2.hdfs.writeFormat=Text
a1.sinks/s2.hdfs.userLocalTimeStamp=true
a1.sources.r1.channels=c1 c2
a1.sinks.s1.channel=c1
a1.sinks.s2.channel=c2
多sinks和channels 一个用来输出到logger中 一个用于保存在hdfs上